Short-term Object Interaction Anticipation with Disentangled Object Detection @ Ego4D Short Term Object Interaction Anticipation Challenge

0

Sign in to get full access
Overview
- This paper presents a method for short-term object interaction anticipation, which aims to predict how objects will interact with each other in the near future based on visual information.
- The key contributions include a disentangled object detection approach and an attention-based model for reasoning about object interactions.
- The method is evaluated on the Ego4D Short Term Object Interaction Anticipation Challenge dataset.
Plain English Explanation
The paper discusses a system that can anticipate how objects will interact with each other in the near future, based on visual information. For example, the system might be able to predict that a person will pick up a cup or that a car will collide with a pedestrian.
This is an important capability for applications like robotics, autonomous vehicles, and augmented reality, where anticipating future object interactions can enable more effective planning and decision-making.
The system works by first detecting and classifying the objects in the scene using a disentangled object detection approach. This means the object detection is performed in a way that separates the visual appearance of the objects from their spatial relationships and interactions.
The system then uses an attention-based neural network model to reason about how the detected objects are likely to interact with each other in the near future. This attention-based approach allows the model to focus on the most relevant parts of the scene when making its predictions.
The paper evaluates the system's performance on a dataset called Ego4D, which contains videos of people performing everyday tasks and interactions. The results show that the system is able to accurately anticipate short-term object interactions, outperforming baseline methods.
Technical Explanation
The paper proposes a method for short-term object interaction anticipation that consists of two main components: a disentangled object detection module and an attention-based interaction reasoning module.
The disentangled object detection module aims to separate the visual appearance of objects from their spatial relationships and interactions. This is achieved by using a set of object-centric encoders that learn separate representations for an object's visual features, location, size, and orientation. These disentangled object representations are then fed into a detection head to produce bounding boxes and class labels for the objects in the scene.
The attention-based interaction reasoning module takes the disentangled object representations as input and uses a transformer-based architecture to model the relationships and potential interactions between the detected objects. The attention mechanism allows the model to focus on the most relevant objects and their spatial configurations when predicting future object interactions.
The proposed method is evaluated on the Ego4D Short Term Object Interaction Anticipation Challenge dataset, which contains egocentric videos of people performing everyday tasks and interactions. The results show that the disentangled object detection and attention-based interaction reasoning components together outperform baseline methods that use more traditional object detection and interaction modeling approaches.
Critical Analysis
The paper presents a well-designed and technically sound approach to the problem of short-term object interaction anticipation. The disentangled object detection module is a particularly novel and compelling aspect of the work, as it allows the system to better reason about the underlying object properties and relationships that are relevant for predicting future interactions.
One potential limitation of the approach is that it relies on a transformer-based architecture for the interaction reasoning module, which can be computationally intensive and may struggle with long-range dependencies or complex scene dynamics. It would be interesting to see how the method performs compared to alternative interaction modeling approaches, such as graph neural networks or object-centric action reasoning.
Additionally, the paper does not provide much insight into the types of object interactions the system is able to anticipate or the real-world applicability of the approach. Further analysis of the model's strengths, weaknesses, and failure cases could help readers better understand the capabilities and limitations of the proposed method.
Conclusion
Overall, this paper presents a novel and promising approach to the problem of short-term object interaction anticipation. The disentangled object detection and attention-based reasoning components work together to enable accurate predictions of how objects are likely to interact in the near future.
This capability could have important applications in areas such as robotics, autonomous vehicles, and augmented reality, where anticipating future object interactions can lead to more effective planning and decision-making. Further research and development in this area could help unlock new possibilities for intelligent systems that can better understand and navigate the dynamic world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Short-term Object Interaction Anticipation with Disentangled Object Detection @ Ego4D Short Term Object Interaction Anticipation Challenge
Hyunjin Cho, Dong Un Kang, Se Young Chun
Short-term object interaction anticipation is an important task in egocentric video analysis, including precise predictions of future interactions and their timings as well as the categories and positions of the involved active objects. To alleviate the complexity of this task, our proposed method, SOIA-DOD, effectively decompose it into 1) detecting active object and 2) classifying interaction and predicting their timing. Our method first detects all potential active objects in the last frame of egocentric video by fine-tuning a pre-trained YOLOv9. Then, we combine these potential active objects as query with transformer encoder, thereby identifying the most promising next active object and predicting its future interaction and time-to-contact. Experimental results demonstrate that our method outperforms state-of-the-art models on the challenge test set, achieving the best performance in predicting next active objects and their interactions. Finally, our proposed ranked the third overall top-5 mAP when including time-to-contact predictions. The source code is available at https://github.com/KeenyJin/SOIA-DOD.
Read more7/9/2024
0
ZARRIO @ Ego4D Short Term Object Interaction Anticipation Challenge: Leveraging Affordances and Attention-based models for STA
Lorenzo Mur-Labadia, Ruben Martinez-Cantin, Josechu Guerrero-Campo, Giovanni Maria Farinella
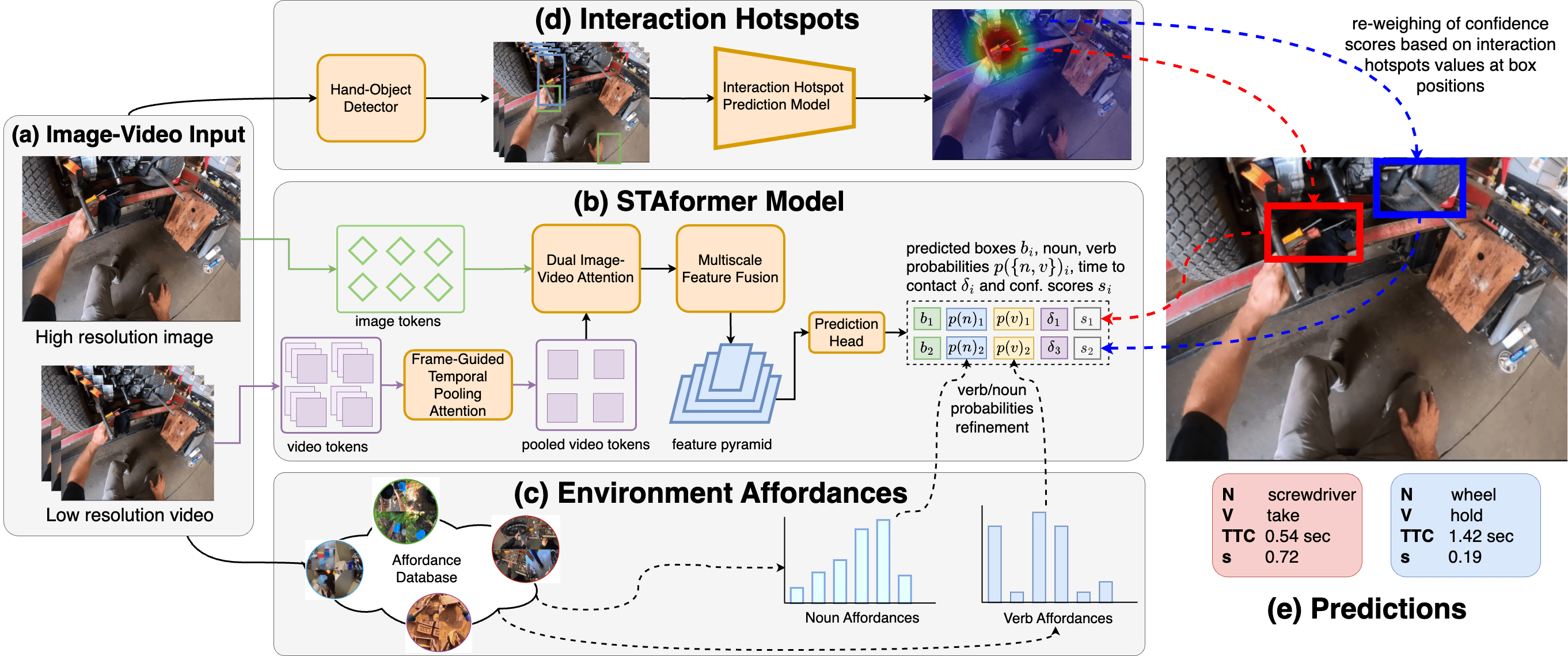
Short-Term object-interaction Anticipation (STA) consists of detecting the location of the next-active objects, the noun and verb categories of the interaction, and the time to contact from the observation of egocentric video. We propose STAformer, a novel attention-based architecture integrating frame-guided temporal pooling, dual image-video attention, and multi-scale feature fusion to support STA predictions from an image-input video pair. Moreover, we introduce two novel modules to ground STA predictions on human behavior by modeling affordances. First, we integrate an environment affordance model which acts as a persistent memory of interactions that can take place in a given physical scene. Second, we predict interaction hotspots from the observation of hands and object trajectories, increasing confidence in STA predictions localized around the hotspot. On the test set, our results obtain a final 33.5 N mAP, 17.25 N+V mAP, 11.77 N+{delta} mAP and 6.75 Overall top-5 mAP metric when trained on the v2 training dataset.
Read more7/8/2024

0
AFF-ttention! Affordances and Attention models for Short-Term Object Interaction Anticipation
Lorenzo Mur-Labadia, Ruben Martinez-Cantin, Josechu Guerrero, Giovanni Maria Farinella, Antonino Furnari
Short-Term object-interaction Anticipation consists of detecting the location of the next-active objects, the noun and verb categories of the interaction, and the time to contact from the observation of egocentric video. This ability is fundamental for wearable assistants or human robot interaction to understand the user goals, but there is still room for improvement to perform STA in a precise and reliable way. In this work, we improve the performance of STA predictions with two contributions: 1. We propose STAformer, a novel attention-based architecture integrating frame guided temporal pooling, dual image-video attention, and multiscale feature fusion to support STA predictions from an image-input video pair. 2. We introduce two novel modules to ground STA predictions on human behavior by modeling affordances.First, we integrate an environment affordance model which acts as a persistent memory of interactions that can take place in a given physical scene. Second, we predict interaction hotspots from the observation of hands and object trajectories, increasing confidence in STA predictions localized around the hotspot. Our results show significant relative Overall Top-5 mAP improvements of up to +45% on Ego4D and +42% on a novel set of curated EPIC-Kitchens STA labels. We will release the code, annotations, and pre extracted affordances on Ego4D and EPIC- Kitchens to encourage future research in this area.
Read more6/6/2024
🔎
0
Active Object Detection with Knowledge Aggregation and Distillation from Large Models
Dejie Yang, Yang Liu
Accurately detecting active objects undergoing state changes is essential for comprehending human interactions and facilitating decision-making. The existing methods for active object detection (AOD) primarily rely on visual appearance of the objects within input, such as changes in size, shape and relationship with hands. However, these visual changes can be subtle, posing challenges, particularly in scenarios with multiple distracting no-change instances of the same category. We observe that the state changes are often the result of an interaction being performed upon the object, thus propose to use informed priors about object related plausible interactions (including semantics and visual appearance) to provide more reliable cues for AOD. Specifically, we propose a knowledge aggregation procedure to integrate the aforementioned informed priors into oracle queries within the teacher decoder, offering more object affordance commonsense to locate the active object. To streamline the inference process and reduce extra knowledge inputs, we propose a knowledge distillation approach that encourages the student decoder to mimic the detection capabilities of the teacher decoder using the oracle query by replicating its predictions and attention. Our proposed framework achieves state-of-the-art performance on four datasets, namely Ego4D, Epic-Kitchens, MECCANO, and 100DOH, which demonstrates the effectiveness of our approach in improving AOD.
Read more5/22/2024