Shortcomings of LLMs for Low-Resource Translation: Retrieval and Understanding are Both the Problem
2406.15625
0
0
🤔
Abstract
This work investigates the in-context learning abilities of pretrained large language models (LLMs) when instructed to translate text from a low-resource language into a high-resource language as part of an automated machine translation pipeline. We conduct a set of experiments translating Southern Quechua to Spanish and examine the informativity of various types of information retrieved from a constrained database of digitized pedagogical materials (dictionaries and grammar lessons) and parallel corpora. Using both automatic and human evaluation of model output, we conduct ablation studies that manipulate (1) context type (morpheme translations, grammar descriptions, and corpus examples), (2) retrieval methods (automated vs. manual), and (3) model type. Our results suggest that even relatively small LLMs are capable of utilizing prompt context for zero-shot low-resource translation when provided a minimally sufficient amount of relevant linguistic information. However, the variable effects of prompt type, retrieval method, model type, and language-specific factors highlight the limitations of using even the best LLMs as translation systems for the majority of the world's 7,000+ languages and their speakers.
Create account to get full access
Overview
- This paper explores the limitations of large language models (LLMs) for low-resource machine translation tasks, where the availability of training data is limited.
- The researchers found that LLMs struggle with both retrieval and understanding when dealing with low-resource languages, leading to poor translation performance.
- The paper provides insights into the shortcomings of LLMs in this challenging scenario and suggests potential avenues for improvement.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, when it comes to translating between languages with limited training data, known as "low-resource" languages, these models have significant limitations.
The researchers found that LLMs struggle on two key fronts: retrieval and understanding. Retrieval refers to the model's ability to find relevant information to inform the translation, while understanding involves comprehending the meaning and context of the input text.
In low-resource scenarios, LLMs often fail to retrieve the necessary information to translate accurately, and they also struggle to fully understand the nuances of the source language. This results in poor-quality translations that fail to capture the intended meaning.
The paper provides insights into these challenges and suggests that addressing both retrieval and understanding is crucial for improving LLM performance in low-resource machine translation tasks. This is an important area of research, as many languages around the world have limited digital resources, and effective translation tools could have significant societal impact.
Technical Explanation
The researchers evaluated the performance of LLMs, specifically GPT-3 and T5, on a range of low-resource machine translation tasks. They found that these models struggled significantly, often producing inaccurate or nonsensical translations.
Through detailed analysis, the team identified two key factors contributing to the LLMs' shortcomings: retrieval and understanding. LLMs failed to effectively retrieve the necessary information to inform accurate translations, and they also struggled to comprehend the nuanced meaning of the source text, particularly in languages with limited available data.
The researchers experimented with various techniques, such as few-shot learning and cross-modal and cross-lingual approaches, to address these limitations. However, they found that these methods provided only modest improvements, suggesting that more fundamental advancements are needed to enable LLMs to excel in low-resource machine translation tasks.
The findings of this study highlight the need for further research to enhance the retrieval and understanding capabilities of LLMs, particularly in the context of multilingual and low-resource machine translation scenarios.
Critical Analysis
The paper provides a comprehensive and insightful analysis of the limitations of LLMs in low-resource machine translation tasks. The researchers have identified the core challenges of retrieval and understanding, which are crucial for effective translation, and have explored various techniques to address these issues.
While the researchers' experiments with few-shot learning and cross-modal/cross-lingual approaches yielded some improvements, the overall performance of the LLMs remained unsatisfactory. This suggests that more fundamental advancements are needed to truly enable LLMs to excel in this domain.
One potential area for further research could be exploring hybrid systems that combine the strengths of LLMs with other techniques, such as knowledge-rich approaches or task-specific architectures. Additionally, investigating novel training strategies or data augmentation methods tailored to low-resource scenarios may help to overcome the limitations identified in this paper.
It is also worth noting that the paper focused on a limited set of language pairs and translation tasks. Expanding the scope of the evaluation to a wider range of low-resource languages and translation scenarios could provide a more comprehensive understanding of the LLMs' shortcomings and guide future research directions.
Conclusion
This paper offers a compelling and detailed exploration of the limitations of large language models (LLMs) in the context of low-resource machine translation tasks. The researchers have identified the core challenges of retrieval and understanding as the primary factors contributing to the poor performance of LLMs in these scenarios.
The insights gained from this study highlight the need for further advancements in the field of low-resource machine translation, where effective translation tools could have significant societal impact, particularly for underserved language communities. The findings suggest that addressing both the retrieval and understanding capabilities of LLMs is crucial for improving their performance in these challenging tasks.
As the field of natural language processing continues to evolve, the insights provided in this paper serve as a valuable reference for researchers and developers working towards more robust and inclusive translation systems that can cater to the diverse language needs of the global community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Low-Resource Machine Translation through Retrieval-Augmented LLM Prompting: A Study on the Mambai Language
Raphael Merx, Aso Mahmudi, Katrina Langford, Leo Alberto de Araujo, Ekaterina Vylomova
0
0
This study explores the use of large language models (LLMs) for translating English into Mambai, a low-resource Austronesian language spoken in Timor-Leste, with approximately 200,000 native speakers. Leveraging a novel corpus derived from a Mambai language manual and additional sentences translated by a native speaker, we examine the efficacy of few-shot LLM prompting for machine translation (MT) in this low-resource context. Our methodology involves the strategic selection of parallel sentences and dictionary entries for prompting, aiming to enhance translation accuracy, using open-source and proprietary LLMs (LlaMa 2 70b, Mixtral 8x7B, GPT-4). We find that including dictionary entries in prompts and a mix of sentences retrieved through TF-IDF and semantic embeddings significantly improves translation quality. However, our findings reveal stark disparities in translation performance across test sets, with BLEU scores reaching as high as 21.2 on materials from the language manual, in contrast to a maximum of 4.4 on a test set provided by a native speaker. These results underscore the importance of diverse and representative corpora in assessing MT for low-resource languages. Our research provides insights into few-shot LLM prompting for low-resource MT, and makes available an initial corpus for the Mambai language.
4/9/2024
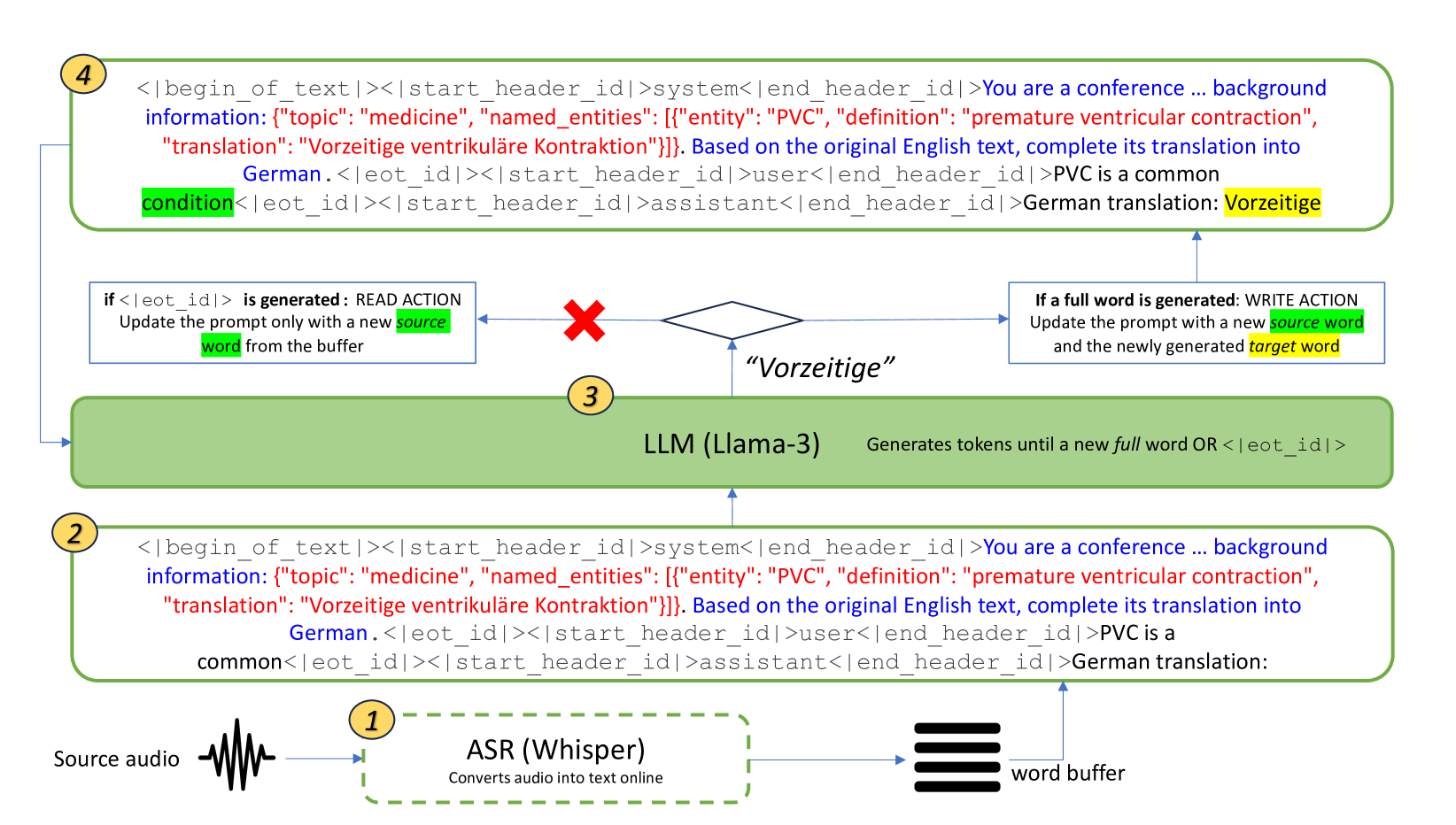
LLMs Are Zero-Shot Context-Aware Simultaneous Translators
Roman Koshkin, Katsuhito Sudoh, Satoshi Nakamura
0
0
The advent of transformers has fueled progress in machine translation. More recently large language models (LLMs) have come to the spotlight thanks to their generality and strong performance in a wide range of language tasks, including translation. Here we show that open-source LLMs perform on par with or better than some state-of-the-art baselines in simultaneous machine translation (SiMT) tasks, zero-shot. We also demonstrate that injection of minimal background information, which is easy with an LLM, brings further performance gains, especially on challenging technical subject-matter. This highlights LLMs' potential for building next generation of massively multilingual, context-aware and terminologically accurate SiMT systems that require no resource-intensive training or fine-tuning.
6/24/2024
💬
LLMs Are Few-Shot In-Context Low-Resource Language Learners
Samuel Cahyawijaya, Holy Lovenia, Pascale Fung
0
0
In-context learning (ICL) empowers large language models (LLMs) to perform diverse tasks in underrepresented languages using only short in-context information, offering a crucial avenue for narrowing the gap between high-resource and low-resource languages. Nonetheless, there is only a handful of works explored ICL for low-resource languages with most of them focusing on relatively high-resource languages, such as French and Spanish. In this work, we extensively study ICL and its cross-lingual variation (X-ICL) on 25 low-resource and 7 relatively higher-resource languages. Our study not only assesses the effectiveness of ICL with LLMs in low-resource languages but also identifies the shortcomings of in-context label alignment, and introduces a more effective alternative: query alignment. Moreover, we provide valuable insights into various facets of ICL for low-resource languages. Our study concludes the significance of few-shot in-context information on enhancing the low-resource understanding quality of LLMs through semantically relevant information by closing the language gap in the target language and aligning the semantics between the targeted low-resource and the high-resource language that the model is proficient in. Our work highlights the importance of advancing ICL research, particularly for low-resource languages. Our code is publicly released at https://github.com/SamuelCahyawijaya/in-context-alignment
6/26/2024
💬
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
0
0
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
6/17/2024