Low-Resource Machine Translation through Retrieval-Augmented LLM Prompting: A Study on the Mambai Language
2404.04809
0
0
Abstract
This study explores the use of large language models (LLMs) for translating English into Mambai, a low-resource Austronesian language spoken in Timor-Leste, with approximately 200,000 native speakers. Leveraging a novel corpus derived from a Mambai language manual and additional sentences translated by a native speaker, we examine the efficacy of few-shot LLM prompting for machine translation (MT) in this low-resource context. Our methodology involves the strategic selection of parallel sentences and dictionary entries for prompting, aiming to enhance translation accuracy, using open-source and proprietary LLMs (LlaMa 2 70b, Mixtral 8x7B, GPT-4). We find that including dictionary entries in prompts and a mix of sentences retrieved through TF-IDF and semantic embeddings significantly improves translation quality. However, our findings reveal stark disparities in translation performance across test sets, with BLEU scores reaching as high as 21.2 on materials from the language manual, in contrast to a maximum of 4.4 on a test set provided by a native speaker. These results underscore the importance of diverse and representative corpora in assessing MT for low-resource languages. Our research provides insights into few-shot LLM prompting for low-resource MT, and makes available an initial corpus for the Mambai language.
Create account to get full access
Overview
- This paper explores the use of retrieval-augmented language models (LLMs) for low-resource machine translation, focusing on the Mambai language as a case study.
- The researchers developed a novel approach that leverages the knowledge and language capabilities of LLMs to translate between Mambai and English, even with limited training data.
- The proposed method outperforms traditional machine translation models and demonstrates the potential of retrieval-augmented LLMs for tackling low-resource language challenges.
Plain English Explanation
The paper discusses a new way to translate between languages using large language models (LLMs) - computer systems that can understand and generate human-like text. The researchers focused on the Mambai language, which is considered a "low-resource" language, meaning there is very little digital data available to train translation models.
To address this challenge, the researchers developed a technique that combines LLMs with a "retrieval" system. This allows the LLM to draw on relevant information from a database of existing text, rather than relying solely on the limited training data available. [This relates to the concept of retrieval-augmented LLM prompting discussed in other research.]
The researchers found that this retrieval-augmented approach outperformed traditional machine translation models, even when working with the scarce Mambai language data. This suggests that LLMs, when combined with retrieval systems, have great potential for translating between "low-resource" languages where there is not much digital content available. [This connects to the broader research on using LLMs for low-resource language tasks.]
Technical Explanation
The paper presents a novel approach for low-resource machine translation using retrieval-augmented language models (LLMs). The researchers focused their study on the Mambai language, which has limited digital resources available for training traditional translation models.
To address this challenge, the team developed a retrieval-augmented LLM prompting technique. This involves using the LLM's language understanding and generation capabilities in conjunction with a retrieval system that can identify relevant textual information from a database. [This builds on prior work on large language model-driven reference-less approaches.]
The researchers evaluated their approach by comparing it to baseline machine translation models on a Mambai-English translation task. Their results showed that the retrieval-augmented LLM method outperformed the traditional models, despite the low-resource nature of the Mambai language data. [These findings connect to research on using LLMs for spoken language understanding and translation.]
Critical Analysis
The paper presents a promising approach for tackling low-resource language translation challenges using retrieval-augmented LLMs. The researchers acknowledge that their study is limited to a single language pair (Mambai-English) and suggest that further evaluation on other low-resource languages would be valuable.
Additionally, the paper does not provide detailed information about the size and quality of the Mambai language dataset used in the experiments. The performance of the retrieval-augmented LLM method may be dependent on the availability and characteristics of the reference texts in the retrieval database. [This relates to the importance of dataset quality and curation for effective LLM-based applications.]
While the results demonstrate the potential of this approach, further research is needed to understand the limitations and optimal configurations for retrieval-augmented LLM prompting in low-resource settings. [Expanding on this, the paper's findings connect to the broader area of personalized recommendation using LLM prompting.]
Conclusion
This paper presents a promising approach for low-resource machine translation using retrieval-augmented language models. By combining the language understanding and generation capabilities of LLMs with a retrieval system, the researchers were able to outperform traditional translation models on a Mambai-English task, even with limited training data.
The results suggest that this retrieval-augmented LLM prompting technique has significant potential for addressing challenges in low-resource language translation and potentially other areas of natural language processing. Further research on the scalability and generalization of this approach could lead to valuable advancements in supporting underserved language communities and expanding access to multilingual communication and information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Shortcomings of LLMs for Low-Resource Translation: Retrieval and Understanding are Both the Problem
Sara Court, Micha Elsner
0
0
This work investigates the in-context learning abilities of pretrained large language models (LLMs) when instructed to translate text from a low-resource language into a high-resource language as part of an automated machine translation pipeline. We conduct a set of experiments translating Southern Quechua to Spanish and examine the informativity of various types of information retrieved from a constrained database of digitized pedagogical materials (dictionaries and grammar lessons) and parallel corpora. Using both automatic and human evaluation of model output, we conduct ablation studies that manipulate (1) context type (morpheme translations, grammar descriptions, and corpus examples), (2) retrieval methods (automated vs. manual), and (3) model type. Our results suggest that even relatively small LLMs are capable of utilizing prompt context for zero-shot low-resource translation when provided a minimally sufficient amount of relevant linguistic information. However, the variable effects of prompt type, retrieval method, model type, and language-specific factors highlight the limitations of using even the best LLMs as translation systems for the majority of the world's 7,000+ languages and their speakers.
6/26/2024
💬
Exploring the Capabilities of Prompted Large Language Models in Educational and Assessment Applications
Subhankar Maity, Aniket Deroy, Sudeshna Sarkar
0
0
In the era of generative artificial intelligence (AI), the fusion of large language models (LLMs) offers unprecedented opportunities for innovation in the field of modern education. We embark on an exploration of prompted LLMs within the context of educational and assessment applications to uncover their potential. Through a series of carefully crafted research questions, we investigate the effectiveness of prompt-based techniques in generating open-ended questions from school-level textbooks, assess their efficiency in generating open-ended questions from undergraduate-level technical textbooks, and explore the feasibility of employing a chain-of-thought inspired multi-stage prompting approach for language-agnostic multiple-choice question (MCQ) generation. Additionally, we evaluate the ability of prompted LLMs for language learning, exemplified through a case study in the low-resource Indian language Bengali, to explain Bengali grammatical errors. We also evaluate the potential of prompted LLMs to assess human resource (HR) spoken interview transcripts. By juxtaposing the capabilities of LLMs with those of human experts across various educational tasks and domains, our aim is to shed light on the potential and limitations of LLMs in reshaping educational practices.
5/21/2024
💬
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
0
0
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
6/17/2024
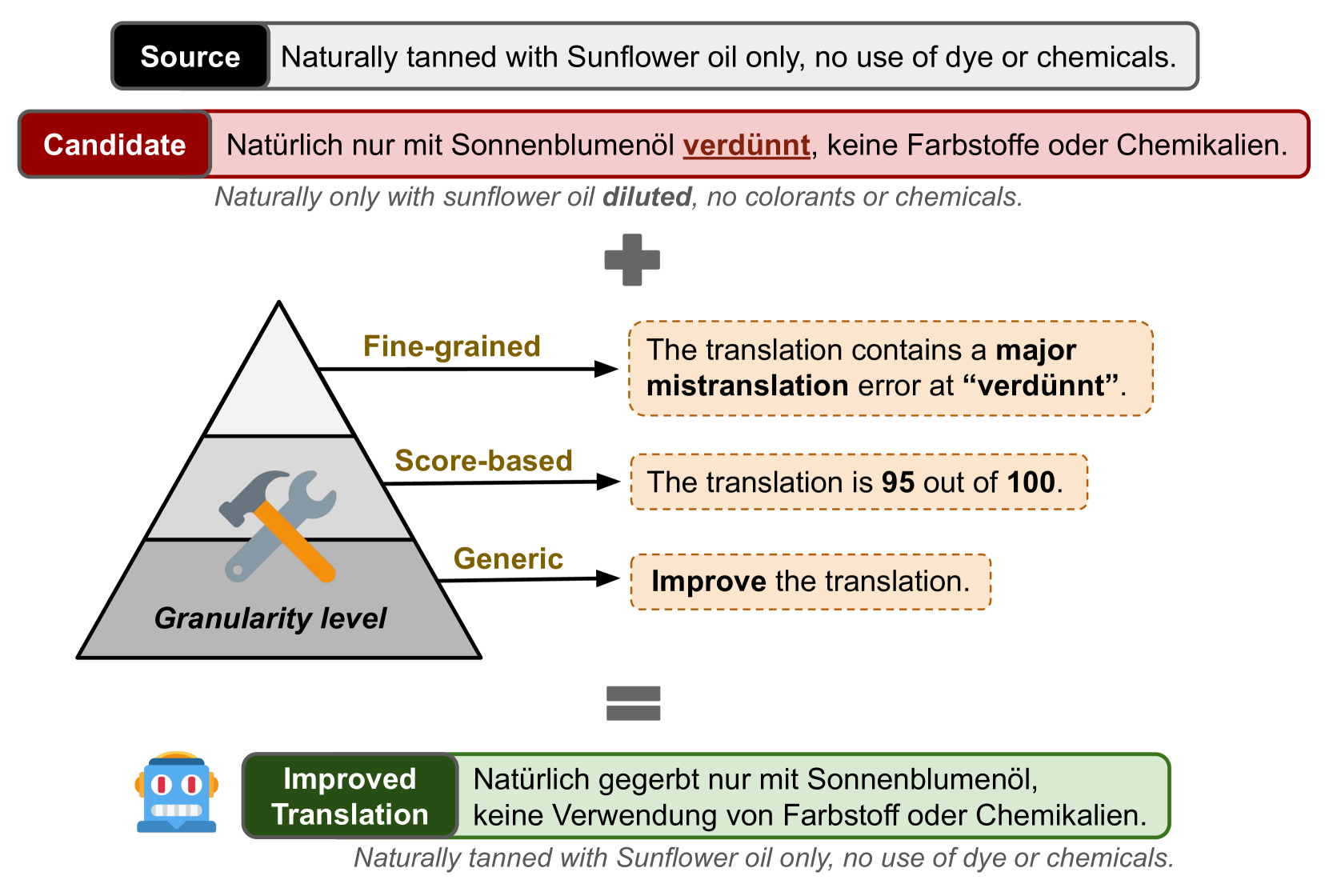
Guiding Large Language Models to Post-Edit Machine Translation with Error Annotations
Dayeon Ki, Marine Carpuat
0
0
Machine Translation (MT) remains one of the last NLP tasks where large language models (LLMs) have not yet replaced dedicated supervised systems. This work exploits the complementary strengths of LLMs and supervised MT by guiding LLMs to automatically post-edit MT with external feedback on its quality, derived from Multidimensional Quality Metric (MQM) annotations. Working with LLaMA-2 models, we consider prompting strategies varying the nature of feedback provided and then fine-tune the LLM to improve its ability to exploit the provided guidance. Through experiments on Chinese-English, English-German, and English-Russian MQM data, we demonstrate that prompting LLMs to post-edit MT improves TER, BLEU and COMET scores, although the benefits of fine-grained feedback are not clear. Fine-tuning helps integrate fine-grained feedback more effectively and further improves translation quality based on both automatic and human evaluation.
4/12/2024