SignAvatar: Sign Language 3D Motion Reconstruction and Generation
2405.07974
0
0
💬
Abstract
Achieving expressive 3D motion reconstruction and automatic generation for isolated sign words can be challenging, due to the lack of real-world 3D sign-word data, the complex nuances of signing motions, and the cross-modal understanding of sign language semantics. To address these challenges, we introduce SignAvatar, a framework capable of both word-level sign language reconstruction and generation. SignAvatar employs a transformer-based conditional variational autoencoder architecture, effectively establishing relationships across different semantic modalities. Additionally, this approach incorporates a curriculum learning strategy to enhance the model's robustness and generalization, resulting in more realistic motions. Furthermore, we contribute the ASL3DWord dataset, composed of 3D joint rotation data for the body, hands, and face, for unique sign words. We demonstrate the effectiveness of SignAvatar through extensive experiments, showcasing its superior reconstruction and automatic generation capabilities. The code and dataset are available on the project page.
Create account to get full access
Overview
- Challenges in 3D motion reconstruction and automatic generation for isolated sign words
- Lack of real-world 3D sign-word data, complex signing motions, and cross-modal understanding of sign language semantics
- Introduction of SignAvatar, a framework for word-level sign language reconstruction and generation
- Employs a transformer-based conditional variational autoencoder architecture
- Incorporates a curriculum learning strategy for robust and realistic motions
- Contribution of the ASL3DWord dataset of 3D joint rotation data for unique sign words
Plain English Explanation
Representing 3D sign language motions and automatically generating new sign words can be very challenging. This is because there is not much real-world 3D data available for sign language, the signing movements are complex with a lot of nuance, and there are connections between the visual aspects of sign language and its semantic meaning that are difficult to capture.
To address these challenges, the researchers developed a system called SignAvatar. SignAvatar uses a special type of neural network architecture, called a transformer-based conditional variational autoencoder, to learn the relationships between the different aspects of sign language, like the hand movements, body posture, and facial expressions. This allows SignAvatar to both reconstruct 3D sign language motions from existing data, as well as generate new, realistic sign language motions automatically.
Additionally, the researchers used a curriculum learning strategy, which means they trained the model in stages of increasing difficulty. This helped make the model more robust and able to generate high-quality, natural-looking sign language motions.
The researchers also created a new dataset called ASL3DWord, which contains 3D joint rotation data for the body, hands, and face for many different American Sign Language words. This dataset can be used to further develop and test sign language motion reconstruction and generation systems.
Technical Explanation
The SignAvatar framework uses a transformer-based conditional variational autoencoder (CVAE) architecture to establish relationships across different semantic modalities for sign language. This allows the model to effectively reconstruct 3D sign language motions from existing data and automatically generate new, realistic sign language motions.
The CVAE architecture consists of an encoder that compresses the input data into a latent representation, and a decoder that generates the output from the latent representation. The transformer component helps the model capture the complex spatial and temporal relationships in sign language motions.
To enhance the model's robustness and generalization, the researchers incorporate a curriculum learning strategy. This involves training the model in stages of increasing difficulty, starting with simpler sign language motions and gradually moving to more complex ones. This helps the model learn more effectively and produce more realistic sign language motions.
The researchers also introduce the ASL3DWord dataset, which provides 3D joint rotation data for the body, hands, and face for a large number of unique American Sign Language words. This dataset can be used to further develop and evaluate sign language motion reconstruction and generation systems.
Critical Analysis
The SignAvatar framework and the ASL3DWord dataset represent significant advancements in the field of sign language motion reconstruction and generation. However, a few limitations and areas for further research are worth considering.
While the curriculum learning strategy helps improve the model's robustness, the researchers do not provide a detailed analysis of the specific challenges faced during the different stages of the curriculum. Exploring these challenges could lead to further refinements and improvements to the learning process.
Additionally, the paper does not discuss the potential biases or limitations of the ASL3DWord dataset, such as the diversity of the signers or the representativeness of the sign language motions. Addressing these potential biases could enhance the generalizability of the research.
Furthermore, the paper focuses on isolated sign word reconstruction and generation, but sign language communication often involves continuous, connected sign language. Extending the research to address continuous sign language motions could be a valuable direction for future work.
Conclusion
The SignAvatar framework and the ASL3DWord dataset represent significant advancements in the field of 3D sign language motion reconstruction and generation. By employing a transformer-based conditional variational autoencoder architecture and incorporating a curriculum learning strategy, the researchers have developed a system capable of effectively capturing the complex nuances of sign language motions and generating realistic sign language animations.
The contributions of this research have the potential to impact various applications, such as sign language animation, sign language recognition, and sign language generation. Furthermore, the ASL3DWord dataset can serve as a valuable resource for developing and evaluating future sign language motion reconstruction and generation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
SignAvatars: A Large-scale 3D Sign Language Holistic Motion Dataset and Benchmark
Zhengdi Yu, Shaoli Huang, Yongkang Cheng, Tolga Birdal
0
0
We present SignAvatars, the first large-scale, multi-prompt 3D sign language (SL) motion dataset designed to bridge the communication gap for Deaf and hard-of-hearing individuals. While there has been an exponentially growing number of research regarding digital communication, the majority of existing communication technologies primarily cater to spoken or written languages, instead of SL, the essential communication method for Deaf and hard-of-hearing communities. Existing SL datasets, dictionaries, and sign language production (SLP) methods are typically limited to 2D as annotating 3D models and avatars for SL is usually an entirely manual and labor-intensive process conducted by SL experts, often resulting in unnatural avatars. In response to these challenges, we compile and curate the SignAvatars dataset, which comprises 70,000 videos from 153 signers, totaling 8.34 million frames, covering both isolated signs and continuous, co-articulated signs, with multiple prompts including HamNoSys, spoken language, and words. To yield 3D holistic annotations, including meshes and biomechanically-valid poses of body, hands, and face, as well as 2D and 3D keypoints, we introduce an automated annotation pipeline operating on our large corpus of SL videos. SignAvatars facilitates various tasks such as 3D sign language recognition (SLR) and the novel 3D SL production (SLP) from diverse inputs like text scripts, individual words, and HamNoSys notation. Hence, to evaluate the potential of SignAvatars, we further propose a unified benchmark of 3D SL holistic motion production. We believe that this work is a significant step forward towards bringing the digital world to the Deaf and hard-of-hearing communities as well as people interacting with them.
4/4/2024

Neural Sign Actors: A diffusion model for 3D sign language production from text
Vasileios Baltatzis, Rolandos Alexandros Potamias, Evangelos Ververas, Guanxiong Sun, Jiankang Deng, Stefanos Zafeiriou
0
0
Sign Languages (SL) serve as the primary mode of communication for the Deaf and Hard of Hearing communities. Deep learning methods for SL recognition and translation have achieved promising results. However, Sign Language Production (SLP) poses a challenge as the generated motions must be realistic and have precise semantic meaning. Most SLP methods rely on 2D data, which hinders their realism. In this work, a diffusion-based SLP model is trained on a curated large-scale dataset of 4D signing avatars and their corresponding text transcripts. The proposed method can generate dynamic sequences of 3D avatars from an unconstrained domain of discourse using a diffusion process formed on a novel and anatomically informed graph neural network defined on the SMPL-X body skeleton. Through quantitative and qualitative experiments, we show that the proposed method considerably outperforms previous methods of SLP. This work makes an important step towards realistic neural sign avatars, bridging the communication gap between Deaf and hearing communities.
4/8/2024

Diversity-Aware Sign Language Production through a Pose Encoding Variational Autoencoder
Mohamed Ilyes Lakhal, Richard Bowden
0
0
This paper addresses the problem of diversity-aware sign language production, where we want to give an image (or sequence) of a signer and produce another image with the same pose but different attributes (textit{e.g.} gender, skin color). To this end, we extend the variational inference paradigm to include information about the pose and the conditioning of the attributes. This formulation improves the quality of the synthesised images. The generator framework is presented as a UNet architecture to ensure spatial preservation of the input pose, and we include the visual features from the variational inference to maintain control over appearance and style. We generate each body part with a separate decoder. This architecture allows the generator to deliver better overall results. Experiments on the SMILE II dataset show that the proposed model performs quantitatively better than state-of-the-art baselines regarding diversity, per-pixel image quality, and pose estimation. Quantitatively, it faithfully reproduces non-manual features for signers.
5/20/2024
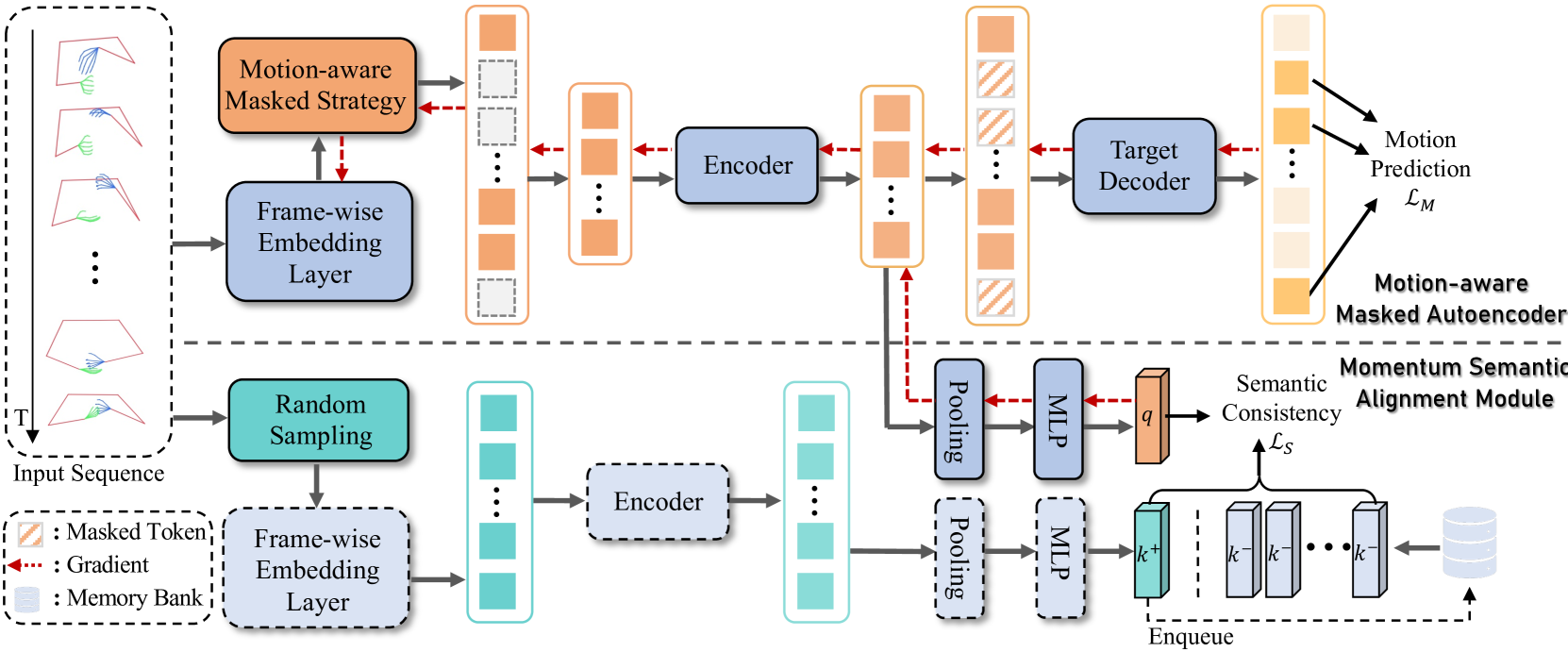
MASA: Motion-aware Masked Autoencoder with Semantic Alignment for Sign Language Recognition
Weichao Zhao, Hezhen Hu, Wengang Zhou, Yunyao Mao, Min Wang, Houqiang Li
0
0
Sign language recognition (SLR) has long been plagued by insufficient model representation capabilities. Although current pre-training approaches have alleviated this dilemma to some extent and yielded promising performance by employing various pretext tasks on sign pose data, these methods still suffer from two primary limitations: 1) Explicit motion information is usually disregarded in previous pretext tasks, leading to partial information loss and limited representation capability. 2) Previous methods focus on the local context of a sign pose sequence, without incorporating the guidance of the global meaning of lexical signs. To this end, we propose a Motion-Aware masked autoencoder with Semantic Alignment (MASA) that integrates rich motion cues and global semantic information in a self-supervised learning paradigm for SLR. Our framework contains two crucial components, i.e., a motion-aware masked autoencoder (MA) and a momentum semantic alignment module (SA). Specifically, in MA, we introduce an autoencoder architecture with a motion-aware masked strategy to reconstruct motion residuals of masked frames, thereby explicitly exploring dynamic motion cues among sign pose sequences. Moreover, in SA, we embed our framework with global semantic awareness by aligning the embeddings of different augmented samples from the input sequence in the shared latent space. In this way, our framework can simultaneously learn local motion cues and global semantic features for comprehensive sign language representation. Furthermore, we conduct extensive experiments to validate the effectiveness of our method, achieving new state-of-the-art performance on four public benchmarks.
6/3/2024