SiloFuse: Cross-silo Synthetic Data Generation with Latent Tabular Diffusion Models
2404.03299
0
0

Abstract
Synthetic tabular data is crucial for sharing and augmenting data across silos, especially for enterprises with proprietary data. However, existing synthesizers are designed for centrally stored data. Hence, they struggle with real-world scenarios where features are distributed across multiple silos, necessitating on-premise data storage. We introduce SiloFuse, a novel generative framework for high-quality synthesis from cross-silo tabular data. To ensure privacy, SiloFuse utilizes a distributed latent tabular diffusion architecture. Through autoencoders, latent representations are learned for each client's features, masking their actual values. We employ stacked distributed training to improve communication efficiency, reducing the number of rounds to a single step. Under SiloFuse, we prove the impossibility of data reconstruction for vertically partitioned synthesis and quantify privacy risks through three attacks using our benchmark framework. Experimental results on nine datasets showcase SiloFuse's competence against centralized diffusion-based synthesizers. Notably, SiloFuse achieves 43.8 and 29.8 higher percentage points over GANs in resemblance and utility. Experiments on communication show stacked training's fixed cost compared to the growing costs of end-to-end training as the number of training iterations increases. Additionally, SiloFuse proves robust to feature permutations and varying numbers of clients.
Create account to get full access
Overview
- This paper introduces a new technique called \algo for generating synthetic data across multiple distributed databases while preserving privacy.
- The key idea is to use a latent diffusion model to learn a generative representation of the data that can be shared without revealing the original data.
- This allows multiple parties to collaborate on synthetic data generation without directly accessing each other's sensitive information.
- The authors demonstrate that the synthetic data produced by \algo can effectively mimic the statistical properties of the original data, making it useful for tasks like model training.
Plain English Explanation
The main challenge addressed in this paper is how to generate synthetic data that mimics real-world data, without directly sharing the sensitive original data. This is an important problem because organizations often want to collaborate on tasks like training machine learning models, but can't simply share their private databases.
The researchers developed a new technique called \algo that gets around this issue. The core idea is to use a special kind of machine learning model called a "latent diffusion model" to learn an abstract representation of the data, rather than the raw data itself. This learned representation captures the key statistical properties of the data, but doesn't contain the sensitive individual-level information.
Once this latent representation is learned, the different organizations can share it and use it to generate new synthetic data that looks very similar to the original datasets, but doesn't reveal the private information. This synthetic data can then be used for collaborative tasks like model training, without compromising data privacy.
The key advantage of this approach is that it allows useful data-driven applications to be developed across organizational boundaries, without the need to directly share sensitive datasets. This could enable new forms of data collaboration and innovation, while still protecting individual privacy.
Technical Explanation
The core technical innovation of \algo is the use of a latent diffusion model for synthetic data generation in a cross-silo setting. Diffusion models are a type of generative AI that work by gradually adding noise to data and then learning how to reverse that process to generate new samples.
In this case, the diffusion model operates on a latent representation of the tabular data, rather than the raw data itself. This latent space captures the key statistical properties of the data in a compressed form, without containing the sensitive individual-level details.
The authors demonstrate a training procedure where each party trains their own local diffusion model on their private data, and then shares the learned latent representations. These can then be used to generate synthetic data that maintains the statistical fidelity of the original datasets, while preserving privacy.
Key experiments show that the synthetic data produced by \algo is highly useful for tasks like model training, achieving comparable performance to training on the original data. The authors also analyze the privacy-utility tradeoffs and show that \algo can generate high-quality synthetic data while providing strong privacy guarantees.
Critical Analysis
The \algo approach presents an interesting and promising solution for enabling cross-silo collaboration on sensitive datasets. By focusing on learning a latent representation rather than sharing raw data, it sidesteps many of the privacy concerns that have hindered previous attempts at distributed data sharing.
That said, the authors acknowledge several potential limitations and areas for further research. For example, the approach assumes that the different datasets have similar underlying distributions, which may not always be the case in practice. There are also open questions around the robustness of the latent diffusion models and their ability to capture complex, high-dimensional data distributions.
Additionally, while the privacy guarantees of \algo are compelling, it's unclear how they would hold up against determined adversaries or in the face of potential vulnerabilities in the underlying machine learning models. Further security and privacy analysis would be needed to fully assess the risks.
Overall, \algo represents an important step forward in enabling privacy-preserving data collaboration. However, as with any new technology, there are still open challenges and potential pitfalls that will need to be carefully considered as the research progresses.
Conclusion
The \algo technique introduced in this paper offers a novel approach to the problem of synthetic data generation in a cross-silo setting. By leveraging latent diffusion models, it allows multiple parties to collaborate on data-driven applications without directly sharing sensitive information.
This has significant potential implications for fields like healthcare, finance, and other domains where data privacy is paramount. By enabling new forms of data collaboration while preserving individual privacy, \algo could lead to important breakthroughs and innovations that were previously hindered by data silos.
Of course, as with any emerging technology, there are still open questions and areas for further research. But the core ideas presented in this paper represent an important step forward in the ongoing effort to unlock the power of data-driven applications while respecting individual privacy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CollaFuse: Collaborative Diffusion Models
Simeon Allmendinger, Domenique Zipperling, Lukas Struppek, Niklas Kuhl
0
0
In the landscape of generative artificial intelligence, diffusion-based models have emerged as a promising method for generating synthetic images. However, the application of diffusion models poses numerous challenges, particularly concerning data availability, computational requirements, and privacy. Traditional approaches to address these shortcomings, like federated learning, often impose significant computational burdens on individual clients, especially those with constrained resources. In response to these challenges, we introduce a novel approach for distributed collaborative diffusion models inspired by split learning. Our approach facilitates collaborative training of diffusion models while alleviating client computational burdens during image synthesis. This reduced computational burden is achieved by retaining data and computationally inexpensive processes locally at each client while outsourcing the computationally expensive processes to shared, more efficient server resources. Through experiments on the common CelebA dataset, our approach demonstrates enhanced privacy by reducing the necessity for sharing raw data. These capabilities hold significant potential across various application areas, including the design of edge computing solutions. Thus, our work advances distributed machine learning by contributing to the evolution of collaborative diffusion models.
6/21/2024
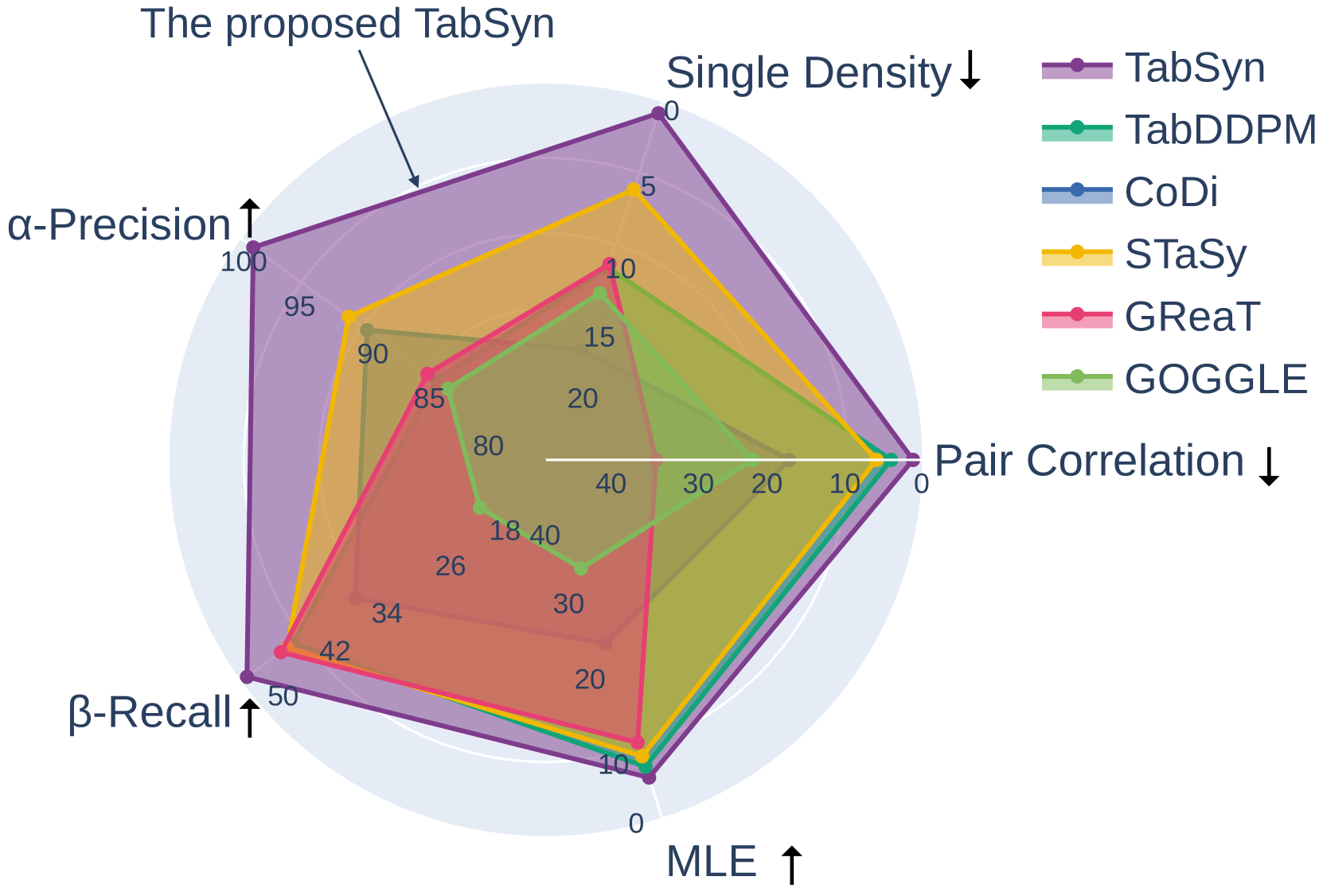
Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space
Hengrui Zhang, Jiani Zhang, Balasubramaniam Srinivasan, Zhengyuan Shen, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, George Karypis
0
0
Recent advances in tabular data generation have greatly enhanced synthetic data quality. However, extending diffusion models to tabular data is challenging due to the intricately varied distributions and a blend of data types of tabular data. This paper introduces Tabsyn, a methodology that synthesizes tabular data by leveraging a diffusion model within a variational autoencoder (VAE) crafted latent space. The key advantages of the proposed Tabsyn include (1) Generality: the ability to handle a broad spectrum of data types by converting them into a single unified space and explicitly capture inter-column relations; (2) Quality: optimizing the distribution of latent embeddings to enhance the subsequent training of diffusion models, which helps generate high-quality synthetic data, (3) Speed: much fewer number of reverse steps and faster synthesis speed than existing diffusion-based methods. Extensive experiments on six datasets with five metrics demonstrate that Tabsyn outperforms existing methods. Specifically, it reduces the error rates by 86% and 67% for column-wise distribution and pair-wise column correlation estimations compared with the most competitive baselines.
5/14/2024

New!Diffusion Models for Tabular Data Imputation and Synthetic Data Generation
Mario Villaiz'an-Vallelado, Matteo Salvatori, Carlos Segura, Ioannis Arapakis
0
0
Data imputation and data generation have important applications for many domains, like healthcare and finance, where incomplete or missing data can hinder accurate analysis and decision-making. Diffusion models have emerged as powerful generative models capable of capturing complex data distributions across various data modalities such as image, audio, and time series data. Recently, they have been also adapted to generate tabular data. In this paper, we propose a diffusion model for tabular data that introduces three key enhancements: (1) a conditioning attention mechanism, (2) an encoder-decoder transformer as the denoising network, and (3) dynamic masking. The conditioning attention mechanism is designed to improve the model's ability to capture the relationship between the condition and synthetic data. The transformer layers help model interactions within the condition (encoder) or synthetic data (decoder), while dynamic masking enables our model to efficiently handle both missing data imputation and synthetic data generation tasks within a unified framework. We conduct a comprehensive evaluation by comparing the performance of diffusion models with transformer conditioning against state-of-the-art techniques, such as Variational Autoencoders, Generative Adversarial Networks and Diffusion Models, on benchmark datasets. Our evaluation focuses on the assessment of the generated samples with respect to three important criteria, namely: (1) Machine Learning efficiency, (2) statistical similarity, and (3) privacy risk mitigation. For the task of data imputation, we consider the efficiency of the generated samples across different levels of missing features.
7/4/2024
👨🏫
A supervised generative optimization approach for tabular data
Shinpei Nakamura-Sakai, Fadi Hamad, Saheed Obitayo, Vamsi K. Potluru
0
0
Synthetic data generation has emerged as a crucial topic for financial institutions, driven by multiple factors, such as privacy protection and data augmentation. Many algorithms have been proposed for synthetic data generation but reaching the consensus on which method we should use for the specific data sets and use cases remains challenging. Moreover, the majority of existing approaches are ``unsupervised'' in the sense that they do not take into account the downstream task. To address these issues, this work presents a novel synthetic data generation framework. The framework integrates a supervised component tailored to the specific downstream task and employs a meta-learning approach to learn the optimal mixture distribution of existing synthetic distributions.
5/13/2024