Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space
2310.09656
0
0
Abstract
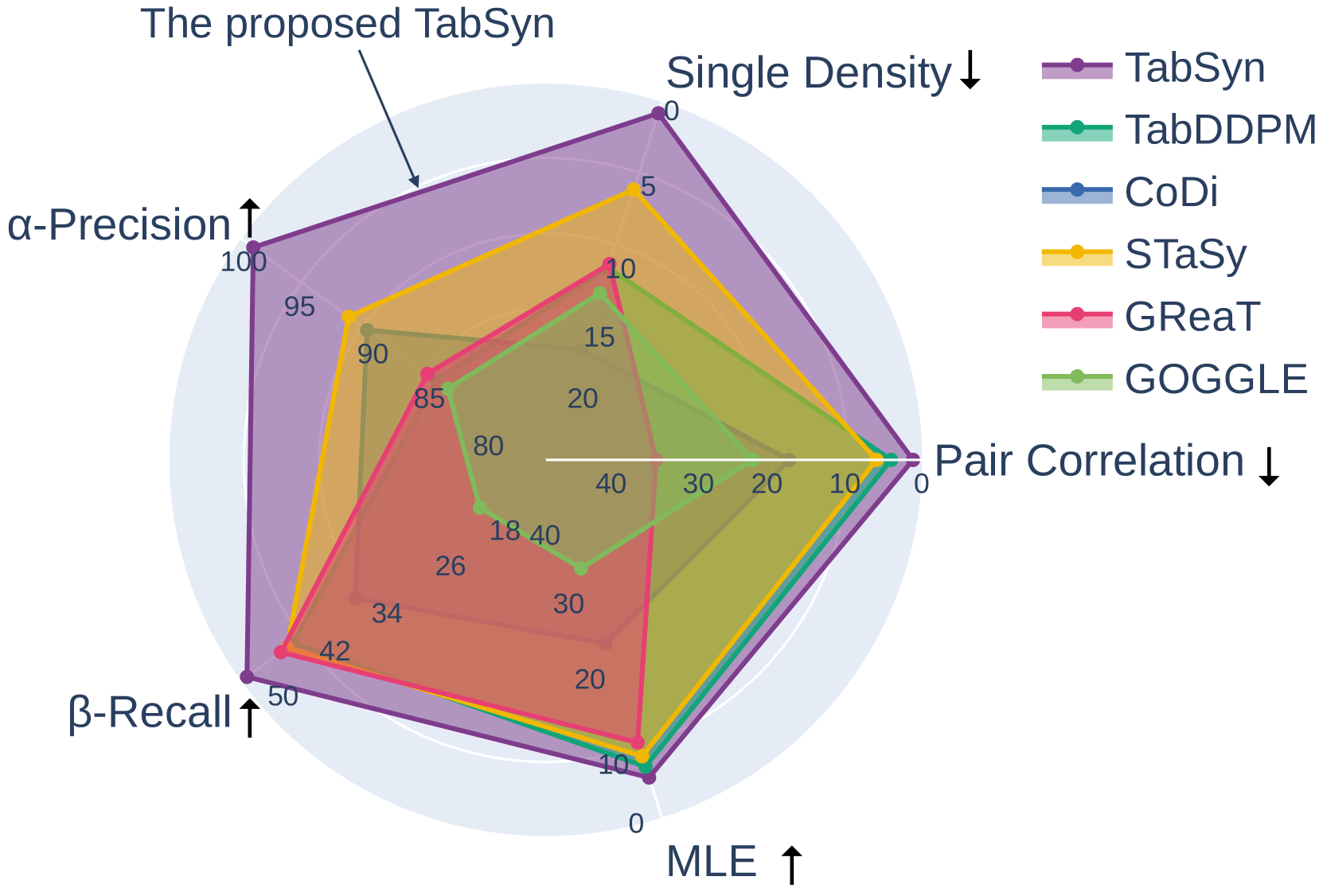
Recent advances in tabular data generation have greatly enhanced synthetic data quality. However, extending diffusion models to tabular data is challenging due to the intricately varied distributions and a blend of data types of tabular data. This paper introduces Tabsyn, a methodology that synthesizes tabular data by leveraging a diffusion model within a variational autoencoder (VAE) crafted latent space. The key advantages of the proposed Tabsyn include (1) Generality: the ability to handle a broad spectrum of data types by converting them into a single unified space and explicitly capture inter-column relations; (2) Quality: optimizing the distribution of latent embeddings to enhance the subsequent training of diffusion models, which helps generate high-quality synthetic data, (3) Speed: much fewer number of reverse steps and faster synthesis speed than existing diffusion-based methods. Extensive experiments on six datasets with five metrics demonstrate that Tabsyn outperforms existing methods. Specifically, it reduces the error rates by 86% and 67% for column-wise distribution and pair-wise column correlation estimations compared with the most competitive baselines.
Create account to get full access
Overview
- This paper presents a method for generating realistic synthetic tabular data with mixed data types (e.g., numeric, categorical, and ordinal features).
- The proposed approach uses a score-based diffusion model in the latent space to capture the complex distributions of the input data.
- The model can handle various data types and preserves the statistical properties and relationships between features in the generated data.
Plain English Explanation
The paper describes a way to create fake data that looks a lot like real data, even if the real data has different types of information in it. For example, the real data might have some numbers, some categories (like "yes" or "no"), and some ranking information (like "low," "medium," or "high").
The researchers use a special type of machine learning model called a "score-based diffusion model" to capture the complex patterns in the real data. This model can learn how the different types of information are related to each other and then use that knowledge to generate new fake data that has the same kinds of patterns.
The key idea is to create the fake data in a hidden "latent space" rather than directly generating the data itself. This latent space allows the model to represent the underlying structure of the data more effectively. The model then uses this latent representation to produce new, realistic-looking data.
The main benefit of this approach is that it can create synthetic data that closely matches the statistical properties and relationships in the original data, even when the data has a mix of different data types. This can be useful for testing machine learning models or generating training data when the real data is sensitive or limited.
Technical Explanation
The paper introduces a novel method for generating synthetic tabular data with mixed data types, such as numeric, categorical, and ordinal features. The proposed approach, called Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space, leverages a score-based diffusion model in the latent space to capture the complex underlying distributions of the input data.
The key innovation is the use of a latent space representation, which allows the model to learn the relationships between the different data types more effectively. The score-based diffusion model is trained to gradually transform random noise into realistic synthetic data by following the gradients of the data's score function in the latent space.
The model is designed to handle various data types, including numeric, categorical, and ordinal features, and can preserve the statistical properties and relationships between the features in the generated data. This is achieved through careful design choices, such as using appropriate noise distributions and parameterizations for different data types.
The authors evaluate their approach on several real-world datasets and compare it to existing state-of-the-art tabular data generation methods, such as Improved Tabular Data Generator with VAE+GMM Integration, SiloFuse: Cross-Silo Synthetic Data Generation in Latent Space, and A Systematic Assessment of Tabular Data Synthesis Algorithms. The results demonstrate the superiority of the proposed method in terms of various evaluation metrics, such as statistical fidelity, utility preservation, and sample quality.
Critical Analysis
The paper presents a compelling approach to generating synthetic tabular data with mixed data types. The use of a score-based diffusion model in the latent space is a novel and promising technique that addresses the limitations of existing methods, which often struggle to capture the complex relationships between different data types.
One potential limitation of the approach is its reliance on the quality of the latent space representation. If the latent space does not accurately capture the underlying structure of the data, the generated synthetic data may not fully preserve the desired statistical properties and relationships. The authors acknowledge this challenge and suggest further research on improving the latent space representation.
Additionally, the paper does not provide a detailed analysis of the computational complexity and scalability of the proposed method. As the size and complexity of the tabular data increase, the training and inference time of the diffusion model may become a concern, especially for real-world applications.
Another area for further exploration is the potential for Supervised Generative Optimization Approach for Tabular Data, where the model's performance could be enhanced by incorporating task-specific supervision or guidance during the data generation process.
Overall, the paper presents a well-designed and promising approach to mixed-type tabular data synthesis. The authors have made a valuable contribution to the field, and the proposed method has the potential to be a powerful tool for various applications that require realistic synthetic data.
Conclusion
The paper introduces a novel method for generating synthetic tabular data with mixed data types, such as numeric, categorical, and ordinal features. The approach uses a score-based diffusion model in the latent space to capture the complex underlying distributions of the input data and preserve the statistical properties and relationships between the features in the generated data.
The proposed method outperforms existing state-of-the-art tabular data generation techniques, as demonstrated by the authors' evaluation on several real-world datasets. This work represents a significant advancement in the field of tabular data synthesis and has the potential to benefit a wide range of applications, from machine learning model testing to privacy-preserving data sharing.
While the paper presents a compelling solution, it also highlights areas for further research, such as improving the latent space representation and exploring the potential for supervised generative optimization. As the field of tabular data synthesis continues to evolve, this work serves as an important step forward and a valuable contribution to the research community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Balanced Mixed-Type Tabular Data Synthesis with Diffusion Models
Zeyu Yang, Peikun Guo, Khadija Zanna, Akane Sano
0
0
Diffusion models have emerged as a robust framework for various generative tasks, such as image and audio synthesis, and have also demonstrated a remarkable ability to generate mixed-type tabular data comprising both continuous and discrete variables. However, current approaches to training diffusion models on mixed-type tabular data tend to inherit the imbalanced distributions of features present in the training dataset, which can result in biased sampling. In this research, we introduce a fair diffusion model designed to generate balanced data on sensitive attributes. We present empirical evidence demonstrating that our method effectively mitigates the class imbalance in training data while maintaining the quality of the generated samples. Furthermore, we provide evidence that our approach outperforms existing methods for synthesizing tabular data in terms of performance and fairness.
4/15/2024

TimeAutoDiff: Combining Autoencoder and Diffusion model for time series tabular data synthesizing
Namjoon Suh, Yuning Yang, Din-Yin Hsieh, Qitong Luan, Shirong Xu, Shixiang Zhu, Guang Cheng
0
0
In this paper, we leverage the power of latent diffusion models to generate synthetic time series tabular data. Along with the temporal and feature correlations, the heterogeneous nature of the feature in the table has been one of the main obstacles in time series tabular data modeling. We tackle this problem by combining the ideas of the variational auto-encoder (VAE) and the denoising diffusion probabilistic model (DDPM). Our model named as texttt{TimeAutoDiff} has several key advantages including (1) Generality: the ability to handle the broad spectrum of time series tabular data from single to multi-sequence datasets; (2) Good fidelity and utility guarantees: numerical experiments on six publicly available datasets demonstrating significant improvements over state-of-the-art models in generating time series tabular data, across four metrics measuring fidelity and utility; (3) Fast sampling speed: entire time series data generation as opposed to the sequential data sampling schemes implemented in the existing diffusion-based models, eventually leading to significant improvements in sampling speed, (4) Entity conditional generation: the first implementation of conditional generation of multi-sequence time series tabular data with heterogenous features in the literature, enabling scenario exploration across multiple scientific and engineering domains. Codes are in preparation for release to the public, but available upon request.
6/26/2024
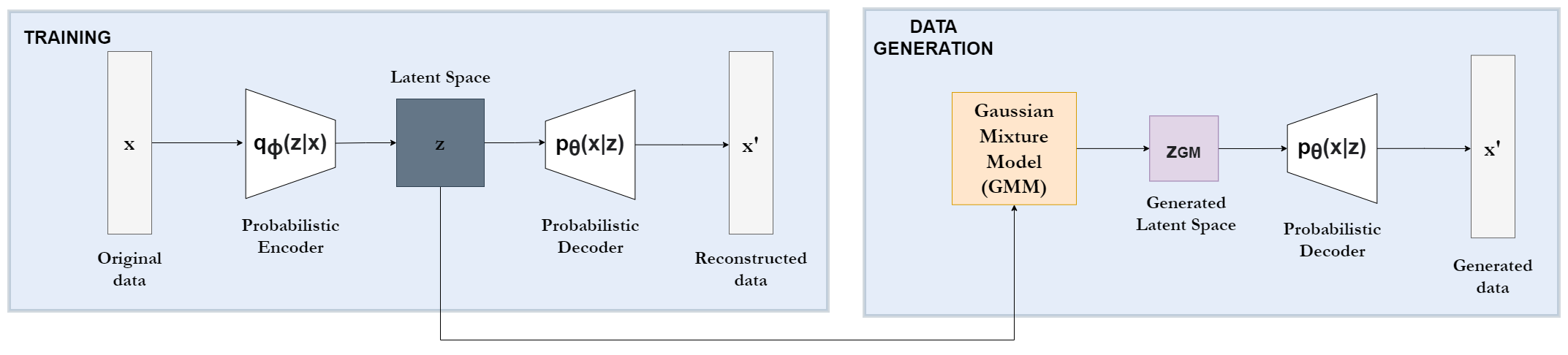
An improved tabular data generator with VAE-GMM integration
Patricia A. Apell'aniz, Juan Parras, Santiago Zazo
0
0
The rising use of machine learning in various fields requires robust methods to create synthetic tabular data. Data should preserve key characteristics while addressing data scarcity challenges. Current approaches based on Generative Adversarial Networks, such as the state-of-the-art CTGAN model, struggle with the complex structures inherent in tabular data. These data often contain both continuous and discrete features with non-Gaussian distributions. Therefore, we propose a novel Variational Autoencoder (VAE)-based model that addresses these limitations. Inspired by the TVAE model, our approach incorporates a Bayesian Gaussian Mixture model (BGM) within the VAE architecture. This avoids the limitations imposed by assuming a strictly Gaussian latent space, allowing for a more accurate representation of the underlying data distribution during data generation. Furthermore, our model offers enhanced flexibility by allowing the use of various differentiable distributions for individual features, making it possible to handle both continuous and discrete data types. We thoroughly validate our model on three real-world datasets with mixed data types, including two medically relevant ones, based on their resemblance and utility. This evaluation demonstrates significant outperformance against CTGAN and TVAE, establishing its potential as a valuable tool for generating synthetic tabular data in various domains, particularly in healthcare.
4/15/2024
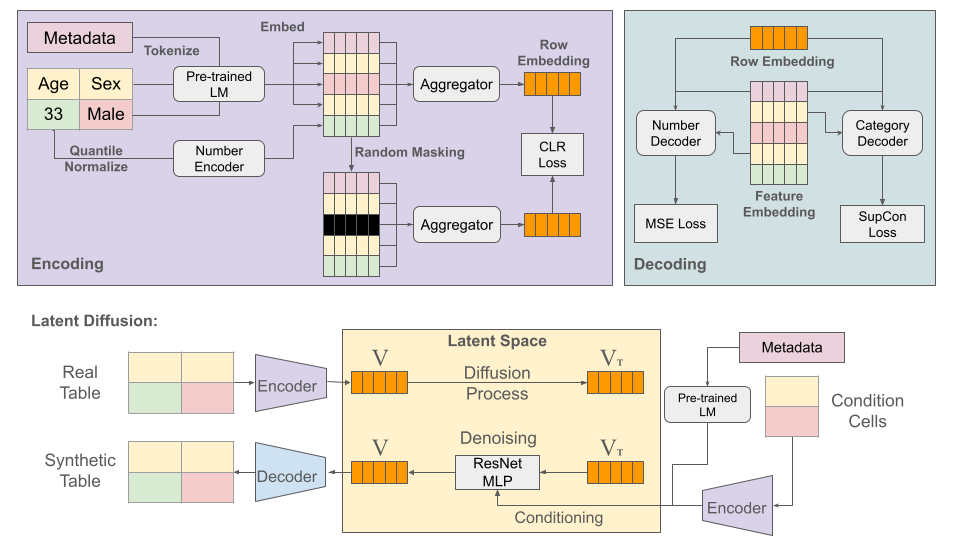
CTSyn: A Foundational Model for Cross Tabular Data Generation
Xiaofeng Lin, Chenheng Xu, Matthew Yang, Guang Cheng
0
0
Generative Foundation Models (GFMs) have produced synthetic data with remarkable quality in modalities such as images and text. However, applying GFMs to tabular data poses significant challenges due to the inherent heterogeneity of table features. Existing cross-table learning frameworks are hindered by the absence of both a generative model backbone and a decoding mechanism for heterogeneous feature values. To overcome these limitations, we introduce the Cross-Table Synthesizer (CTSyn), a diffusion-based foundational model tailored for tabular data generation. CTSyn introduces three major components: an aggregator that consolidates heterogeneous tables into a unified latent space; a conditional latent diffusion model for sampling from this space; and type-specific decoders that reconstruct values of varied data types from sampled latent vectors. Extensive testing on real-world datasets reveals that CTSyn not only significantly outperforms existing table synthesizers in utility and diversity, but also uniquely enhances performances of downstream machine learning beyond what is achievable with real data, thus establishing a new paradigm for synthetic data generation.
6/10/2024