SilverSight: A Multi-Task Chinese Financial Large Language Model Based on Adaptive Semantic Space Learning
2404.04949
0
0
Abstract
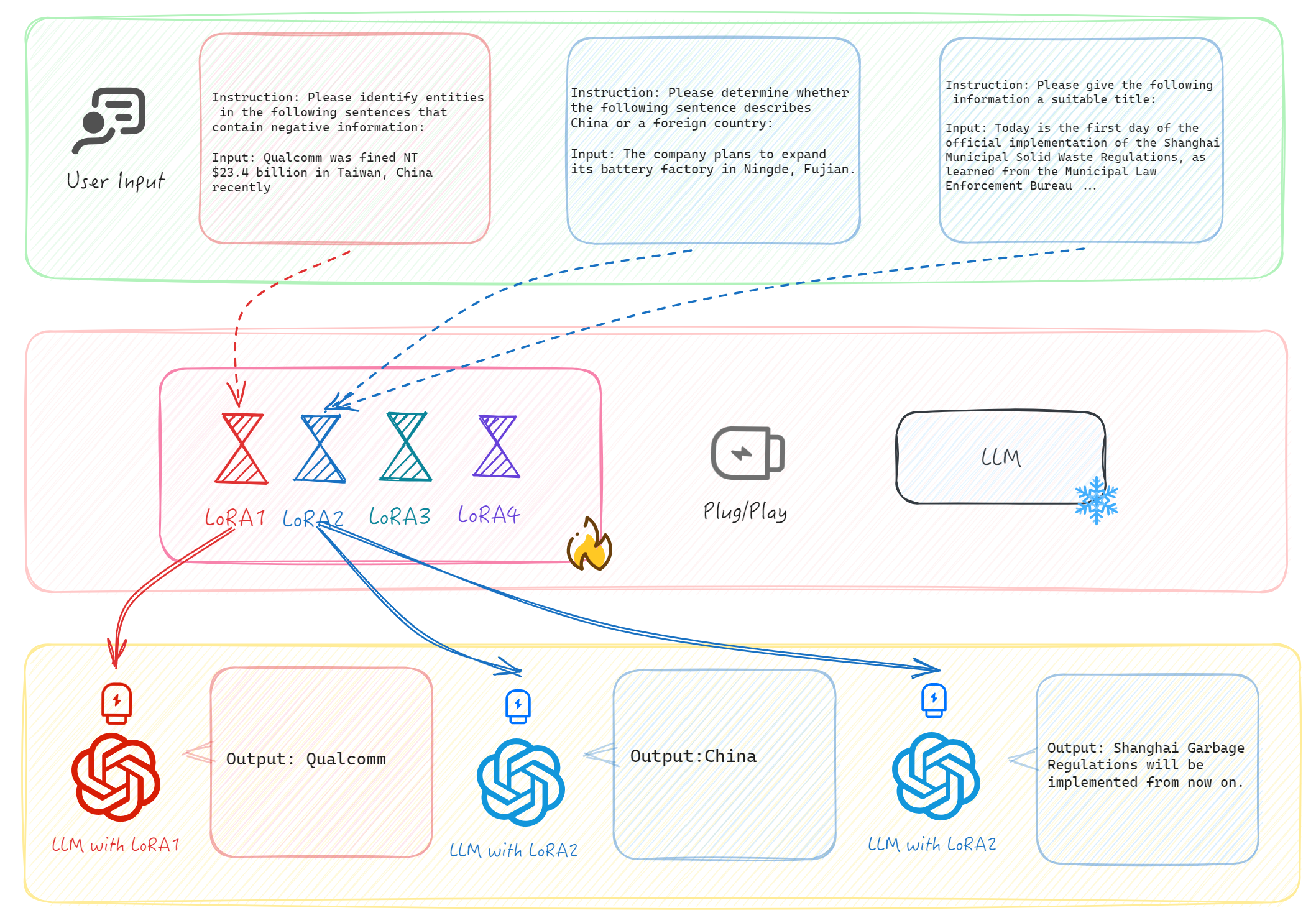
Large language models (LLMs) are increasingly being applied across various specialized fields, leveraging their extensive knowledge to empower a multitude of scenarios within these domains. However, each field encompasses a variety of specific tasks that require learning, and the diverse, heterogeneous data across these domains can lead to conflicts during model task transfer. In response to this challenge, our study introduces an Adaptive Semantic Space Learning (ASSL) framework, which utilizes the adaptive reorganization of data distributions within the semantic space to enhance the performance and selection efficacy of multi-expert models. Utilizing this framework, we trained a financial multi-task LLM named SilverSight. Our research findings demonstrate that our framework can achieve results close to those obtained with full data training using only 10% of the data, while also exhibiting strong generalization capabilities.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces SilverSight, a multi-task Chinese financial large language model (LLM) developed using adaptive semantic space learning.
- The model is designed to tackle various financial tasks in the Chinese language, such as financial question answering, financial sentiment analysis, and financial named entity recognition.
- The researchers employed a technique called LoRA (Low-Rank Adaptation) to efficiently fine-tune the model on the target tasks while preserving the knowledge acquired during pre-training.
Plain English Explanation
In this research paper, the authors present SilverSight, a powerful Chinese language model that can handle a wide range of financial tasks. Unlike general-purpose language models, SilverSight is specifically trained on financial data and can understand financial concepts and terminology very well.
The researchers used a technique called LoRA to fine-tune the model on various financial tasks, such as answering financial questions, analyzing financial sentiment, and recognizing financial entities. LoRA allows the model to learn the specific skills needed for these tasks without forgetting the general knowledge it gained during the initial pre-training process.
By developing SilverSight, the researchers aim to create a tool that can help financial professionals and enthusiasts in China better understand and navigate the complexities of the financial world. The model's ability to comprehend financial language and perform diverse financial tasks could be valuable for a wide range of applications, from financial analysis to customer support.
Technical Explanation
The paper first introduces the concept of LoRA, a technique used to efficiently fine-tune large language models on specific tasks while preserving the knowledge acquired during pre-training. This approach involves adding a small number of trainable parameters to the model, which can be learned quickly without significantly altering the pre-trained weights.
The researchers then describe the architecture of SilverSight, their multi-task Chinese financial LLM. They explain how they used LoRA to fine-tune the model on various financial tasks, including financial question answering, financial sentiment analysis, and financial named entity recognition. By leveraging LoRA, the authors were able to adapt the model to these specialized tasks without losing the general knowledge it had gained during the initial pre-training phase.
The paper presents the results of the researchers' experiments, which demonstrate the effectiveness of SilverSight in tackling the target financial tasks. The model outperformed several baseline systems, showcasing its strong understanding of financial concepts and its ability to generalize to different financial domains.
Critical Analysis
The paper provides a compelling approach to developing a specialized language model for the financial domain in the Chinese language. The use of LoRA to fine-tune the model on specific tasks is an efficient and effective strategy, as it allows the model to retain its broad knowledge while acquiring the necessary skills for the target applications.
However, the paper does not discuss the potential limitations or biases of the SilverSight model. It would be valuable to understand how the model performs on edge cases or under-represented financial scenarios, as well as any potential biases that may arise from the training data or the model architecture.
Additionally, the paper could have provided more insights into the model's interpretability and explainability. Understanding how SilverSight arrives at its predictions and decisions could be crucial for building trust and enabling human-in-the-loop applications in the financial domain.
Overall, the research presented in this paper is a valuable contribution to the field of specialized language models for financial applications. Further exploration of the model's limitations and the incorporation of interpretability and explainability features could strengthen the impact of this work.
Conclusion
The SilverSight model introduced in this paper represents a significant advancement in the development of Chinese financial language models. By leveraging the LoRA technique, the researchers were able to create a versatile model that can handle a variety of financial tasks with high accuracy.
The successful deployment of SilverSight could have far-reaching implications for the Chinese financial industry, enabling more efficient and accurate financial analysis, decision-making, and customer support. Additionally, the model's strong understanding of financial language and concepts could be valuable for educational and research purposes, helping to bridge the gap between financial professionals and the general public.
As the field of specialized language models continues to evolve, the SilverSight project serves as an inspiring example of how innovative techniques can be used to tailor large language models to specific domains and applications. This research paves the way for further advancements in the use of AI-powered tools to enhance our understanding and management of complex financial systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Do Large Language Model Understand Multi-Intent Spoken Language ?
Shangjian Yin, Peijie Huang, Yuhong Xu, Haojing Huang, Jiatian Chen
0
0
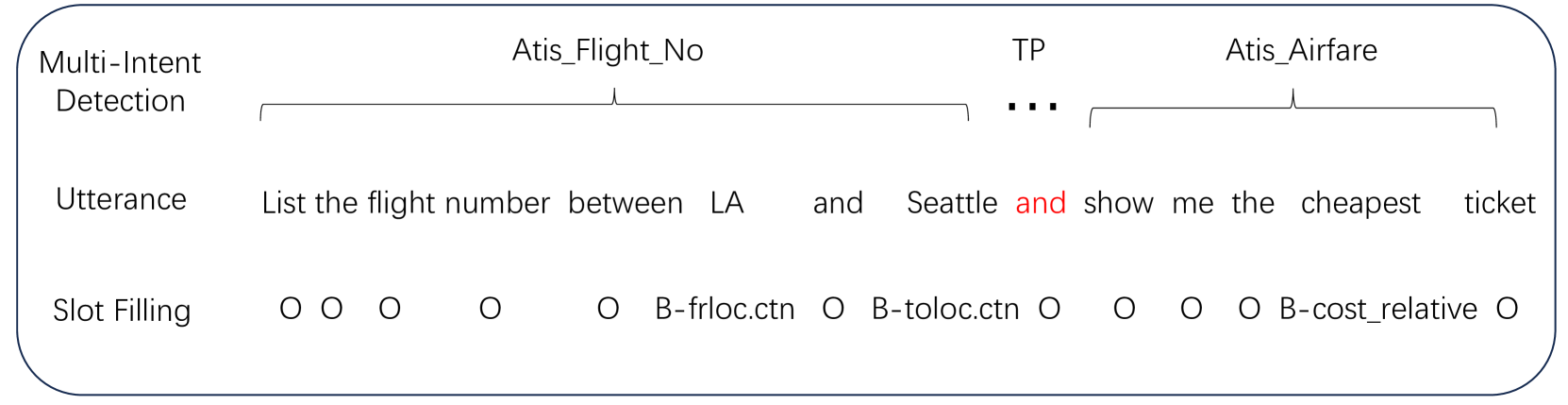
This research signifies a considerable breakthrough in leveraging Large Language Models (LLMs) for multi-intent spoken language understanding (SLU). Our approach re-imagines the use of entity slots in multi-intent SLU applications, making the most of the generative potential of LLMs within the SLU landscape, leading to the development of the EN-LLM series. Furthermore, we introduce the concept of Sub-Intent Instruction (SII) to amplify the analysis and interpretation of complex, multi-intent communications, which further supports the creation of the ENSI-LLM models series. Our novel datasets, identified as LM-MixATIS and LM-MixSNIPS, are synthesized from existing benchmarks. The study evidences that LLMs may match or even surpass the performance of the current best multi-intent SLU models. We also scrutinize the performance of LLMs across a spectrum of intent configurations and dataset distributions. On top of this, we present two revolutionary metrics - Entity Slot Accuracy (ESA) and Combined Semantic Accuracy (CSA) - to facilitate a detailed assessment of LLM competence in this multifaceted field. Our code and datasets are available at url{https://github.com/SJY8460/SLM}.
4/16/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024
NumLLM: Numeric-Sensitive Large Language Model for Chinese Finance
Huan-Yi Su, Ke Wu, Yu-Hao Huang, Wu-Jun Li
0
0
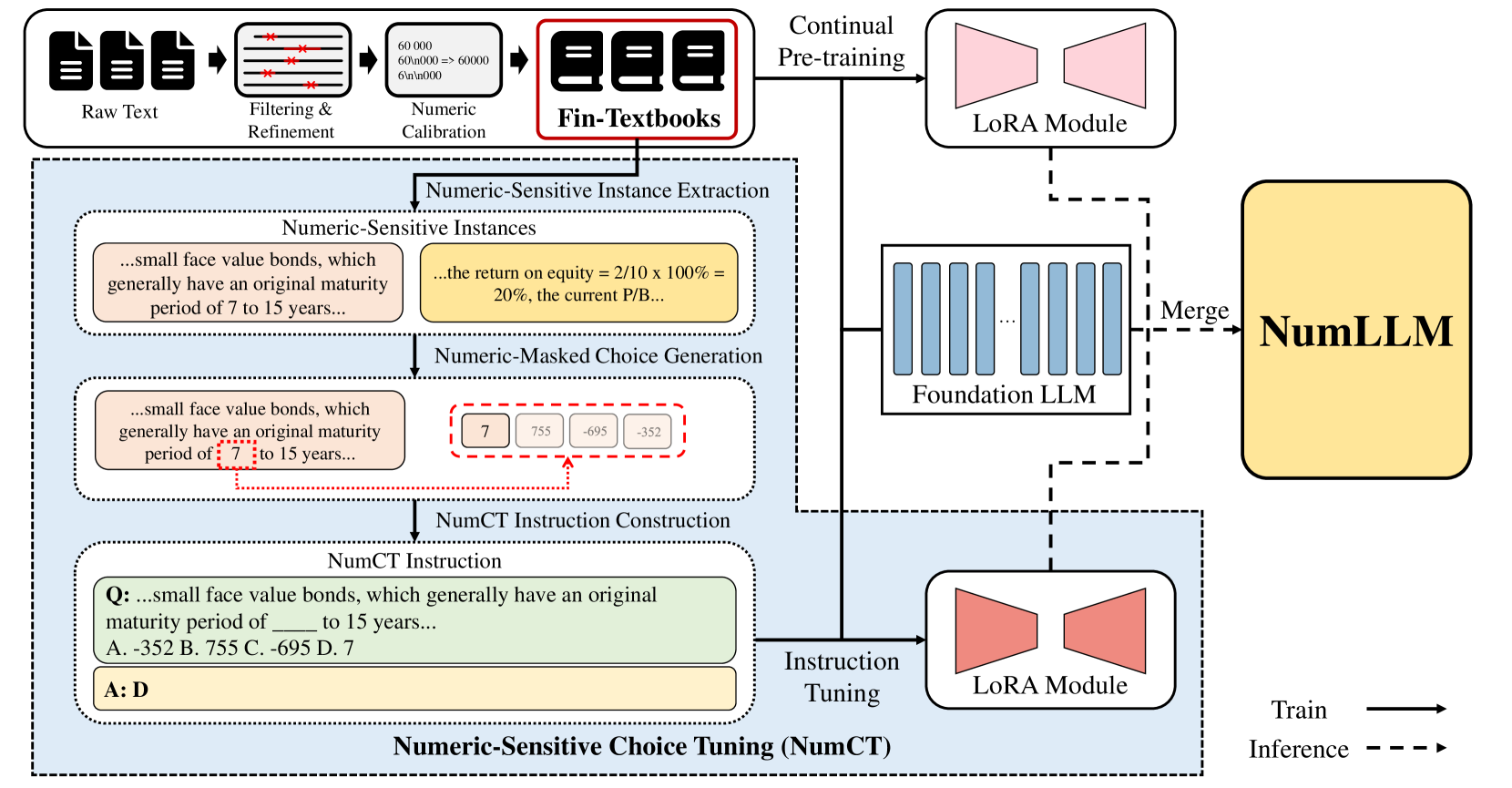
Recently, many works have proposed various financial large language models (FinLLMs) by pre-training from scratch or fine-tuning open-sourced LLMs on financial corpora. However, existing FinLLMs exhibit unsatisfactory performance in understanding financial text when numeric variables are involved in questions. In this paper, we propose a novel LLM, called numeric-sensitive large language model (NumLLM), for Chinese finance. We first construct a financial corpus from financial textbooks which is essential for improving numeric capability of LLMs during fine-tuning. After that, we train two individual low-rank adaptation (LoRA) modules by fine-tuning on our constructed financial corpus. One module is for adapting general-purpose LLMs to financial domain, and the other module is for enhancing the ability of NumLLM to understand financial text with numeric variables. Lastly, we merge the two LoRA modules into the foundation model to obtain NumLLM for inference. Experiments on financial question-answering benchmark show that NumLLM can boost the performance of the foundation model and can achieve the best overall performance compared to all baselines, on both numeric and non-numeric questions.
5/2/2024
🤿
Unveiling the Potential of LLM-Based ASR on Chinese Open-Source Datasets
Xuelong Geng, Tianyi Xu, Kun Wei, Bingshen Mu, Hongfei Xue, He Wang, Yangze Li, Pengcheng Guo, Yuhang Dai, Longhao Li, Mingchen Shao, Lei Xie
0
0
Large Language Models (LLMs) have demonstrated unparalleled effectiveness in various NLP tasks, and integrating LLMs with automatic speech recognition (ASR) is becoming a mainstream paradigm. Building upon this momentum, our research delves into an in-depth examination of this paradigm on a large open-source Chinese dataset. Specifically, our research aims to evaluate the impact of various configurations of speech encoders, LLMs, and projector modules in the context of the speech foundation encoder-LLM ASR paradigm. Furthermore, we introduce a three-stage training approach, expressly developed to enhance the model's ability to align auditory and textual information. The implementation of this approach, alongside the strategic integration of ASR components, enabled us to achieve the SOTA performance on the AISHELL-1, Test_Net, and Test_Meeting test sets. Our analysis presents an empirical foundation for future research in LLM-based ASR systems and offers insights into optimizing performance using Chinese datasets. We will publicly release all scripts used for data preparation, training, inference, and scoring, as well as pre-trained models and training logs to promote reproducible research.
5/7/2024