SimAD: A Simple Dissimilarity-based Approach for Time Series Anomaly Detection

0

Sign in to get full access
Overview
- This paper proposes a simple and effective time series anomaly detection method called SimAD.
- SimAD uses a dissimilarity-based approach to identify anomalies in time series data.
- The method is designed to be lightweight and easily interpretable, making it suitable for a variety of real-world applications.
Plain English Explanation
Time series data, such as stock prices or sensor readings, can sometimes contain unusual or unexpected values, known as anomalies. These anomalies can be important signals that indicate something important has happened, like a system failure or a market event. PatchAD: Lightweight Patch-Based MLP Mixer for Time Series Anomaly Detection and END-to-END Self-Tuning Self-Supervised Time Series Anomaly Detection are two recent approaches that use machine learning to detect these anomalies.
The SimAD method proposed in this paper takes a different approach. Instead of using complex machine learning models, SimAD looks at how similar each data point in the time series is to the others. If a data point is very different from the rest, it's likely an anomaly. This simple idea turns out to be an effective way to detect anomalies, and SimAD is designed to be easy to use and interpret, which is important for many real-world applications.
Technical Explanation
The key idea behind SimAD is to measure the dissimilarity between each data point in the time series and the rest of the data. CARLA: Self-Supervised Contrastive Representation Learning for Time Series Anomaly Detection and Position-Quo Vadis? Unsupervised Time Series Anomaly Detection have explored similar approaches. SimAD does this by calculating the Euclidean distance between each data point and the median of all the other data points. Data points with a high dissimilarity score are flagged as potential anomalies.
To make SimAD more robust, the authors also incorporate a sliding window approach, where the dissimilarity is calculated for each window of the time series. This helps capture both local and global anomalies. The authors also propose a method for automatically selecting the optimal window size based on the characteristics of the data.
Experiments on a range of real-world time series datasets show that SimAD performs competitively with state-of-the-art anomaly detection methods, while being much simpler and more interpretable. RESTAD: Reconstruction Similarity-based Transformer for Time Series Anomaly Detection is another recent method that also aims for interpretability.
Critical Analysis
One potential limitation of SimAD is that it assumes the time series data is stationary, meaning the statistical properties of the data do not change over time. In real-world scenarios, this assumption may not always hold true, and the method may struggle to detect anomalies in non-stationary data.
Additionally, SimAD relies on the Euclidean distance as the dissimilarity metric, which may not capture more complex patterns or relationships in the data. Alternative dissimilarity measures, such as dynamic time warping or cross-correlation, could potentially improve the method's performance on certain types of time series data.
The authors also acknowledge that SimAD may not be as effective at detecting anomalies in high-dimensional time series data, where the curse of dimensionality can make it challenging to define meaningful dissimilarity measures. Further research may be needed to address this limitation.
Conclusion
Overall, the SimAD method proposed in this paper offers a simple and effective approach to time series anomaly detection. By focusing on the dissimilarity between data points, rather than complex machine learning models, SimAD provides an interpretable and lightweight solution that can be easily applied to a variety of real-world problems. While the method has some limitations, it represents a promising direction for time series anomaly detection research, with potential applications in areas like predictive maintenance, fraud detection, and environmental monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SimAD: A Simple Dissimilarity-based Approach for Time Series Anomaly Detection
Zhijie Zhong, Zhiwen Yu, Xing Xi, Yue Xu, Jiahui Chen, Kaixiang Yang
Despite the prevalence of reconstruction-based deep learning methods, time series anomaly detection remains challenging. Existing approaches often struggle with limited temporal contexts, inadequate representation of normal patterns, and flawed evaluation metrics, hindering their effectiveness in identifying aberrant behavior. To address these issues, we introduce $textbf{{SimAD}}$, a $textbf{{Sim}}$ple dissimilarity-based approach for time series $textbf{{A}}$nomaly $textbf{{D}}$etection. SimAD incorporates an advanced feature extractor adept at processing extended temporal windows, utilizes the EmbedPatch encoder to integrate normal behavioral patterns comprehensively, and introduces an innovative ContrastFusion module designed to accentuate distributional divergences between normal and abnormal data, thereby enhancing the robustness of anomaly discrimination. Additionally, we propose two robust evaluation metrics, UAff and NAff, addressing the limitations of existing metrics and demonstrating their reliability through theoretical and experimental analyses. Experiments across $textbf{seven}$ diverse time series datasets demonstrate SimAD's superior performance compared to state-of-the-art methods, achieving relative improvements of $textbf{19.85%}$ on F1, $textbf{4.44%}$ on Aff-F1, $textbf{77.79%}$ on NAff-F1, and $textbf{9.69%}$ on AUC on six multivariate datasets. Code and pre-trained models are available at https://github.com/EmorZz1G/SimAD.
Read more5/21/2024

0
PatchAD: A Lightweight Patch-based MLP-Mixer for Time Series Anomaly Detection
Zhijie Zhong, Zhiwen Yu, Yiyuan Yang, Weizheng Wang, Kaixiang Yang
Anomaly detection in time series analysis is a pivotal task, yet it poses the challenge of discerning normal and abnormal patterns in label-deficient scenarios. While prior studies have largely employed reconstruction-based approaches, which limits the models' representational capacities. Moreover, existing deep learning-based methods are not sufficiently lightweight. Addressing these issues, we present PatchAD, our novel, highly efficient multiscale patch-based MLP-Mixer architecture that utilizes contrastive learning for representation extraction and anomaly detection. With its four distinct MLP Mixers and innovative dual project constraint module, PatchAD mitigates potential model degradation and offers a lightweight solution, requiring only $3.2$MB. Its efficacy is demonstrated by state-of-the-art results across $9$ datasets sourced from different application scenarios, outperforming over $30$ comparative algorithms. PatchAD significantly improves the classical F1 score by $50.5%$, the Aff-F1 score by $7.8%$, and the AUC by $10.0%$. The code is publicly available. url{https://github.com/EmorZz1G/PatchAD}
Read more5/29/2024
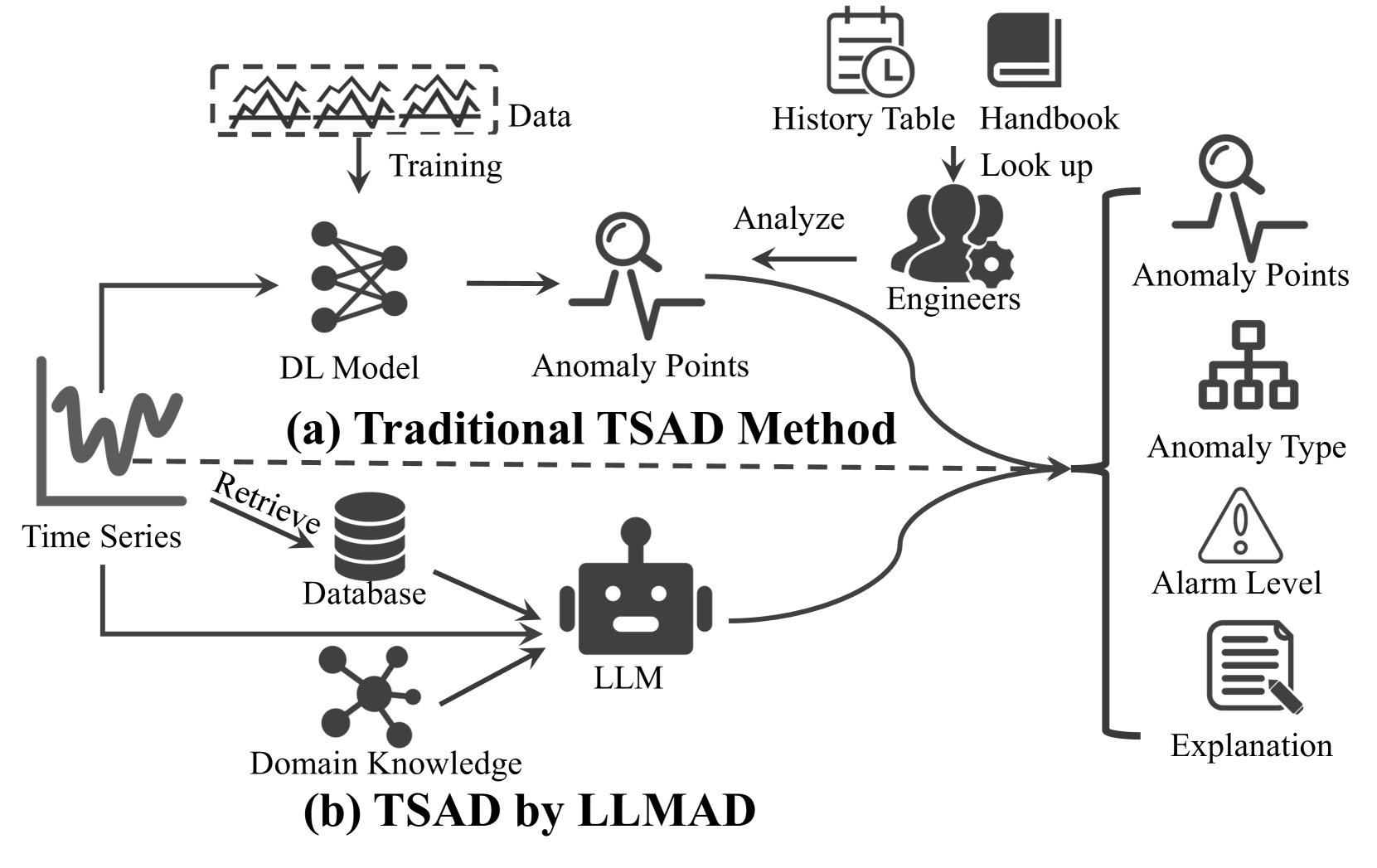
0
Large Language Models can Deliver Accurate and Interpretable Time Series Anomaly Detection
Jun Liu, Chaoyun Zhang, Jiaxu Qian, Minghua Ma, Si Qin, Chetan Bansal, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang
Time series anomaly detection (TSAD) plays a crucial role in various industries by identifying atypical patterns that deviate from standard trends, thereby maintaining system integrity and enabling prompt response measures. Traditional TSAD models, which often rely on deep learning, require extensive training data and operate as black boxes, lacking interpretability for detected anomalies. To address these challenges, we propose LLMAD, a novel TSAD method that employs Large Language Models (LLMs) to deliver accurate and interpretable TSAD results. LLMAD innovatively applies LLMs for in-context anomaly detection by retrieving both positive and negative similar time series segments, significantly enhancing LLMs' effectiveness. Furthermore, LLMAD employs the Anomaly Detection Chain-of-Thought (AnoCoT) approach to mimic expert logic for its decision-making process. This method further enhances its performance and enables LLMAD to provide explanations for their detections through versatile perspectives, which are particularly important for user decision-making. Experiments on three datasets indicate that our LLMAD achieves detection performance comparable to state-of-the-art deep learning methods while offering remarkable interpretability for detections. To the best of our knowledge, this is the first work that directly employs LLMs for TSAD.
Read more5/27/2024

0
Open-Set Multivariate Time-Series Anomaly Detection
Thomas Lai, Thi Kieu Khanh Ho, Narges Armanfard
Numerous methods for time-series anomaly detection (TSAD) have emerged in recent years, most of which are unsupervised and assume that only normal samples are available during the training phase, due to the challenge of obtaining abnormal data in real-world scenarios. Still, limited samples of abnormal data are often available, albeit they are far from representative of all possible anomalies. Supervised methods can be utilized to classify normal and seen anomalies, but they tend to overfit to the seen anomalies present during training, hence, they fail to generalize to unseen anomalies. We propose the first algorithm to address the open-set TSAD problem, called Multivariate Open-Set Time-Series Anomaly Detector (MOSAD), that leverages only a few shots of labeled anomalies during the training phase in order to achieve superior anomaly detection performance compared to both supervised and unsupervised TSAD algorithms. MOSAD is a novel multi-head TSAD framework with a shared representation space and specialized heads, including the Generative head, the Discriminative head, and the Anomaly-Aware Contrastive head. The latter produces a superior representation space for anomaly detection compared to conventional supervised contrastive learning. Extensive experiments on three real-world datasets establish MOSAD as a new state-of-the-art in the TSAD field.
Read more8/9/2024