On the Similarity of Deep Learning Representations Across Didactic and Adversarial Examples

0
🤿
Sign in to get full access
Overview
- Deep neural networks (DNNs) have become increasingly popular, leading to the development of adversarial examples that can trick these models.
- Not all adversarial examples are malicious - real-world systems often have variability due to physical, temporal, and sampling factors.
- Naturally occurring variations in image features can also serve educational purposes.
- This study examines the stability of deep learning representations for neuroimaging classification under both didactic and adversarial conditions related to MRI acquisition variability.
- The findings show that representational similarity and performance depend on the frequency of adversarial examples in the input space.
Plain English Explanation
Deep learning models, such as deep neural networks (DNNs), have become very powerful at tasks like image classification. However, researchers have discovered that these models can be "tricked" by adversarial examples - slightly modified inputs that cause the model to misclassify them.
While some adversarial examples are intentionally created to exploit vulnerabilities in the models, not all adversarial examples are malicious. In the real world, the data that models see can vary due to factors like equipment variability, changes over time, and differences in how the data is collected. This natural variability can also create "accidental" adversarial examples that could negatively impact the model's accuracy.
Interestingly, this same natural variability in the data can sometimes serve an educational purpose, helping researchers understand how the models work. By analyzing how the models' representations (the internal patterns they learn) change in response to different types of variations, researchers can gain insights into the models' strengths and weaknesses.
In this study, the researchers looked at how the representations and performance of deep learning models for neuroimaging (brain imaging) classification are affected by both intentional adversarial examples and naturally occurring variations related to MRI (magnetic resonance imaging) data collection. They found that the stability of the representations and the models' performance depended on the frequency of these adversarial-like examples in the input data.
Technical Explanation
The researchers conducted experiments to study the stability of deep learning representations for neuroimaging classification under both didactic (educational) and adversarial conditions related to MRI acquisition variability.
They used a dataset of MRI scans and trained deep learning models to classify the images. To simulate real-world variability, they introduced different types of perturbations to the images, such as changes in image contrast, orientation, and noise. Some of these perturbations were designed to be intentionally adversarial, while others represented natural variations in the data.
The researchers then analyzed how the internal representations (the patterns learned by the models) changed in response to these different types of variations. They measured the representational similarity between the original and perturbed representations, as well as the models' classification performance.
The key finding was that the stability of the representations and the models' performance depended on the frequency of adversarial-like examples in the input data. When there were more adversarial-like variations present, the representations became less stable, and the models' performance declined. Conversely, when the variations were more "natural" and less adversarial, the representations were more stable, and the models performed better.
Critical Analysis
The paper highlights an important aspect of deep learning that is often overlooked: the impact of real-world data variability on model performance. While much research has focused on intentionally crafted adversarial examples, this study shows that natural variations in the data can also create adversarial-like conditions that can degrade model performance.
One limitation of the study is that it focuses only on neuroimaging data and classification tasks. It would be valuable to see if similar findings hold true for other domains and types of deep learning models, such as facial recognition or algorithm selection.
Additionally, the paper does not delve into the specific mechanisms by which the different types of variations affect the models' representations and performance. Further research could explore the underlying reasons for these effects, which could lead to the development of more robust and generalizable deep learning models.
Conclusion
This study demonstrates the importance of considering the impact of real-world data variability on the performance of deep learning models. The researchers found that the stability of the models' representations and their classification accuracy depend on the frequency of adversarial-like examples in the input data, highlighting the need to account for natural variations in addition to intentionally crafted adversarial examples.
These findings have implications for the deployment of deep learning systems in real-world applications, where the data may not be as clean and controlled as in laboratory settings. By understanding the factors that influence model stability and performance, researchers and practitioners can develop more robust and reliable deep learning solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
New!On the Similarity of Deep Learning Representations Across Didactic and Adversarial Examples
Pk Douglas, Farzad Vasheghani Farahani
The increasing use of deep neural networks (DNNs) has motivated a parallel endeavor: the design of adversaries that profit from successful misclassifications. However, not all adversarial examples are crafted for malicious purposes. For example, real world systems often contain physical, temporal, and sampling variability across instrumentation. Adversarial examples in the wild may inadvertently prove deleterious for accurate predictive modeling. Conversely, naturally occurring covariance of image features may serve didactic purposes. Here, we studied the stability of deep learning representations for neuroimaging classification across didactic and adversarial conditions characteristic of MRI acquisition variability. We show that representational similarity and performance vary according to the frequency of adversarial examples in the input space.
Read more9/18/2024
🤿
0
A Survey on Transferability of Adversarial Examples across Deep Neural Networks
Jindong Gu, Xiaojun Jia, Pau de Jorge, Wenqain Yu, Xinwei Liu, Avery Ma, Yuan Xun, Anjun Hu, Ashkan Khakzar, Zhijiang Li, Xiaochun Cao, Philip Torr
The emergence of Deep Neural Networks (DNNs) has revolutionized various domains by enabling the resolution of complex tasks spanning image recognition, natural language processing, and scientific problem-solving. However, this progress has also brought to light a concerning vulnerability: adversarial examples. These crafted inputs, imperceptible to humans, can manipulate machine learning models into making erroneous predictions, raising concerns for safety-critical applications. An intriguing property of this phenomenon is the transferability of adversarial examples, where perturbations crafted for one model can deceive another, often with a different architecture. This intriguing property enables black-box attacks which circumvents the need for detailed knowledge of the target model. This survey explores the landscape of the adversarial transferability of adversarial examples. We categorize existing methodologies to enhance adversarial transferability and discuss the fundamental principles guiding each approach. While the predominant body of research primarily concentrates on image classification, we also extend our discussion to encompass other vision tasks and beyond. Challenges and opportunities are discussed, highlighting the importance of fortifying DNNs against adversarial vulnerabilities in an evolving landscape.
Read more5/3/2024
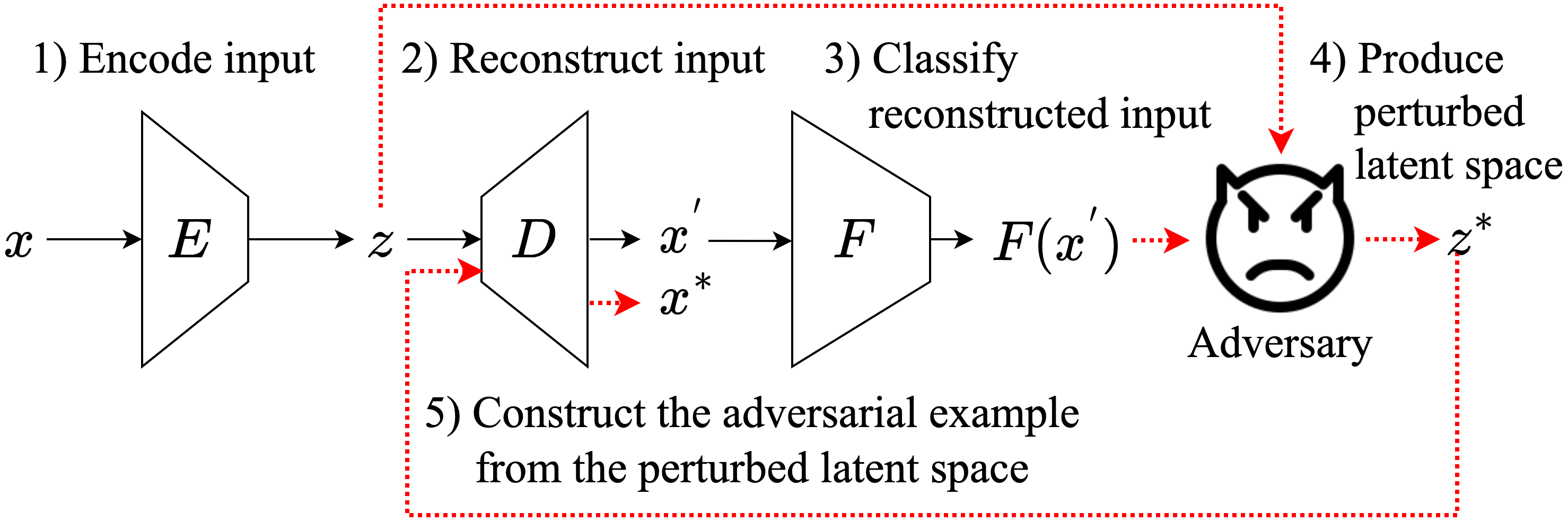
0
On Adversarial Examples for Text Classification by Perturbing Latent Representations
Korn Sooksatra, Bikram Khanal, Pablo Rivas
Recently, with the advancement of deep learning, several applications in text classification have advanced significantly. However, this improvement comes with a cost because deep learning is vulnerable to adversarial examples. This weakness indicates that deep learning is not very robust. Fortunately, the input of a text classifier is discrete. Hence, it can prevent the classifier from state-of-the-art attacks. Nonetheless, previous works have generated black-box attacks that successfully manipulate the discrete values of the input to find adversarial examples. Therefore, instead of changing the discrete values, we transform the input into its embedding vector containing real values to perform the state-of-the-art white-box attacks. Then, we convert the perturbed embedding vector back into a text and name it an adversarial example. In summary, we create a framework that measures the robustness of a text classifier by using the gradients of the classifier.
Read more5/8/2024

0
Evaluating the Robustness of Deep-Learning Algorithm-Selection Models by Evolving Adversarial Instances
Emma Hart, Quentin Renau, Kevin Sim, Mohamad Alissa
Deep neural networks (DNN) are increasingly being used to perform algorithm-selection in combinatorial optimisation domains, particularly as they accommodate input representations which avoid designing and calculating features. Mounting evidence from domains that use images as input shows that deep convolutional networks are vulnerable to adversarial samples, in which a small perturbation of an instance can cause the DNN to misclassify. However, it remains unknown as to whether deep recurrent networks (DRN) which have recently been shown promise as algorithm-selectors in the bin-packing domain are equally vulnerable. We use an evolutionary algorithm (EA) to find perturbations of instances from two existing benchmarks for online bin packing that cause trained DRNs to misclassify: adversarial samples are successfully generated from up to 56% of the original instances depending on the dataset. Analysis of the new misclassified instances sheds light on the `fragility' of some training instances, i.e. instances where it is trivial to find a small perturbation that results in a misclassification and the factors that influence this. Finally, the method generates a large number of new instances misclassified with a wide variation in confidence, providing a rich new source of training data to create more robust models.
Read more6/26/2024