Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
2310.06694
0
0
💬
Abstract
The popularity of LLaMA (Touvron et al., 2023a;b) and other recently emerged moderate-sized large language models (LLMs) highlights the potential of building smaller yet powerful LLMs. Regardless, the cost of training such models from scratch on trillions of tokens remains high. In this work, we study structured pruning as an effective means to develop smaller LLMs from pre-trained, larger models. Our approach employs two key techniques: (1) targeted structured pruning, which prunes a larger model to a specified target shape by removing layers, heads, and intermediate and hidden dimensions in an end-to-end manner, and (2) dynamic batch loading, which dynamically updates the composition of sampled data in each training batch based on varying losses across different domains. We demonstrate the efficacy of our approach by presenting the Sheared-LLaMA series, pruning the LLaMA2-7B model down to 1.3B and 2.7B parameters. Sheared-LLaMA models outperform state-of-the-art open-source models of equivalent sizes, such as Pythia, INCITE, OpenLLaMA and the concurrent TinyLlama models, on a wide range of downstream and instruction tuning evaluations, while requiring only 3% of compute compared to training such models from scratch. This work provides compelling evidence that leveraging existing LLMs with structured pruning is a far more cost-effective approach for building competitive small-scale LLMs
Create account to get full access
Overview
- The popularity of LLaMA and other moderate-sized language models highlights the potential of building smaller yet powerful models.
- Training such models from scratch on trillions of tokens remains costly.
- This work explores structured pruning as a way to develop smaller language models from pre-trained, larger models.
- The approach uses two key techniques: targeted structured pruning and dynamic batch loading.
- The result is the Sheared-LLaMA series, which outperforms state-of-the-art open-source models of equivalent size while requiring only 3% of the compute.
Plain English Explanation
The paper focuses on developing smaller, yet powerful, language models. Large language models (LLMs) like LLaMA have shown great potential, but training them from scratch requires enormous computational resources.
The researchers explore a more efficient approach - taking a larger, pre-trained model and
The key innovations are:
- Targeted Structured Pruning: This prunes the model in an end-to-end manner, removing specific components to reach a target model size.
- Dynamic Batch Loading: This dynamically updates the training data in each batch, focusing on areas where the model is struggling the most.
By applying these techniques, the researchers created the "Sheared-LLaMA" series - smaller versions of the LLaMA model that outperform other compact, open-source models on a range of tasks. Crucially, these Sheared-LLaMA models only require 3% of the compute needed to train a similar-sized model from scratch.
Technical Explanation
The paper presents a structured pruning approach to develop smaller yet powerful language models from larger, pre-trained models.
The key techniques are:
-
Targeted Structured Pruning: This method prunes a larger model to a specified target shape by removing layers, attention heads, and intermediate/hidden dimensions in an end-to-end manner. This allows for more fine-grained control over the model's architecture compared to unstructured pruning.
-
Dynamic Batch Loading: This dynamically updates the composition of training data in each batch based on the varying losses across different domains. This helps the model focus on areas where it is struggling the most during fine-tuning.
The researchers apply these techniques to prune the LLaMA2-7B model down to 1.3B and 2.7B parameter versions, creating the "Sheared-LLaMA" series. These pruned models outperform state-of-the-art open-source models of equivalent size, such as Pythia, INCITE, OpenLLaMA, and the concurrent TinyLlama models, on a wide range of downstream and instruction-tuning evaluations.
Crucially, the Sheared-LLaMA models only require 3% of the compute needed to train such models from scratch, making this a far more cost-effective approach for building competitive small-scale language models.
Critical Analysis
The paper presents a compelling approach to developing smaller yet powerful language models by leveraging existing large models through structured pruning. The use of targeted pruning and dynamic batch loading are innovative techniques that allow for fine-grained control over the model architecture and training process.
One potential limitation is that the paper only evaluates the Sheared-LLaMA models on a relatively narrow set of downstream tasks. It would be valuable to see how these models perform on a wider range of real-world applications, especially those that require more nuanced language understanding.
Additionally, the paper does not delve into the interpretability or explainability of the pruned models. As these smaller models are intended for deployment in real-world scenarios, understanding their inner workings and decision-making processes could be an important area for future research.
Finally, while the compute savings are substantial, the paper does not provide a detailed cost analysis or discussion of the environmental impact of this approach compared to training smaller models from scratch. As the field of AI continues to grapple with issues of sustainability, these considerations will become increasingly important.
Overall, this work represents a promising step towards more efficient and accessible language models, but further research is needed to fully understand the broader implications and potential limitations of this approach.
Conclusion
This paper presents a structured pruning approach to developing smaller yet powerful language models from larger, pre-trained models. By employing targeted pruning and dynamic batch loading techniques, the researchers were able to create the Sheared-LLaMA series, which outperforms state-of-the-art open-source models of equivalent size while requiring only a fraction of the compute needed to train such models from scratch.
This work highlights the potential of leveraging existing large language models to build more cost-effective and accessible smaller-scale models, which could have significant implications for the democratization of AI technology and its broader societal impact. As the field continues to grapple with issues of model size, efficiency, and sustainability, this research provides a compelling example of how innovation in model architecture and training can lead to more practical and impactful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Optimization-based Structural Pruning for Large Language Models without Back-Propagation
Yuan Gao, Zujing Liu, Weizhong Zhang, Bo Du, Gui-Song Xia
0
0
Compared to the moderate size of neural network models, structural weight pruning on the Large-Language Models (LLMs) imposes a novel challenge on the efficiency of the pruning algorithms, due to the heavy computation/memory demands of the LLMs. Recent efficient LLM pruning methods typically operate at the post-training phase without the expensive weight finetuning, however, their pruning criteria often rely on heuristically designed metrics, potentially leading to suboptimal performance. We instead propose a novel optimization-based structural pruning that learns the pruning masks in a probabilistic space directly by optimizing the loss of the pruned model. To preserve the efficiency, our method 1) works at post-training phase} and 2) eliminates the back-propagation through the LLM per se during the optimization (i.e., only requires the forward pass of the LLM). We achieve this by learning an underlying Bernoulli distribution to sample binary pruning masks, where we decouple the Bernoulli parameters from the LLM loss, thus facilitating an efficient optimization via a policy gradient estimator without back-propagation. As a result, our method is able to 1) operate at structural granularities of channels, heads, and layers, 2) support global and heterogeneous pruning (i.e., our method automatically determines different redundancy for different layers), and 3) optionally use a metric-based method as initialization (of our Bernoulli distributions). Extensive experiments on LLaMA, LLaMA-2, and Vicuna using the C4 and WikiText2 datasets demonstrate that our method operates for 2.7 hours with around 35GB memory for the 13B models on a single A100 GPU, and our pruned models outperform the state-of-the-arts w.r.t. perplexity. Codes will be released.
6/18/2024

Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang
0
0
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
5/16/2024
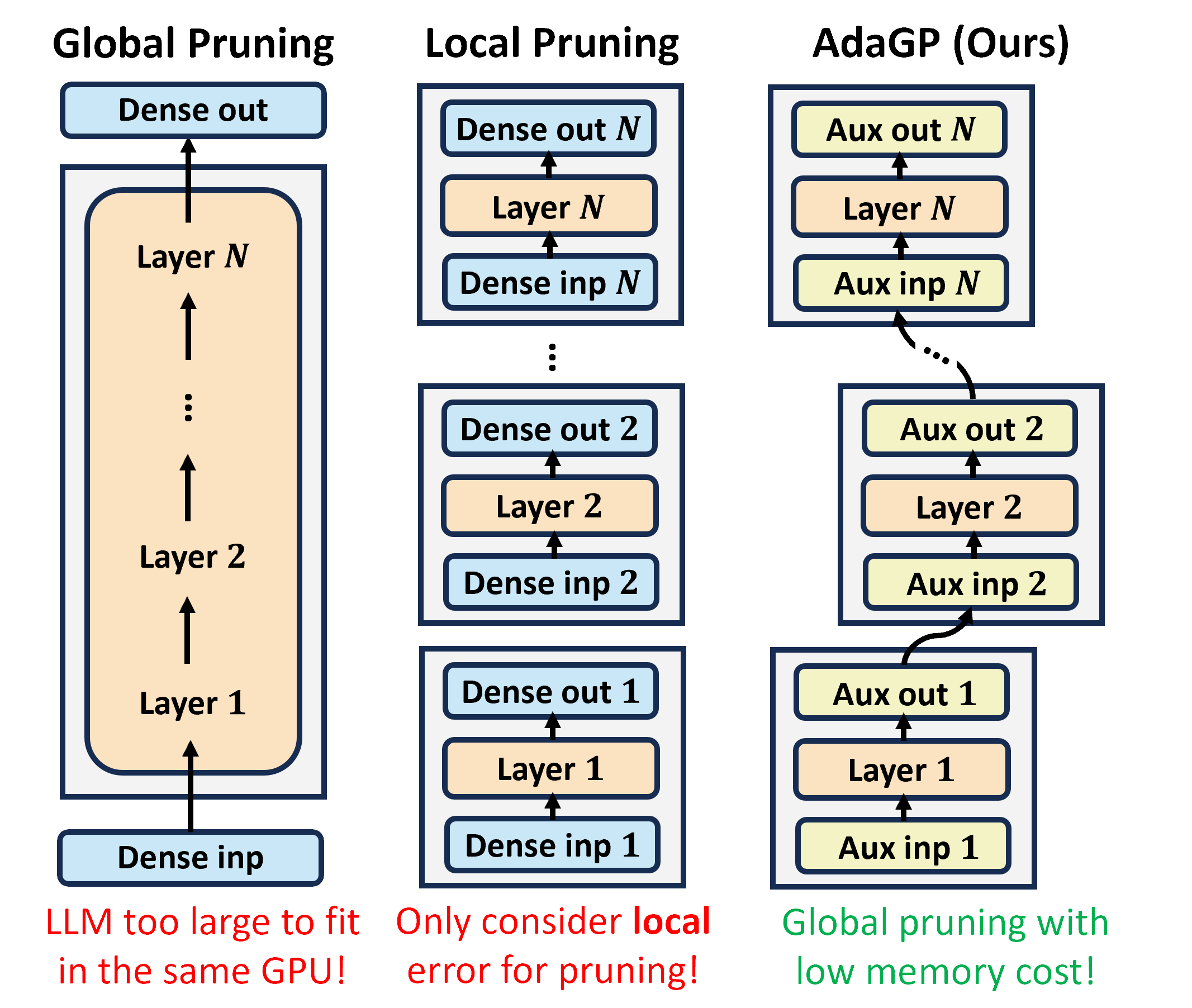
SparseLLM: Towards Global Pruning for Pre-trained Language Models
Guangji Bai, Yijiang Li, Chen Ling, Kibaek Kim, Liang Zhao
0
0
The transformative impact of large language models (LLMs) like LLaMA and GPT on natural language processing is countered by their prohibitive computational demands. Pruning has emerged as a pivotal compression strategy, introducing sparsity to enhance both memory and computational efficiency. Yet, traditional global pruning is impractical for LLMs due to scalability issues, while local pruning, despite its efficiency, leads to suboptimal solutions. Addressing these challenges, we propose SparseLLM, a novel framework that redefines the global pruning process into manageable, coordinated subproblems, allowing for resource-efficient optimization with global optimality. SparseLLM's approach, which conceptualizes LLMs as a chain of modular functions and leverages auxiliary variables for problem decomposition, not only facilitates a pragmatic application on LLMs but also demonstrates significant performance improvements, particularly in high-sparsity regimes where it surpasses current state-of-the-art methods.
5/27/2024
💬
New!Shortened LLaMA: Depth Pruning for Large Language Models with Comparison of Retraining Methods
Bo-Kyeong Kim, Geonmin Kim, Tae-Ho Kim, Thibault Castells, Shinkook Choi, Junho Shin, Hyoung-Kyu Song
0
0
Structured pruning of modern large language models (LLMs) has emerged as a way of decreasing their high computational needs. Width pruning reduces the size of projection weight matrices (e.g., by removing attention heads) while maintaining the number of layers. Depth pruning, in contrast, removes entire layers or blocks, while keeping the size of the remaining weights unchanged. Most current research focuses on either width-only or a blend of width and depth pruning, with little comparative analysis between the two units (width vs. depth) concerning their impact on LLM inference efficiency. In this work, we show that simple depth pruning can effectively compress LLMs while achieving comparable or superior performance to recent width pruning studies. Our pruning method boosts inference speeds, especially under memory-constrained conditions that require limited batch sizes for running LLMs, where width pruning is ineffective. In retraining pruned models for quality recovery, continued pretraining on a large corpus markedly outperforms LoRA-based tuning, particularly at severe pruning ratios. We hope this work can help build compact yet capable LLMs. Code and models can be found at: https://github.com/Nota-NetsPresso/shortened-llm
6/26/2024