BESA: Pruning Large Language Models with Blockwise Parameter-Efficient Sparsity Allocation
2402.16880
0
0

Abstract
Large language models (LLMs) have demonstrated outstanding performance in various tasks, such as text summarization, text question-answering, and etc. While their performance is impressive, the computational footprint due to their vast number of parameters can be prohibitive. Existing solutions such as SparseGPT and Wanda attempt to alleviate this issue through weight pruning. However, their layer-wise approach results in significant perturbation to the model's output and requires meticulous hyperparameter tuning, such as the pruning rate, which can adversely affect overall model performance. To address this, this paper introduces a novel LLM pruning technique dubbed blockwise parameter-efficient sparsity allocation (BESA) by applying a blockwise reconstruction loss. In contrast to the typical layer-wise pruning techniques, BESA is characterized by two distinctive attributes: i) it targets the overall pruning error with respect to individual transformer blocks, and ii) it allocates layer-specific sparsity in a differentiable manner, both of which ensure reduced performance degradation after pruning. Our experiments show that BESA achieves state-of-the-art performance, efficiently pruning LLMs like LLaMA1, and LLaMA2 with 7B to 70B parameters on a single A100 GPU in just five hours. Code is available at https://github.com/OpenGVLab/LLMPrune-BESA.
Create account to get full access
Overview
- This paper presents a novel pruning technique called BESA (Blockwise Parameter-Efficient Sparsity Allocation) for large language models.
- BESA aims to reduce the model size and inference latency while preserving performance by selectively pruning parameters in a block-structured manner.
- The paper explores the impact of different sparsity patterns on the model's performance and efficiency, providing insights into the relationship between parameter pruning and model behavior.
Plain English Explanation
The research paper describes a new way to compress large language models by removing unnecessary components, called "pruning." The goal is to make the models smaller and faster to run, without losing too much of their original capabilities.
The key idea behind this new pruning technique, called BESA, is to remove parameters (the numbers that define how the model works) in a specific, organized way. Instead of randomly removing parameters, BESA identifies blocks or groups of parameters that can be safely removed without significantly hurting the model's performance.
This block-structured approach to pruning is more efficient than previous methods, as it allows the model to maintain important relationships between different parts of the language model. By preserving these connections, the pruned model can still perform well on various language tasks, even though it's smaller and faster.
The paper also explores how different patterns of parameter removal, or "sparsity patterns," can impact the model's performance and efficiency. This provides valuable insights into the complex relationship between the model's internal structure and its overall capabilities.
Technical Explanation
The BESA pruning technique works by identifying blocks or groups of parameters within the large language model that can be safely removed without significantly degrading the model's performance. This is in contrast to previous pruning methods that removed parameters in a more unstructured, random way.
The key innovation of BESA is its block-structured approach to parameter pruning. Instead of removing individual parameters, BESA identifies larger blocks of parameters that can be pruned together, preserving the important relationships between different parts of the language model. This helps maintain the model's overall capabilities while reducing its size and inference latency.
The paper explores the impact of different sparsity patterns, or ways of distributing the removed parameters, on the model's performance and efficiency. By experimenting with various sparsity patterns, the researchers gain insights into the complex interplay between the model's internal structure and its overall behavior.
This research builds on previous work in model compression and sparse training, providing a novel approach to pruning large language models while maintaining their inference efficiency.
Critical Analysis
The paper presents a compelling approach to pruning large language models, but it's important to consider some potential limitations and areas for further research:
-
Generalization to different model architectures: The experiments in the paper are conducted on the GPT-2 model, and it's unclear how well the BESA technique would perform on other large language model architectures, such as BERT or GPT-3. Further research is needed to assess the broader applicability of BESA.
-
Impact on fine-tuning and downstream tasks: The paper focuses on the performance of the pruned models on the original language modeling task, but it's important to understand how the pruning affects the models' capabilities when fine-tuned for specific downstream applications.
-
Interpretability and explainability: While the paper provides insights into the relationship between sparsity patterns and model performance, it would be valuable to have a deeper understanding of the underlying mechanisms and the rationale behind the BESA pruning decisions.
-
Computational efficiency of the pruning process: The paper does not fully address the computational complexity and time requirements of the BESA pruning algorithm, which could be an important factor in real-world deployment scenarios.
Overall, the BESA pruning technique presents a promising approach to reducing the size and inference latency of large language models while preserving their performance. Further research and development in this area could lead to significant advances in the efficient deployment of these powerful AI models.
Conclusion
The BESA pruning method introduced in this paper offers a novel way to compress large language models by selectively removing parameters in a block-structured manner. This approach helps maintain the models' overall capabilities while reducing their size and inference latency, making them more practical for real-world applications.
The paper's exploration of different sparsity patterns and their impact on model performance provides valuable insights into the complex relationship between a language model's internal structure and its behavior. These insights can inform future research and development efforts in the area of efficient model compression and deployment.
As large language models continue to grow in size and complexity, techniques like BESA will become increasingly important for making these powerful AI systems more accessible and practical for a wide range of users and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
SLEB: Streamlining LLMs through Redundancy Verification and Elimination of Transformer Blocks
Jiwon Song, Kyungseok Oh, Taesu Kim, Hyungjun Kim, Yulhwa Kim, Jae-Joon Kim
0
0
Large language models (LLMs) have proven to be highly effective across various natural language processing tasks. However, their large number of parameters poses significant challenges for practical deployment. Pruning, a technique aimed at reducing the size and complexity of LLMs, offers a potential solution by removing redundant components from the network. Despite the promise of pruning, existing methods often struggle to achieve substantial end-to-end LLM inference speedup. In this paper, we introduce SLEB, a novel approach designed to streamline LLMs by eliminating redundant transformer blocks. We choose the transformer block as the fundamental unit for pruning, because LLMs exhibit block-level redundancy with high similarity between the outputs of neighboring blocks. This choice allows us to effectively enhance the processing speed of LLMs. Our experimental results demonstrate that SLEB outperforms previous LLM pruning methods in accelerating LLM inference while also maintaining superior perplexity and accuracy, making SLEB as a promising technique for enhancing the efficiency of LLMs. The code is available at: https://github.com/jiwonsong-dev/SLEB.
6/13/2024
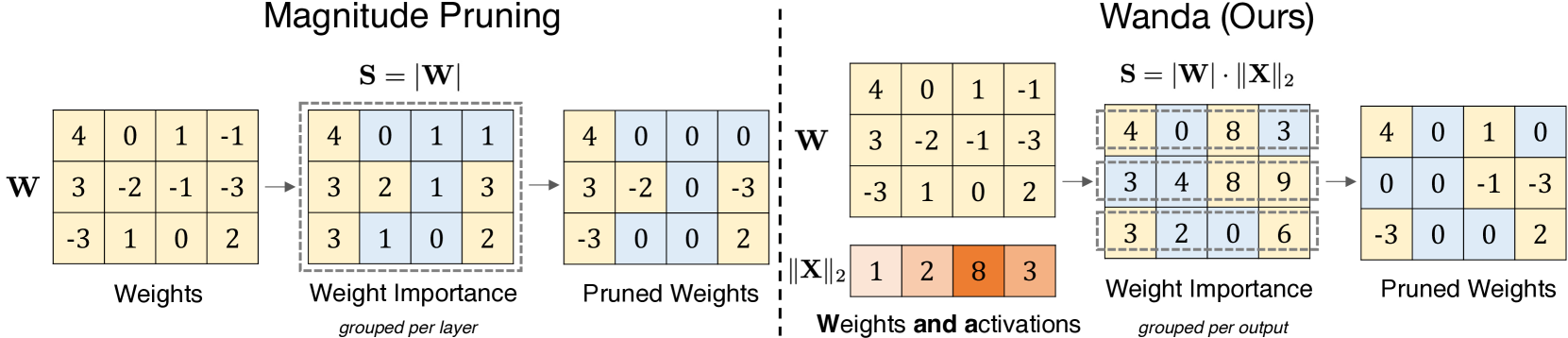
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, J. Zico Kolter
0
0
As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance. Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive. In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prunes weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method Wanda on LLaMA and LLaMA-2 across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and performs competitively against recent method involving intensive weight update. Code is available at https://github.com/locuslab/wanda.
5/7/2024
💬
One-Shot Sensitivity-Aware Mixed Sparsity Pruning for Large Language Models
Hang Shao, Bei Liu, Bo Xiao, Ke Zeng, Guanglu Wan, Yanmin Qian
0
0
Various Large Language Models~(LLMs) from the Generative Pretrained Transformer(GPT) family have achieved outstanding performances in a wide range of text generation tasks. However, the enormous model sizes have hindered their practical use in real-world applications due to high inference latency. Therefore, improving the efficiencies of LLMs through quantization, pruning, and other means has been a key issue in LLM studies. In this work, we propose a method based on Hessian sensitivity-aware mixed sparsity pruning to prune LLMs to at least 50% sparsity without the need of any retraining. It allocates sparsity adaptively based on sensitivity, allowing us to reduce pruning-induced error while maintaining the overall sparsity level. The advantages of the proposed method exhibit even more when the sparsity is extremely high. Furthermore, our method is compatible with quantization, enabling further compression of LLMs. We have released the available code.
4/24/2024
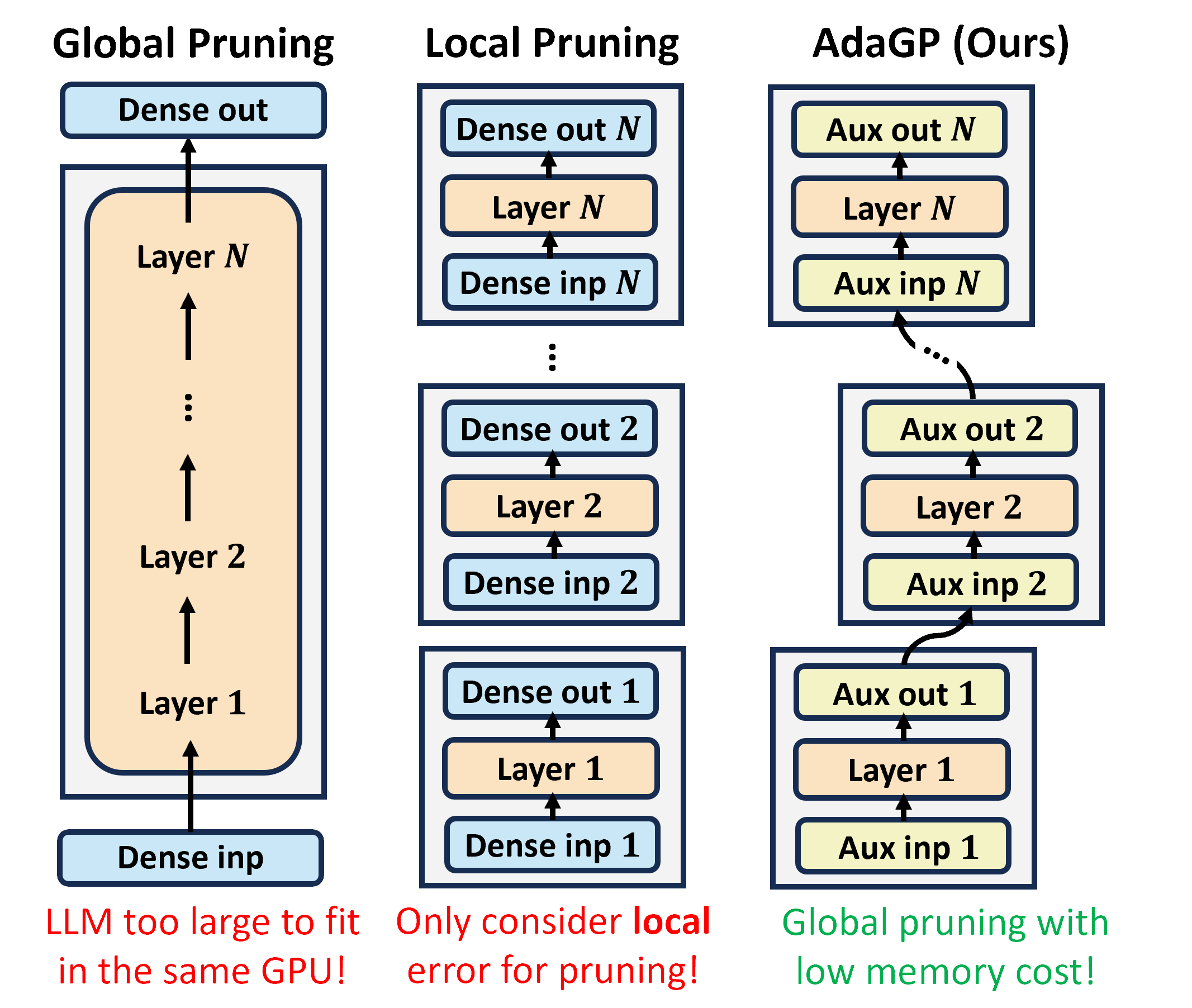
SparseLLM: Towards Global Pruning for Pre-trained Language Models
Guangji Bai, Yijiang Li, Chen Ling, Kibaek Kim, Liang Zhao
0
0
The transformative impact of large language models (LLMs) like LLaMA and GPT on natural language processing is countered by their prohibitive computational demands. Pruning has emerged as a pivotal compression strategy, introducing sparsity to enhance both memory and computational efficiency. Yet, traditional global pruning is impractical for LLMs due to scalability issues, while local pruning, despite its efficiency, leads to suboptimal solutions. Addressing these challenges, we propose SparseLLM, a novel framework that redefines the global pruning process into manageable, coordinated subproblems, allowing for resource-efficient optimization with global optimality. SparseLLM's approach, which conceptualizes LLMs as a chain of modular functions and leverages auxiliary variables for problem decomposition, not only facilitates a pragmatic application on LLMs but also demonstrates significant performance improvements, particularly in high-sparsity regimes where it surpasses current state-of-the-art methods.
5/27/2024