Simple and Scalable Strategies to Continually Pre-train Large Language Models

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) are frequently pre-trained on massive datasets containing billions of tokens.
- To keep these models up-to-date, the pre-training process must be repeated when new data becomes available.
- Fully re-training these models from scratch is computationally expensive and inefficient.
- This paper presents a simple and scalable approach to continually pre-train LLMs, matching the performance of full re-training while using a fraction of the compute.
Plain English Explanation
Large language models like GPT-3 are trained on huge datasets containing billions of words. As new data becomes available, these models need to be re-trained to stay current. However, fully re-training the models from scratch every time is extremely computationally intensive and inefficient.
This research paper proposes a more efficient solution. The key ideas are:
- Learning Rate Re-Warming: Gradually increasing the learning rate during training to help the model adapt to new data.
- Learning Rate Re-Decaying: Gradually decreasing the learning rate back down to stabilize the model.
- Replay of Previous Data: Periodically exposing the model to data it was trained on before, to prevent forgetting.
By combining these simple techniques, the researchers were able to continually pre-train large language models while matching the performance of full re-training, but using much less computational power.
Technical Explanation
The paper presents experiments on two different distribution shifts: a "weak but realistic" shift between English datasets, and a "stronger" shift from English to German. They tested this approach on both a 405 million parameter model and a 10 billion parameter model.
The key findings are:
- The proposed continual pre-training strategies, including learning rate re-warming and re-decaying along with replay of previous data, are able to match the performance of fully re-training the models from scratch.
- This was demonstrated for both the weaker English-to-English shift and the stronger English-to-German shift, across different model sizes.
- The continual pre-training approach required significantly less compute compared to full re-training.
The paper also proposes alternative learning rate schedules that may help further mitigate forgetting during continual pre-training.
Critical Analysis
The paper provides a compelling and practical solution to the challenge of efficiently updating large language models as new data becomes available. The authors demonstrate the effectiveness of their techniques across different distribution shifts and model sizes.
One limitation is that the experiments only considered language model pre-training, not fine-tuning on downstream tasks. Further research would be needed to see if the continual pre-training strategies generalize to that setting.
Additionally, while the proposed methods are simple and scalable, there may be more sophisticated continual learning techniques that could provide even better performance. The authors acknowledge this and suggest exploring alternative approaches as future work.
Overall, this research represents an important step forward in making large language model pre-training more computationally efficient and practical for real-world deployment.
Conclusion
This paper presents a simple and effective approach for continually pre-training large language models as new data becomes available. By combining learning rate re-warming, re-decaying, and replay of previous data, the researchers were able to match the performance of fully re-training the models from scratch, while using a fraction of the computational resources.
These findings have significant implications for the practical deployment of large language models, allowing them to be kept up-to-date in a scalable and efficient manner. Further research into continual learning techniques for language models could lead to even more powerful and adaptable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Simple and Scalable Strategies to Continually Pre-train Large Language Models
Adam Ibrahim, Benjamin Th'erien, Kshitij Gupta, Mats L. Richter, Quentin Anthony, Timoth'ee Lesort, Eugene Belilovsky, Irina Rish
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually pre-train these models, saving significant compute compared to re-training. However, the distribution shift induced by new data typically results in degraded performance on previous data or poor adaptation to the new data. In this work, we show that a simple and scalable combination of learning rate (LR) re-warming, LR re-decaying, and replay of previous data is sufficient to match the performance of fully re-training from scratch on all available data, as measured by the final loss and the average score on several language model (LM) evaluation benchmarks. Specifically, we show this for a weak but realistic distribution shift between two commonly used LLM pre-training datasets (English$rightarrow$English) and a stronger distribution shift (English$rightarrow$German) at the $405$M parameter model scale with large dataset sizes (hundreds of billions of tokens). Selecting the weak but realistic shift for larger-scale experiments, we also find that our continual learning strategies match the re-training baseline for a 10B parameter LLM. Our results demonstrate that LLMs can be successfully updated via simple and scalable continual learning strategies, matching the re-training baseline using only a fraction of the compute. Finally, inspired by previous work, we propose alternatives to the cosine learning rate schedule that help circumvent forgetting induced by LR re-warming and that are not bound to a fixed token budget.
Read more9/5/2024
0
Efficient Continual Pre-training by Mitigating the Stability Gap
Yiduo Guo, Jie Fu, Huishuai Zhang, Dongyan Zhao, Yikang Shen
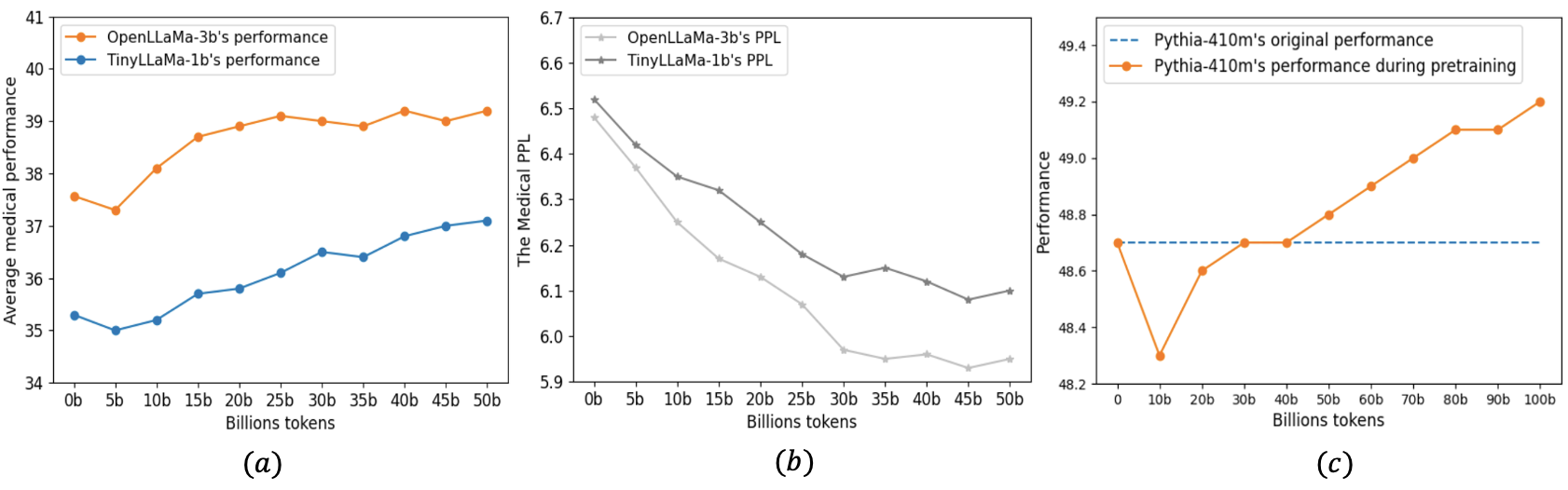
Continual pre-training has increasingly become the predominant approach for adapting Large Language Models (LLMs) to new domains. This process involves updating the pre-trained LLM with a corpus from a new domain, resulting in a shift in the training distribution. To study the behavior of LLMs during this shift, we measured the model's performance throughout the continual pre-training process. we observed a temporary performance drop at the beginning, followed by a recovery phase, a phenomenon known as the stability gap, previously noted in vision models classifying new classes. To address this issue and enhance LLM performance within a fixed compute budget, we propose three effective strategies: (1) Continually pre-training the LLM on a subset with a proper size for multiple epochs, resulting in faster performance recovery than pre-training the LLM on a large corpus in a single epoch; (2) Pre-training the LLM only on high-quality sub-corpus, which rapidly boosts domain performance; and (3) Using a data mixture similar to the pre-training data to reduce distribution gap. We conduct various experiments on Llama-family models to validate the effectiveness of our strategies in both medical continual pre-training and instruction tuning. For example, our strategies improve the average medical task performance of the OpenLlama-3B model from 36.2% to 40.7% with only 40% of the original training budget and enhance the average general task performance without causing forgetting. Furthermore, we apply our strategies to the Llama-3-8B model. The resulting model, Llama-3-Physician, achieves the best medical performance among current open-source models, and performs comparably to or even better than GPT-4 on several medical benchmarks. We release our models at url{https://huggingface.co/YiDuo1999/Llama-3-Physician-8B-Instruct}.
Read more6/28/2024

0
Reuse, Don't Retrain: A Recipe for Continued Pretraining of Language Models
Jupinder Parmar, Sanjev Satheesh, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro
As language models have scaled both their number of parameters and pretraining dataset sizes, the computational cost for pretraining has become intractable except for the most well-resourced teams. This increasing cost makes it ever more important to be able to reuse a model after it has completed pretraining; allowing for a model's abilities to further improve without needing to train from scratch. In this work, we detail a set of guidelines that cover how to design efficacious data distributions and learning rate schedules for continued pretraining of language models. When applying these findings within a continued pretraining run on top of a well-trained 15B parameter model, we show an improvement of 9% in average model accuracy compared to the baseline of continued training on the pretraining set. The resulting recipe provides a practical starting point with which to begin developing language models through reuse rather than retraining.
Read more7/11/2024
💬
0
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, Hao Wang
The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as catastrophic forgetting. While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.
Read more7/2/2024