Simulating, Fast and Slow: Learning Policies for Black-Box Optimization
2406.04261
0
0

Abstract
In recent years, solving optimization problems involving black-box simulators has become a point of focus for the machine learning community due to their ubiquity in science and engineering. The simulators describe a forward process $f_{mathrm{sim}}: (psi, x) rightarrow y$ from simulation parameters $psi$ and input data $x$ to observations $y$, and the goal of the optimization problem is to find parameters $psi$ that minimize a desired loss function. Sophisticated optimization algorithms typically require gradient information regarding the forward process, $f_{mathrm{sim}}$, with respect to the parameters $psi$. However, obtaining gradients from black-box simulators can often be prohibitively expensive or, in some cases, impossible. Furthermore, in many applications, practitioners aim to solve a set of related problems. Thus, starting the optimization ``ab initio, i.e. from scratch, each time might be inefficient if the forward model is expensive to evaluate. To address those challenges, this paper introduces a novel method for solving classes of similar black-box optimization problems by learning an active learning policy that guides a differentiable surrogate's training and uses the surrogate's gradients to optimize the simulation parameters with gradient descent. After training the policy, downstream optimization of problems involving black-box simulators requires up to $sim$90% fewer expensive simulator calls compared to baselines such as local surrogate-based approaches, numerical optimization, and Bayesian methods.
Create account to get full access
Overview
- This paper explores the use of simulation-based learning to optimize black-box systems, where the underlying function is unknown or difficult to model.
- The authors propose a novel approach that combines fast and slow learning policies to efficiently explore the optimization landscape and find high-performing solutions.
- The approach is evaluated on a range of black-box optimization tasks, including function-based sim-to-real learning and multi-objective optimization.
Plain English Explanation
In this paper, the researchers are looking at ways to optimize the performance of complex, "black-box" systems. These are systems where the underlying mathematical functions that govern how the system works are either unknown or very difficult to model accurately.
The researchers propose a new approach that uses a combination of "fast" and "slow" learning policies to explore the optimization landscape and find high-performing solutions. The "fast" policy quickly tries out different options to get a sense of the general shape of the optimization problem, while the "slow" policy takes a more thorough and careful look to refine the solution.
This approach is tested on a range of different optimization problems, including ones related to transferring simulations to the real world and optimizing systems with multiple, competing objectives. The key idea is to leverage the strengths of both fast and slow learning to efficiently explore the optimization space and find the best solutions.
Technical Explanation
The paper introduces a novel approach for optimizing the performance of black-box systems, where the underlying mathematical functions are unknown or difficult to model. The authors propose a method that combines "fast" and "slow" learning policies to efficiently explore the optimization landscape.
The fast policy rapidly tries out different options to get a broad sense of the problem structure, while the slow policy takes a more thorough and careful approach to refine the solution. This combination allows the system to quickly identify promising regions of the optimization space, and then focus its efforts on finding high-performing solutions within those regions.
The approach is evaluated on a range of black-box optimization tasks, including efficient learning of accurate surrogates for simulations of complex systems, offline model-based optimization via policy guidance, and learning quadrupedal locomotion via differentiable simulation. The results demonstrate the effectiveness of the fast and slow learning approach in navigating the complex optimization landscapes of these black-box problems.
Critical Analysis
The paper presents a promising approach for optimizing the performance of black-box systems, but there are a few potential limitations and areas for further research:
-
The authors note that the effectiveness of the fast and slow learning policies may depend on the specific problem and the available computational resources. More work is needed to understand how to best configure these policies for different types of black-box optimization tasks.
-
The paper focuses on single-objective optimization, but many real-world problems involve multiple, potentially conflicting objectives. While the authors briefly mention extensions to multi-objective optimization, further research is needed to fully understand how the fast and slow learning approach can be applied in these more complex scenarios.
-
The paper does not provide a detailed analysis of the computational overhead and runtime requirements of the proposed method. As black-box optimization can be computationally intensive, it would be helpful to understand the tradeoffs between the efficiency gains of the fast and slow learning approach and the additional computational burden it may impose.
Despite these caveats, the overall approach presented in the paper represents an interesting and promising direction for advancing the state of the art in black-box optimization. By combining fast and slow learning policies, the method seeks to balance exploration and exploitation in a way that can effectively navigate complex optimization landscapes.
Conclusion
This paper introduces a novel approach for optimizing the performance of black-box systems, where the underlying mathematical functions are unknown or difficult to model. The key idea is to combine "fast" and "slow" learning policies to efficiently explore the optimization landscape and find high-performing solutions.
The proposed method is evaluated on a range of black-box optimization tasks, including sim-to-real learning and multi-objective optimization, demonstrating its effectiveness in navigating complex optimization problems.
While the paper highlights a few potential limitations and areas for further research, the overall approach represents an important step forward in addressing the challenges of black-box optimization. By leveraging the strengths of both fast and slow learning, the method offers a promising path towards more efficient and effective optimization of complex, real-world systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
Efficient Learning of Accurate Surrogates for Simulations of Complex Systems
A. Diaw, M. McKerns, I. Sagert, L. G. Stanton, M. S. Murillo
0
0
Machine learning methods are increasingly used to build computationally inexpensive surrogates for complex physical models. The predictive capability of these surrogates suffers when data are noisy, sparse, or time-dependent. As we are interested in finding a surrogate that provides valid predictions of any potential future model evaluations, we introduce an online learning method empowered by optimizer-driven sampling. The method has two advantages over current approaches. First, it ensures that all turning points on the model response surface are included in the training data. Second, after any new model evaluations, surrogates are tested and retrained (updated) if the score drops below a validity threshold. Tests on benchmark functions reveal that optimizer-directed sampling generally outperforms traditional sampling methods in terms of accuracy around local extrema, even when the scoring metric favors overall accuracy. We apply our method to simulations of nuclear matter to demonstrate that highly accurate surrogates for the nuclear equation of state can be reliably auto-generated from expensive calculations using a few model evaluations.
5/20/2024
🛠️
Pseudo-Bayesian Optimization
Haoxian Chen, Henry Lam
0
0
Bayesian Optimization is a popular approach for optimizing expensive black-box functions. Its key idea is to use a surrogate model to approximate the objective and, importantly, quantify the associated uncertainty that allows a sequential search of query points that balance exploitation-exploration. Gaussian process (GP) has been a primary candidate for the surrogate model, thanks to its Bayesian-principled uncertainty quantification power and modeling flexibility. However, its challenges have also spurred an array of alternatives whose convergence properties could be more opaque. Motivated by these, we study in this paper an axiomatic framework that elicits the minimal requirements to guarantee black-box optimization convergence that could apply beyond GP-based methods. Moreover, we leverage the design freedom in our framework, which we call Pseudo-Bayesian Optimization, to construct empirically superior algorithms. In particular, we show how using simple local regression, and a suitable randomized prior construction to quantify uncertainty, not only guarantees convergence but also consistently outperforms state-of-the-art benchmarks in examples ranging from high-dimensional synthetic experiments to realistic hyperparameter tuning and robotic applications.
6/21/2024

Learning Quadrupedal Locomotion via Differentiable Simulation
Clemens Schwarke, Victor Klemm, Jesus Tordesillas, Jean-Pierre Sleiman, Marco Hutter
0
0
The emergence of differentiable simulators enabling analytic gradient computation has motivated a new wave of learning algorithms that hold the potential to significantly increase sample efficiency over traditional Reinforcement Learning (RL) methods. While recent research has demonstrated performance gains in scenarios with comparatively smooth dynamics and, thus, smooth optimization landscapes, research on leveraging differentiable simulators for contact-rich scenarios, such as legged locomotion, is scarce. This may be attributed to the discontinuous nature of contact, which introduces several challenges to optimizing with analytic gradients. The purpose of this paper is to determine if analytic gradients can be beneficial even in the face of contact. Our investigation focuses on the effects of different soft and hard contact models on the learning process, examining optimization challenges through the lens of contact simulation. We demonstrate the viability of employing analytic gradients to learn physically plausible locomotion skills with a quadrupedal robot using Short-Horizon Actor-Critic (SHAC), a learning algorithm leveraging analytic gradients, and draw a comparison to a state-of-the-art RL algorithm, Proximal Policy Optimization (PPO), to understand the benefits of analytic gradients.
4/4/2024
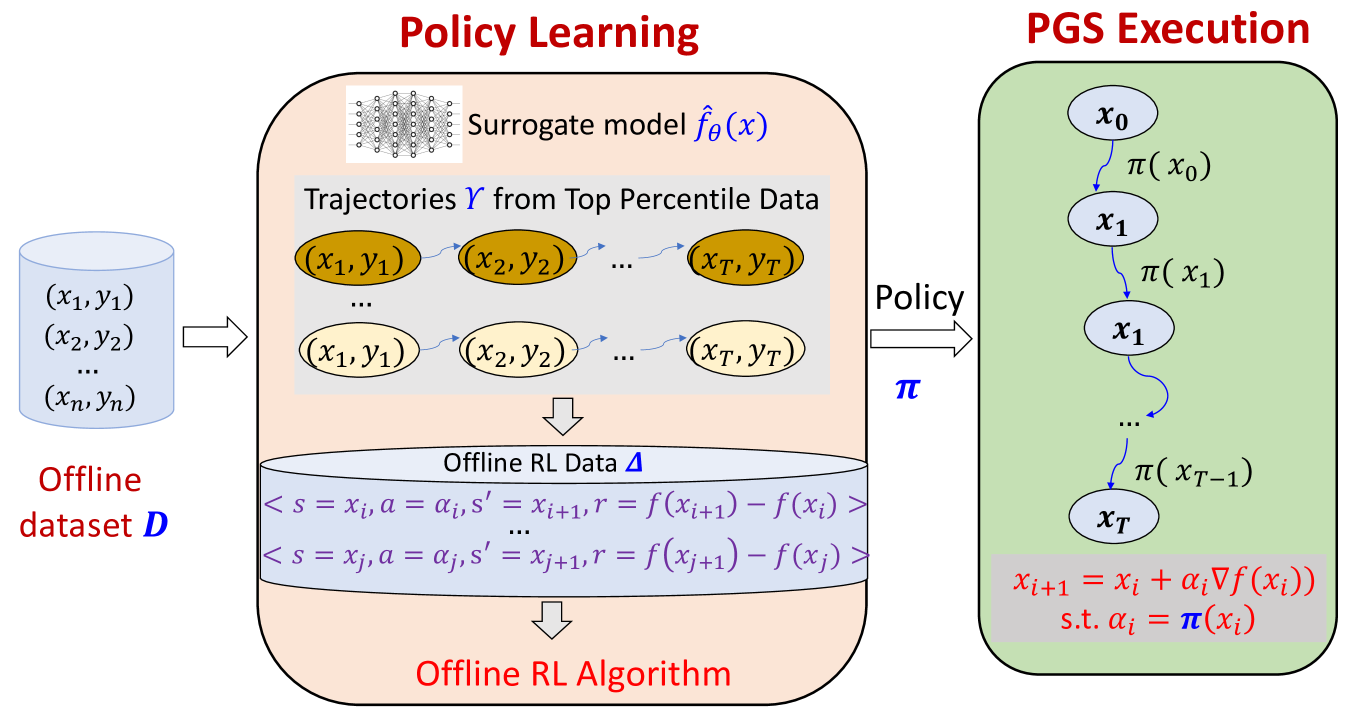
Offline Model-Based Optimization via Policy-Guided Gradient Search
Yassine Chemingui, Aryan Deshwal, Trong Nghia Hoang, Janardhan Rao Doppa
0
0
Offline optimization is an emerging problem in many experimental engineering domains including protein, drug or aircraft design, where online experimentation to collect evaluation data is too expensive or dangerous. To avoid that, one has to optimize an unknown function given only its offline evaluation at a fixed set of inputs. A naive solution to this problem is to learn a surrogate model of the unknown function and optimize this surrogate instead. However, such a naive optimizer is prone to erroneous overestimation of the surrogate (possibly due to over-fitting on a biased sample of function evaluation) on inputs outside the offline dataset. Prior approaches addressing this challenge have primarily focused on learning robust surrogate models. However, their search strategies are derived from the surrogate model rather than the actual offline data. To fill this important gap, we introduce a new learning-to-search perspective for offline optimization by reformulating it as an offline reinforcement learning problem. Our proposed policy-guided gradient search approach explicitly learns the best policy for a given surrogate model created from the offline data. Our empirical results on multiple benchmarks demonstrate that the learned optimization policy can be combined with existing offline surrogates to significantly improve the optimization performance.
5/10/2024