Simultaneous Training of First- and Second-Order Optimizers in Population-Based Reinforcement Learning

0
Sign in to get full access
Overview
- This paper explores a new approach to training reinforcement learning agents using a combination of first-order and second-order optimization methods.
- The key idea is to train the agent and the optimizer simultaneously, allowing the optimizer to adapt to the specific characteristics of the agent and problem.
- The authors demonstrate the effectiveness of their method on several benchmark reinforcement learning tasks.
Plain English Explanation
In reinforcement learning, the goal is to train an agent to make optimal decisions in an environment in order to maximize some reward. Traditionally, this has been done using first-order optimization methods like gradient descent, which update the agent's parameters based on the gradient of the reward function.
However, the authors argue that this approach has limitations, as the gradient-based updates may not be well-suited to the specific characteristics of the agent and problem. To address this, they propose a simultaneous training approach where the agent and the optimizer are trained together.
The key idea is to use a combination of first-order and second-order optimization methods. First-order methods like gradient descent are used to update the agent's parameters, while second-order methods like natural gradient descent are used to update the optimizer's hyperparameters. This allows the optimizer to adapt to the specific characteristics of the agent and problem, leading to faster and more effective training.
The authors demonstrate the effectiveness of their approach on several benchmark reinforcement learning tasks, such as LunarLander-v2 and HalfCheetah-v2. Their results show that the simultaneous training approach outperforms traditional gradient-based methods, suggesting that it could be a promising direction for future research in reinforcement learning.
Technical Explanation
The paper introduces a new approach to training reinforcement learning agents using a combination of first-order and second-order optimization methods. The key idea is to train the agent and the optimizer simultaneously, allowing the optimizer to adapt to the specific characteristics of the agent and problem.
The authors start by defining the reinforcement learning problem and introducing the concept of population-based training, where multiple agents are trained in parallel and the best-performing agents are used to update the population.
They then describe their simultaneous training approach, where the agent's parameters are updated using first-order optimization methods like gradient descent, while the optimizer's hyperparameters are updated using second-order methods like natural gradient descent. This allows the optimizer to adapt to the specific characteristics of the agent and problem.
To evaluate their approach, the authors conduct experiments on several benchmark reinforcement learning tasks, including LunarLander-v2 and HalfCheetah-v2. Their results show that the simultaneous training approach outperforms traditional gradient-based methods, suggesting that it could be a promising direction for future research in reinforcement learning.
Critical Analysis
The paper presents a novel approach to training reinforcement learning agents, and the authors' results suggest that it could be a promising direction for future research. However, there are a few potential limitations and areas for further exploration:
-
Scalability: The simultaneous training approach may become computationally expensive as the complexity of the agent and problem increases. It would be interesting to see how the method scales to more challenging tasks and larger-scale problems.
-
Interpretability: The paper does not provide much insight into the inner workings of the simultaneous training process, making it difficult to understand why the method is effective. Further analysis of the optimizer's behavior and its impact on the agent's performance could help improve the interpretability of the approach.
-
Generalization: The paper focuses on a few benchmark tasks, and it's unclear how well the simultaneous training approach would generalize to a wider range of reinforcement learning problems. Evaluating the method on a more diverse set of tasks would be an important next step.
-
Practical Considerations: While the paper demonstrates the effectiveness of the simultaneous training approach, it doesn't address some of the practical challenges involved in deploying such a system, such as hyperparameter tuning, hardware requirements, and real-world deployment.
Overall, the paper presents an interesting and promising approach to training reinforcement learning agents, but there are still some open questions and areas for further research.
Conclusion
This paper introduces a novel approach to training reinforcement learning agents using a combination of first-order and second-order optimization methods. The key idea is to train the agent and the optimizer simultaneously, allowing the optimizer to adapt to the specific characteristics of the agent and problem.
The authors' results demonstrate the effectiveness of this approach on several benchmark reinforcement learning tasks, suggesting that it could be a promising direction for future research in the field. While there are some potential limitations and areas for further exploration, the simultaneous training approach represents an interesting and innovative way to address some of the challenges in reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Simultaneous Training of First- and Second-Order Optimizers in Population-Based Reinforcement Learning
Felix Pfeiffer, Shahram Eivazi
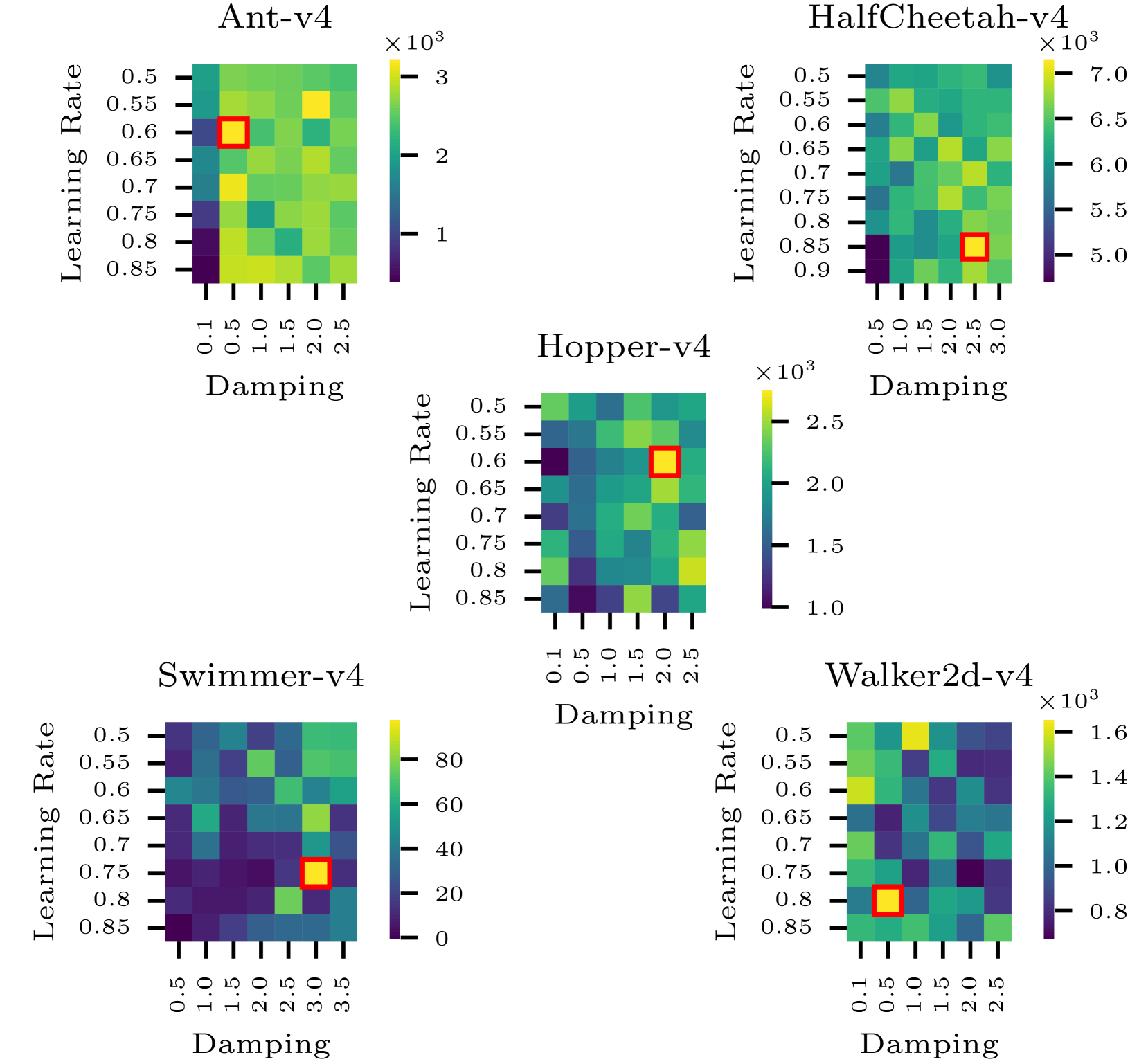
The tuning of hyperparameters in reinforcement learning (RL) is critical, as these parameters significantly impact an agent's performance and learning efficiency. Dynamic adjustment of hyperparameters during the training process can significantly enhance both the performance and stability of learning. Population-based training (PBT) provides a method to achieve this by continuously tuning hyperparameters throughout the training. This ongoing adjustment enables models to adapt to different learning stages, resulting in faster convergence and overall improved performance. In this paper, we propose an enhancement to PBT by simultaneously utilizing both first- and second-order optimizers within a single population. We conducted a series of experiments using the TD3 algorithm across various MuJoCo environments. Our results, for the first time, empirically demonstrate the potential of incorporating second-order optimizers within PBT-based RL. Specifically, the combination of the K-FAC optimizer with Adam led to up to a 10% improvement in overall performance compared to PBT using only Adam. Additionally, in environments where Adam occasionally fails, such as the Swimmer environment, the mixed population with K-FAC exhibited more reliable learning outcomes, offering a significant advantage in training stability without a substantial increase in computational time.
Read more9/5/2024

0
Generalized Population-Based Training for Hyperparameter Optimization in Reinforcement Learning
Hui Bai, Ran Cheng
Hyperparameter optimization plays a key role in the machine learning domain. Its significance is especially pronounced in reinforcement learning (RL), where agents continuously interact with and adapt to their environments, requiring dynamic adjustments in their learning trajectories. To cater to this dynamicity, the Population-Based Training (PBT) was introduced, leveraging the collective intelligence of a population of agents learning simultaneously. However, PBT tends to favor high-performing agents, potentially neglecting the explorative potential of agents on the brink of significant advancements. To mitigate the limitations of PBT, we present the Generalized Population-Based Training (GPBT), a refined framework designed for enhanced granularity and flexibility in hyperparameter adaptation. Complementing GPBT, we further introduce Pairwise Learning (PL). Instead of merely focusing on elite agents, PL employs a comprehensive pairwise strategy to identify performance differentials and provide holistic guidance to underperforming agents. By integrating the capabilities of GPBT and PL, our approach significantly improves upon traditional PBT in terms of adaptability and computational efficiency. Rigorous empirical evaluations across a range of RL benchmarks confirm that our approach consistently outperforms not only the conventional PBT but also its Bayesian-optimized variant.
Read more4/24/2024

0
Scaling Population-Based Reinforcement Learning with GPU Accelerated Simulation
Asad Ali Shahid, Yashraj Narang, Vincenzo Petrone, Enrico Ferrentino, Ankur Handa, Dieter Fox, Marco Pavone, Loris Roveda
In recent years, deep reinforcement learning (RL) has shown its effectiveness in solving complex continuous control tasks like locomotion and dexterous manipulation. However, this comes at the cost of an enormous amount of experience required for training, exacerbated by the sensitivity of learning efficiency and the policy performance to hyperparameter selection, which often requires numerous trials of time-consuming experiments. This work introduces a Population-Based Reinforcement Learning (PBRL) approach that exploits a GPU-accelerated physics simulator to enhance the exploration capabilities of RL by concurrently training multiple policies in parallel. The PBRL framework is applied to three state-of-the-art RL algorithms - PPO, SAC, and DDPG - dynamically adjusting hyperparameters based on the performance of learning agents. The experiments are performed on four challenging tasks in Isaac Gym - Anymal Terrain, Shadow Hand, Humanoid, Franka Nut Pick - by analyzing the effect of population size and mutation mechanisms for hyperparameters. The results demonstrate that PBRL agents outperform non-evolutionary baseline agents across tasks essential for humanoid robots, such as bipedal locomotion, manipulation, and grasping in unstructured environments. The trained agents are finally deployed in the real world for the Franka Nut Pick manipulation task. To our knowledge, this is the first sim-to-real attempt for successfully deploying PBRL agents on real hardware. Code and videos of the learned policies are available on our project website (https://sites.google.com/view/pbrl).
Read more6/26/2024
🏅
0
Offline Reinforcement Learning with Behavioral Supervisor Tuning
Padmanaba Srinivasan, William Knottenbelt
Offline reinforcement learning (RL) algorithms are applied to learn performant, well-generalizing policies when provided with a static dataset of interactions. Many recent approaches to offline RL have seen substantial success, but with one key caveat: they demand substantial per-dataset hyperparameter tuning to achieve reported performance, which requires policy rollouts in the environment to evaluate; this can rapidly become cumbersome. Furthermore, substantial tuning requirements can hamper the adoption of these algorithms in practical domains. In this paper, we present TD3 with Behavioral Supervisor Tuning (TD3-BST), an algorithm that trains an uncertainty model and uses it to guide the policy to select actions within the dataset support. TD3-BST can learn more effective policies from offline datasets compared to previous methods and achieves the best performance across challenging benchmarks without requiring per-dataset tuning.
Read more7/30/2024