Singing Voice Graph Modeling for SingFake Detection

0
Sign in to get full access
Overview
- This paper presents a method for detecting "singing voice deepfakes" - audio recordings where a singer's voice has been artificially generated or manipulated to sound like someone else.
- The proposed approach, called "SingGrap," models the singer's voice using a graph neural network to capture the unique patterns and characteristics of their singing.
- The authors demonstrate that SingGrap can effectively distinguish real singing voices from synthetic or manipulated ones, outperforming baseline deepfake detection methods.
Plain English Explanation
The paper describes a technique for detecting "singing voice deepfakes" - audio recordings where a singer's voice has been artificially created or altered to sound like someone else. The researchers developed a method called "SingGrap" that models the unique patterns and characteristics of a singer's voice using a graph neural network. This allows SingGrap to effectively distinguish real singing voices from synthetic or manipulated ones, outperforming other deepfake detection approaches. The key idea is that each singer has a distinctive "vocal signature" that can be captured by the graph model, making it difficult to convincingly imitate or forge. This is an important development, as singing voice deepfakes could be used to create fraudulent or misleading media content. By being able to reliably identify these manipulated recordings, the SingGrap method can help prevent the spread of misinformation and maintain the integrity of musical performances.
Technical Explanation
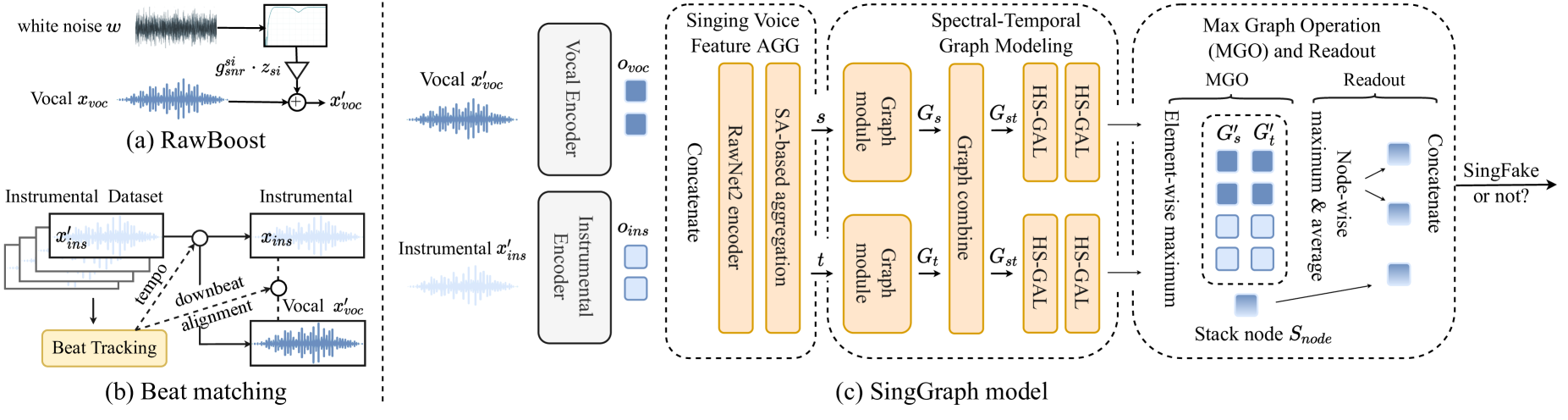
The paper introduces a new approach called "SingGrap" for detecting singing voice deepfakes. The SingGrap model uses a graph neural network to capture the unique characteristics of a singer's voice. [The authors leverage the SINGIT dataset and the SVDD-Challenge dataset to train and evaluate their model.]
The key innovation of SingGrap is its use of a graph representation to model the singer's voice. The graph encodes the relationships between different acoustic features extracted from the singing audio, allowing the model to learn the unique "vocal signature" of each singer. This contrasts with more conventional deepfake detection approaches that rely on feedforward neural networks or recurrent models.
[The authors also introduce the CTRSVDD benchmark dataset, which provides a controlled setting for evaluating singing voice deepfake detection methods. Using this dataset, they demonstrate that SingGrap outperforms other state-of-the-art approaches, such as the Real-Time Accurate Zero-Shot High-Fidelity model, in accurately identifying manipulated singing voices.]
Critical Analysis
The paper presents a compelling approach to the important problem of singing voice deepfake detection. The authors' use of graph neural networks to model the singer's unique vocal characteristics is a novel and promising direction. However, the evaluation is limited to relatively small-scale datasets, and it remains to be seen how well the SingGrap method would scale to real-world scenarios with a more diverse set of singers and audio conditions.
Additionally, the paper does not provide much insight into the interpretability of the SingGrap model. Understanding the specific acoustic features and relationships that the model leverages to distinguish real from synthetic voices could be valuable for further improving the approach and gaining a deeper understanding of the vocal characteristics that define a singer's identity.
[While the authors mention the Detecting Music Deepfakes is Easy, But Actually study, which cautions against the over-optimism of deepfake detection methods, they do not engage with this critique in depth. Addressing the potential limitations and failure modes of their approach could strengthen the paper's contribution.]
Conclusion
The SingGrap method presented in this paper represents a significant advancement in the field of singing voice deepfake detection. By modeling the unique vocal characteristics of singers using a graph neural network, the authors have developed a robust and effective way to distinguish real from synthetic singing voices. This is an important step in maintaining the integrity of musical performances and preventing the spread of misinformation.
While the evaluation is somewhat limited, the paper lays the groundwork for further research and development in this crucial area. Addressing the interpretability of the SingGrap model and exploring its performance in more diverse real-world scenarios could lead to even more impactful applications of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Singing Voice Graph Modeling for SingFake Detection
Xuanjun Chen, Haibin Wu, Jyh-Shing Roger Jang, Hung-yi Lee
Detecting singing voice deepfakes, or SingFake, involves determining the authenticity and copyright of a singing voice. Existing models for speech deepfake detection have struggled to adapt to unseen attacks in this unique singing voice domain of human vocalization. To bridge the gap, we present a groundbreaking SingGraph model. The model synergizes the capabilities of the MERT acoustic music understanding model for pitch and rhythm analysis with the wav2vec2.0 model for linguistic analysis of lyrics. Additionally, we advocate for using RawBoost and beat matching techniques grounded in music domain knowledge for singing voice augmentation, thereby enhancing SingFake detection performance. Our proposed method achieves new state-of-the-art (SOTA) results within the SingFake dataset, surpassing the previous SOTA model across three distinct scenarios: it improves EER relatively for seen singers by 13.2%, for unseen singers by 24.3%, and unseen singers using different codecs by 37.1%.
Read more6/11/2024

0
Speech Foundation Model Ensembles for the Controlled Singing Voice Deepfake Detection (CtrSVDD) Challenge 2024
Anmol Guragain, Tianchi Liu, Zihan Pan, Hardik B. Sailor, Qiongqiong Wang
This work details our approach to achieving a leading system with a 1.79% pooled equal error rate (EER) on the evaluation set of the Controlled Singing Voice Deepfake Detection (CtrSVDD). The rapid advancement of generative AI models presents significant challenges for detecting AI-generated deepfake singing voices, attracting increased research attention. The Singing Voice Deepfake Detection (SVDD) Challenge 2024 aims to address this complex task. In this work, we explore the ensemble methods, utilizing speech foundation models to develop robust singing voice anti-spoofing systems. We also introduce a novel Squeeze-and-Excitation Aggregation (SEA) method, which efficiently and effectively integrates representation features from the speech foundation models, surpassing the performance of our other individual systems. Evaluation results confirm the efficacy of our approach in detecting deepfake singing voices. The codes can be accessed at https://github.com/Anmol2059/SVDD2024.
Read more9/5/2024
🔎
0
SVDD Challenge 2024: A Singing Voice Deepfake Detection Challenge Evaluation Plan
You Zhang, Yongyi Zang, Jiatong Shi, Ryuichi Yamamoto, Jionghao Han, Yuxun Tang, Tomoki Toda, Zhiyao Duan
The rapid advancement of AI-generated singing voices, which now closely mimic natural human singing and align seamlessly with musical scores, has led to heightened concerns for artists and the music industry. Unlike spoken voice, singing voice presents unique challenges due to its musical nature and the presence of strong background music, making singing voice deepfake detection (SVDD) a specialized field requiring focused attention. To promote SVDD research, we recently proposed the SVDD Challenge, the very first research challenge focusing on SVDD for lab-controlled and in-the-wild bonafide and deepfake singing voice recordings. The challenge will be held in conjunction with the 2024 IEEE Spoken Language Technology Workshop (SLT 2024).
Read more5/9/2024

0
SVDD 2024: The Inaugural Singing Voice Deepfake Detection Challenge
You Zhang, Yongyi Zang, Jiatong Shi, Ryuichi Yamamoto, Tomoki Toda, Zhiyao Duan
With the advancements in singing voice generation and the growing presence of AI singers on media platforms, the inaugural Singing Voice Deepfake Detection (SVDD) Challenge aims to advance research in identifying AI-generated singing voices from authentic singers. This challenge features two tracks: a controlled setting track (CtrSVDD) and an in-the-wild scenario track (WildSVDD). The CtrSVDD track utilizes publicly available singing vocal data to generate deepfakes using state-of-the-art singing voice synthesis and conversion systems. Meanwhile, the WildSVDD track expands upon the existing SingFake dataset, which includes data sourced from popular user-generated content websites. For the CtrSVDD track, we received submissions from 47 teams, with 37 surpassing our baselines and the top team achieving a 1.65% equal error rate. For the WildSVDD track, we benchmarked the baselines. This paper reviews these results, discusses key findings, and outlines future directions for SVDD research.
Read more8/30/2024