Single Image Unlearning: Efficient Machine Unlearning in Multimodal Large Language Models
2405.12523
0
0
🖼️
Abstract
Machine unlearning empowers individuals with the `right to be forgotten' by removing their private or sensitive information encoded in machine learning models. However, it remains uncertain whether MU can be effectively applied to Multimodal Large Language Models (MLLMs), particularly in scenarios of forgetting the leaked visual data of concepts. To overcome the challenge, we propose an efficient method, Single Image Unlearning (SIU), to unlearn the visual recognition of a concept by fine-tuning a single associated image for few steps. SIU consists of two key aspects: (i) Constructing Multifaceted fine-tuning data. We introduce four targets, based on which we construct fine-tuning data for the concepts to be forgotten; (ii) Jointly training loss. To synchronously forget the visual recognition of concepts and preserve the utility of MLLMs, we fine-tune MLLMs through a novel Dual Masked KL-divergence Loss combined with Cross Entropy loss. Alongside our method, we establish MMUBench, a new benchmark for MU in MLLMs and introduce a collection of metrics for its evaluation. Experimental results on MMUBench show that SIU completely surpasses the performance of existing methods. Furthermore, we surprisingly find that SIU can avoid invasive membership inference attacks and jailbreak attacks. To the best of our knowledge, we are the first to explore MU in MLLMs. We will release the code and benchmark in the near future.
Create account to get full access
Overview
- This paper explores the challenge of "machine unlearning" (MU) in the context of Multimodal Large Language Models (MLLMs).
- MU aims to give individuals the "right to be forgotten" by removing their private or sensitive information from machine learning models.
- The paper proposes a method called "Single Image Unlearning" (SIU) to effectively unlearn the visual recognition of concepts in MLLMs.
Plain English Explanation
The paper discusses a way to give people more control over their personal information that has been used to train machine learning models. This is known as "machine unlearning" (MU). The researchers were particularly interested in whether MU could be applied to large language models that can understand and generate text, images, and other types of data (called Multimodal Large Language Models or MLLMs).
The key idea of the paper is a method called "Single Image Unlearning" (SIU). This allows you to remove the recognition of a particular visual concept (like a specific person's face) from an MLLM by fine-tuning the model on just a single image related to that concept. The researchers found that this approach can completely forget the visual recognition of concepts while also preserving the overall usefulness of the MLLM.
Technical Explanation
The paper proposes the "Single Image Unlearning" (SIU) method to overcome the challenge of forgetting the leaked visual data of concepts in MLLMs. SIU consists of two key aspects:
-
Constructing Multifaceted Fine-Tuning Data: The researchers introduce four targets (e.g., incorrect classification, low confidence, altered visual features) to construct fine-tuning data for the concepts to be forgotten.
-
Jointly Training Loss: To synchronously forget the visual recognition of concepts and preserve the utility of MLLMs, the researchers fine-tune the models using a novel Dual Masked KL-divergence Loss combined with Cross Entropy loss.
The paper also establishes a new benchmark called "MMUBench" for evaluating MU in MLLMs and introduces a set of metrics for this purpose. Experimental results on MMUBench show that SIU significantly outperforms existing MU methods.
Interestingly, the researchers also found that SIU can avoid invasive membership inference attacks and "jailbreak" attacks, where an adversary tries to extract private information from the model.
Critical Analysis
The paper addresses an important challenge in the field of machine learning – giving individuals more control over their personal data encoded in machine learning models. The proposed SIU method seems to be a promising approach for achieving this in the context of MLLMs.
However, the paper does not discuss the potential limitations or drawbacks of the SIU method. For example, it's unclear how the method would scale to forgetting multiple concepts or if there are any negative impacts on the model's overall performance and capabilities.
Additionally, the paper does not explore the real-world implications and practical considerations of implementing MU in deployed ML systems. Further research is needed to understand the broader societal impacts and potential unintended consequences of this technology.
Conclusion
This paper is a significant contribution to the emerging field of machine unlearning, particularly in the context of Multimodal Large Language Models. The proposed SIU method offers a promising approach to giving individuals more control over their personal data encoded in these powerful AI systems.
While the technical results are impressive, future research should explore the practical challenges and potential limitations of implementing MU in real-world scenarios. Nonetheless, this work represents an important step towards empowering individuals with the "right to be forgotten" in the age of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Avoiding Copyright Infringement via Machine Unlearning
Guangyao Dou, Zheyuan Liu, Qing Lyu, Kaize Ding, Eric Wong
0
0
Pre-trained Large Language Models (LLMs) have demonstrated remarkable capabilities but also pose risks by learning and generating copyrighted material, leading to significant legal and ethical concerns. To address these issues, it is critical for model owners to be able to unlearn copyrighted content at various time steps. We explore the setting of sequential unlearning, where copyrighted content is removed over multiple time steps - a scenario that has not been rigorously addressed. To tackle this challenge, we propose Stable Sequential Unlearning (SSU), a novel unlearning framework for LLMs, designed to have a more stable process to remove copyrighted content from LLMs throughout different time steps using task vectors, by incorporating additional random labeling loss and applying gradient-based weight saliency mapping. Experiments demonstrate that SSU finds a good balance between unlearning efficacy and maintaining the model's general knowledge compared to existing baselines.
6/18/2024

Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Xiaojun Xu, Yuguang Yao, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
0
0
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
4/8/2024
🔎
An Information Theoretic Metric for Evaluating Unlearning Models
Dongjae Jeon, Wonje Jeung, Taeheon Kim, Albert No, Jonghyun Choi
0
0
Machine unlearning (MU) addresses privacy concerns by removing information of `forgetting data' samples from trained models. Typically, evaluating MU methods involves comparing unlearned models to those retrained from scratch without forgetting data, using metrics such as membership inference attacks (MIA) and accuracy measurements. These evaluations implicitly assume that if the output logits of the unlearned and retrained models are similar, the unlearned model has successfully forgotten the data. Here, we challenge if this assumption is valid. In particular, we conduct a simple experiment of training only the last layer of a given original model using a novel masked-distillation technique while keeping the rest fixed. Surprisingly, simply altering the last layer yields favorable outcomes in the existing evaluation metrics, while the model does not successfully unlearn the samples or classes. For better evaluating the MU methods, we propose a metric that quantifies the residual information about forgetting data samples in intermediate features using mutual information, called information difference index or IDI for short. The IDI provides a comprehensive evaluation of MU methods by efficiently analyzing the internal structure of DNNs. Our metric is scalable to large datasets and adaptable to various model architectures. Additionally, we present COLapse-and-Align (COLA), a simple contrastive-based method that effectively unlearns intermediate features.
5/29/2024
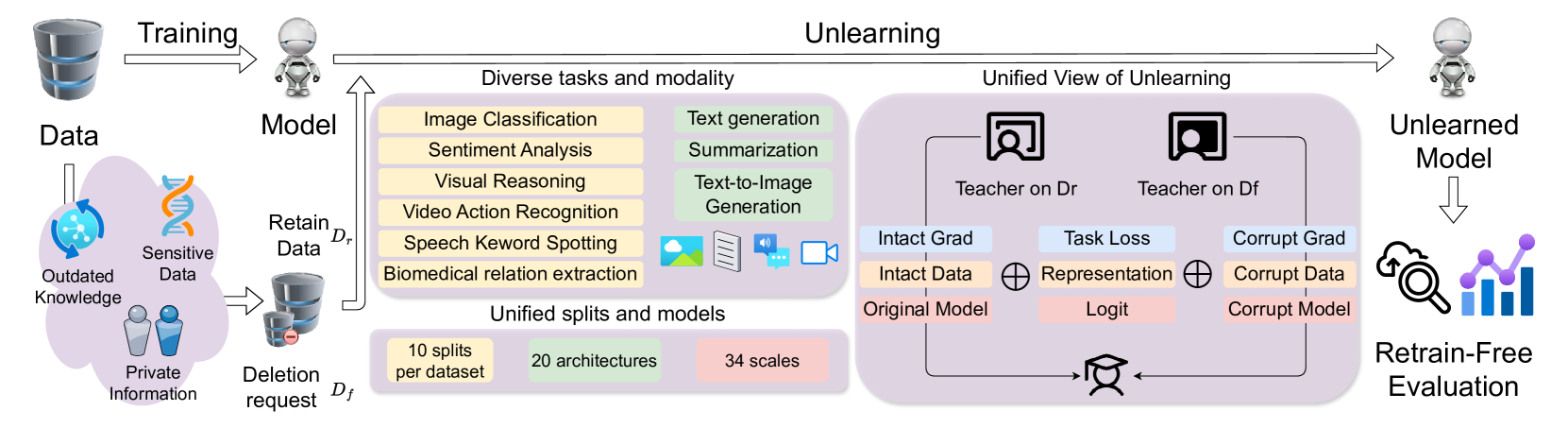
MU-Bench: A Multitask Multimodal Benchmark for Machine Unlearning
Jiali Cheng, Hadi Amiri
0
0
Recent advancements in Machine Unlearning (MU) have introduced solutions to selectively remove certain training samples, such as those with outdated or sensitive information, from trained models. Despite these advancements, evaluation of MU methods have been inconsistent, employing different trained models and architectures, and sample removal strategies, which hampers accurate comparison. In addition, prior MU approaches have mainly focused on singular tasks or modalities, which is not comprehensive. To address these limitations, we develop MU-Bench, the first comprehensive benchmark for MU that (i) unifies the sets of deleted samples and trained models, and (ii) provides broad coverage of tasks and data modalities, including previously unexplored domains such as speech and video classification. Our evaluation show that RandLabel and SalUn are the most effective general MU approaches on MU-Bench, and BadT and SCRUB are capable of achieving random performance on the deletion set. We analyze several under-investigated aspects of unlearning, including scalability, the impacts of parameter-efficient fine-tuning and curriculum learning, and susceptibility to dataset biases. MU-Bench provides an easy-to-use package that includes dataset splits, models, and implementations, together with a leader board to enable unified and scalable MU research.
6/24/2024