MU-Bench: A Multitask Multimodal Benchmark for Machine Unlearning
2406.14796
0
0
Abstract
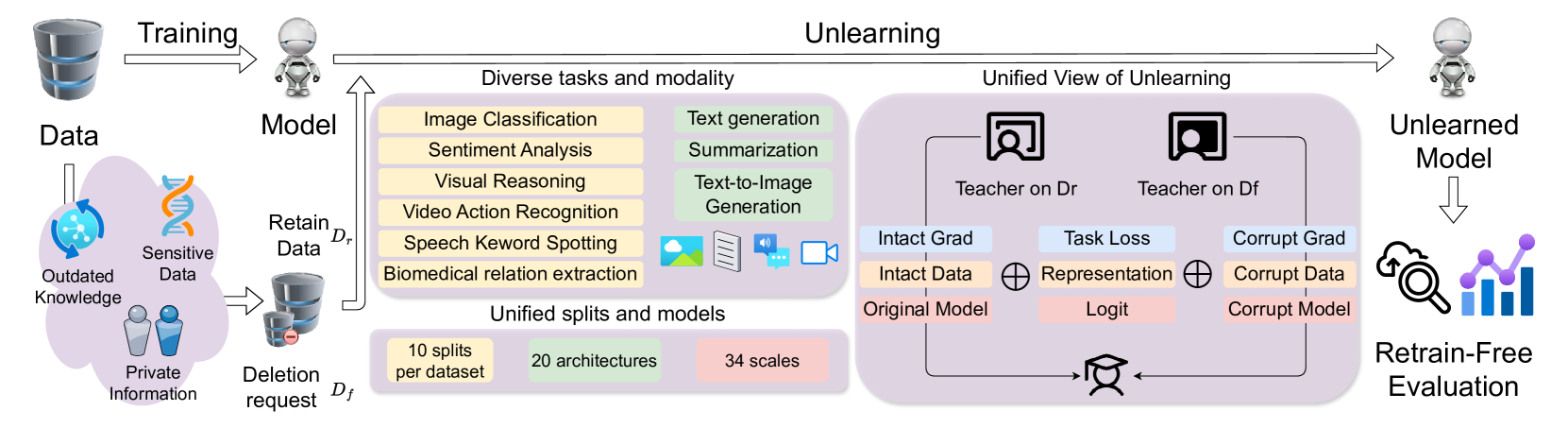
Recent advancements in Machine Unlearning (MU) have introduced solutions to selectively remove certain training samples, such as those with outdated or sensitive information, from trained models. Despite these advancements, evaluation of MU methods have been inconsistent, employing different trained models and architectures, and sample removal strategies, which hampers accurate comparison. In addition, prior MU approaches have mainly focused on singular tasks or modalities, which is not comprehensive. To address these limitations, we develop MU-Bench, the first comprehensive benchmark for MU that (i) unifies the sets of deleted samples and trained models, and (ii) provides broad coverage of tasks and data modalities, including previously unexplored domains such as speech and video classification. Our evaluation show that RandLabel and SalUn are the most effective general MU approaches on MU-Bench, and BadT and SCRUB are capable of achieving random performance on the deletion set. We analyze several under-investigated aspects of unlearning, including scalability, the impacts of parameter-efficient fine-tuning and curriculum learning, and susceptibility to dataset biases. MU-Bench provides an easy-to-use package that includes dataset splits, models, and implementations, together with a leader board to enable unified and scalable MU research.
Create account to get full access
Overview
- This paper introduces MU-Bench, a new benchmark for evaluating machine unlearning techniques across multiple tasks and modalities.
- Machine unlearning is the process of removing the influence of specific data points from a trained model, which is important for data privacy and model maintenance.
- MU-Bench consists of several datasets and tasks, including image classification, text classification, and multimodal learning, to provide a comprehensive evaluation of unlearning performance.
Plain English Explanation
Machine learning models are trained on large datasets, but sometimes the data used to train the model contains sensitive or private information. Machine unlearning is the process of removing the influence of specific data points from a trained model, so that the model no longer contains or "remembers" that sensitive information.
The MU-Bench benchmark provides a way to test and compare different machine unlearning techniques across a variety of tasks and data types. It includes datasets and tasks for image classification, text classification, and multimodal learning (combining text and images), so that researchers can evaluate how well their unlearning methods work in different real-world scenarios.
This is important because previous benchmarks have been limited in scope, focusing on a single task or data type. MU-Bench offers a more comprehensive and challenging set of scenarios to test the robustness and effectiveness of unlearning techniques.
By having a standardized benchmark like MU-Bench, researchers can more easily compare the performance of different unlearning methods and identify the best approaches for real-world applications where data privacy and model maintenance are important.
Technical Explanation
The MU-Bench benchmark consists of several datasets and tasks that cover a range of modalities and learning problems. These include:
- Image classification: Classifying images from the CIFAR-10 and ImageNet datasets.
- Text classification: Classifying text from the AG News and Yelp Review Polarity datasets.
- Multimodal learning: Combining text and images to predict sentiment, using the Multi30K dataset.
For each task, the benchmark defines a set of data points that should be "unlearned" from the model, and evaluates the model's performance before and after unlearning. This allows researchers to assess the effectiveness of their unlearning techniques in terms of both
The paper also introduces new evaluation metrics, such as
Critical Analysis
The MU-Bench benchmark addresses an important challenge in machine learning, namely the need for techniques to remove sensitive or private information from trained models. The authors have done a commendable job in designing a comprehensive set of tasks and datasets to evaluate unlearning performance.
However, the paper does not explore the potential limitations or failure modes of machine unlearning. For example, the authors do not discuss the possibility of unintended data memorization or the impact of different unlearning techniques on model robustness and generalization.
Additionally, the paper focuses primarily on evaluating unlearning performance and does not provide much insight into the computational complexity or practical implementation challenges of the various unlearning methods. Further research is needed to understand the real-world tradeoffs and practical considerations of deploying machine unlearning in production.
Conclusion
The MU-Bench benchmark represents a significant contribution to the field of machine unlearning, providing a standardized and comprehensive evaluation platform for researchers and practitioners. By testing unlearning techniques across a diverse set of tasks and modalities, the benchmark can help drive the development of more robust and effective unlearning methods.
As machine learning models become more ubiquitous and powerful, the ability to selectively remove sensitive information from these models will become increasingly important for data privacy, model maintenance, and responsible AI development. The MU-Bench benchmark is a valuable tool for advancing this critical area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Single Image Unlearning: Efficient Machine Unlearning in Multimodal Large Language Models
Jiaqi Li, Qianshan Wei, Chuanyi Zhang, Guilin Qi, Miaozeng Du, Yongrui Chen, Sheng Bi
0
0
Machine unlearning empowers individuals with the `right to be forgotten' by removing their private or sensitive information encoded in machine learning models. However, it remains uncertain whether MU can be effectively applied to Multimodal Large Language Models (MLLMs), particularly in scenarios of forgetting the leaked visual data of concepts. To overcome the challenge, we propose an efficient method, Single Image Unlearning (SIU), to unlearn the visual recognition of a concept by fine-tuning a single associated image for few steps. SIU consists of two key aspects: (i) Constructing Multifaceted fine-tuning data. We introduce four targets, based on which we construct fine-tuning data for the concepts to be forgotten; (ii) Jointly training loss. To synchronously forget the visual recognition of concepts and preserve the utility of MLLMs, we fine-tune MLLMs through a novel Dual Masked KL-divergence Loss combined with Cross Entropy loss. Alongside our method, we establish MMUBench, a new benchmark for MU in MLLMs and introduce a collection of metrics for its evaluation. Experimental results on MMUBench show that SIU completely surpasses the performance of existing methods. Furthermore, we surprisingly find that SIU can avoid invasive membership inference attacks and jailbreak attacks. To the best of our knowledge, we are the first to explore MU in MLLMs. We will release the code and benchmark in the near future.
5/30/2024

MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
Fei Wang, Xingyu Fu, James Y. Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, Tianyi Lorena Yan, Wenjie Jacky Mo, Hsiang-Hui Liu, Pan Lu, Chunyuan Li, Chaowei Xiao, Kai-Wei Chang, Dan Roth, Sheng Zhang, Hoifung Poon, Muhao Chen
0
0
We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations). Comprising 11,264 images and 2,600 multiple-choice questions, MuirBench is created in a pairwise manner, where each standard instance is paired with an unanswerable variant that has minimal semantic differences, in order for a reliable assessment. Evaluated upon 20 recent multi-modal LLMs, our results reveal that even the best-performing models like GPT-4o and Gemini Pro find it challenging to solve MuirBench, achieving 68.0% and 49.3% in accuracy. Open-source multimodal LLMs trained on single images can hardly generalize to multi-image questions, hovering below 33.3% in accuracy. These results highlight the importance of MuirBench in encouraging the community to develop multimodal LLMs that can look beyond a single image, suggesting potential pathways for future improvements.
6/14/2024

Gone but Not Forgotten: Improved Benchmarks for Machine Unlearning
Keltin Grimes, Collin Abidi, Cole Frank, Shannon Gallagher
0
0
Machine learning models are vulnerable to adversarial attacks, including attacks that leak information about the model's training data. There has recently been an increase in interest about how to best address privacy concerns, especially in the presence of data-removal requests. Machine unlearning algorithms aim to efficiently update trained models to comply with data deletion requests while maintaining performance and without having to resort to retraining the model from scratch, a costly endeavor. Several algorithms in the machine unlearning literature demonstrate some level of privacy gains, but they are often evaluated only on rudimentary membership inference attacks, which do not represent realistic threats. In this paper we describe and propose alternative evaluation methods for three key shortcomings in the current evaluation of unlearning algorithms. We show the utility of our alternative evaluations via a series of experiments of state-of-the-art unlearning algorithms on different computer vision datasets, presenting a more detailed picture of the state of the field.
5/30/2024

Challenging Forgets: Unveiling the Worst-Case Forget Sets in Machine Unlearning
Chongyu Fan, Jiancheng Liu, Alfred Hero, Sijia Liu
0
0
The trustworthy machine learning (ML) community is increasingly recognizing the crucial need for models capable of selectively 'unlearning' data points after training. This leads to the problem of machine unlearning (MU), aiming to eliminate the influence of chosen data points on model performance, while still maintaining the model's utility post-unlearning. Despite various MU methods for data influence erasure, evaluations have largely focused on random data forgetting, ignoring the vital inquiry into which subset should be chosen to truly gauge the authenticity of unlearning performance. To tackle this issue, we introduce a new evaluative angle for MU from an adversarial viewpoint. We propose identifying the data subset that presents the most significant challenge for influence erasure, i.e., pinpointing the worst-case forget set. Utilizing a bi-level optimization principle, we amplify unlearning challenges at the upper optimization level to emulate worst-case scenarios, while simultaneously engaging in standard training and unlearning at the lower level, achieving a balance between data influence erasure and model utility. Our proposal offers a worst-case evaluation of MU's resilience and effectiveness. Through extensive experiments across different datasets (including CIFAR-10, 100, CelebA, Tiny ImageNet, and ImageNet) and models (including both image classifiers and generative models), we expose critical pros and cons in existing (approximate) unlearning strategies. Our results illuminate the complex challenges of MU in practice, guiding the future development of more accurate and robust unlearning algorithms. The code is available at https://github.com/OPTML-Group/Unlearn-WorstCase.
7/2/2024