Single-Trajectory Distributionally Robust Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- Reinforcement learning (RL) is a powerful tool for training agents to solve complex problems, but it relies heavily on having identical training and test environments.
- Distributionally Robust RL (DRRL) aims to enhance RL performance across a range of environments, even unknown test environments.
- DRRL involves optimizing over a set of distributions, which is more challenging than optimizing over a fixed distribution in the non-robust case.
- Existing DRRL algorithms are either model-based or fail to learn from a single sample trajectory.
Plain English Explanation
Reinforcement learning is a way for computer programs to learn how to solve problems by trying different actions and getting rewards or punishments. But traditional reinforcement learning approaches rely on the training environment being the same as the testing environment. This can be a problem when the real-world environment is different from the training environment.
To address this limitation, Distributionally Robust RL (DRRL) was developed. DRRL aims to create reinforcement learning agents that can perform well across a variety of environments, even ones that are different from the training environment. This is done by optimizing the agent's performance over a set of possible environments, rather than just a single fixed environment.
However, optimizing over a set of environments is more complex than just optimizing for a single environment. Additionally, existing DRRL algorithms either rely on having a model of the environment (known as model-based RL) or cannot learn effectively from a single trajectory of experience (known as model-free RL).
Technical Explanation
In this paper, the authors propose a new Distributionally Robust Q-learning (DRQ) algorithm that is fully model-free. This means the algorithm can learn the optimal distributionally robust policy directly from a single trajectory of experience, without requiring a model of the environment.
The key innovation is a multi-timescale framework that allows the algorithm to fully utilize each new sample of experience as it arrives. This enables the algorithm to learn the optimal distributionally robust policy in a sample-efficient manner.
The authors provide theoretical guarantees that the DRQ algorithm will converge asymptotically, by generalizing classical stochastic approximation tools. Comprehensive experiments demonstrate that DRQ outperforms both non-robust RL methods and other existing DRRL algorithms in terms of robustness and sample complexity.
Critical Analysis
The main limitation of this research is that it assumes the set of possible environments is known a priori. In real-world applications, the set of possible environments may not be fully known in advance. Further research is needed to relax this assumption and develop DRRL algorithms that can handle unknown or open-ended environment distributions.
Additionally, the theoretical convergence guarantees provided in the paper rely on several strong assumptions, such as the convexity of the optimization problem. It would be valuable to investigate the performance of the DRQ algorithm under more realistic and less restrictive conditions.
Conclusion
This paper presents a novel Distributionally Robust Q-learning (DRQ) algorithm that is the first fully model-free approach to Distributionally Robust Reinforcement Learning (DRRL). By using a multi-timescale framework, DRQ can learn the optimal distributionally robust policy directly from a single trajectory of experience, without requiring a model of the environment.
The superior performance of DRQ in terms of robustness and sample complexity, demonstrated through comprehensive experiments, suggests that this approach could be a valuable tool for developing reinforcement learning agents that can reliably perform well across a variety of real-world environments. Further research to address the identified limitations could lead to even more powerful and practical DRRL algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Single-Trajectory Distributionally Robust Reinforcement Learning
Zhipeng Liang, Xiaoteng Ma, Jose Blanchet, Jiheng Zhang, Zhengyuan Zhou
To mitigate the limitation that the classical reinforcement learning (RL) framework heavily relies on identical training and test environments, Distributionally Robust RL (DRRL) has been proposed to enhance performance across a range of environments, possibly including unknown test environments. As a price for robustness gain, DRRL involves optimizing over a set of distributions, which is inherently more challenging than optimizing over a fixed distribution in the non-robust case. Existing DRRL algorithms are either model-based or fail to learn from a single sample trajectory. In this paper, we design a first fully model-free DRRL algorithm, called distributionally robust Q-learning with single trajectory (DRQ). We delicately design a multi-timescale framework to fully utilize each incrementally arriving sample and directly learn the optimal distributionally robust policy without modelling the environment, thus the algorithm can be trained along a single trajectory in a model-free fashion. Despite the algorithm's complexity, we provide asymptotic convergence guarantees by generalizing classical stochastic approximation tools. Comprehensive experimental results demonstrate the superior robustness and sample complexity of our proposed algorithm, compared to non-robust methods and other robust RL algorithms.
Read more9/24/2024

0
Continuous Control Reinforcement Learning: Distributed Distributional DrQ Algorithms
Zehao Zhou
Distributed Distributional DrQ is a model-free and off-policy RL algorithm for continuous control tasks based on the state and observation of the agent, which is an actor-critic method with the data-augmentation and the distributional perspective of critic value function. Aim to learn to control the agent and master some tasks in a high-dimensional continuous space. DrQ-v2 uses DDPG as the backbone and achieves out-performance in various continuous control tasks. Here Distributed Distributional DrQ uses Distributed Distributional DDPG as the backbone, and this modification aims to achieve better performance in some hard continuous control tasks through the better expression ability of distributional value function and distributed actor policies.
Read more4/17/2024
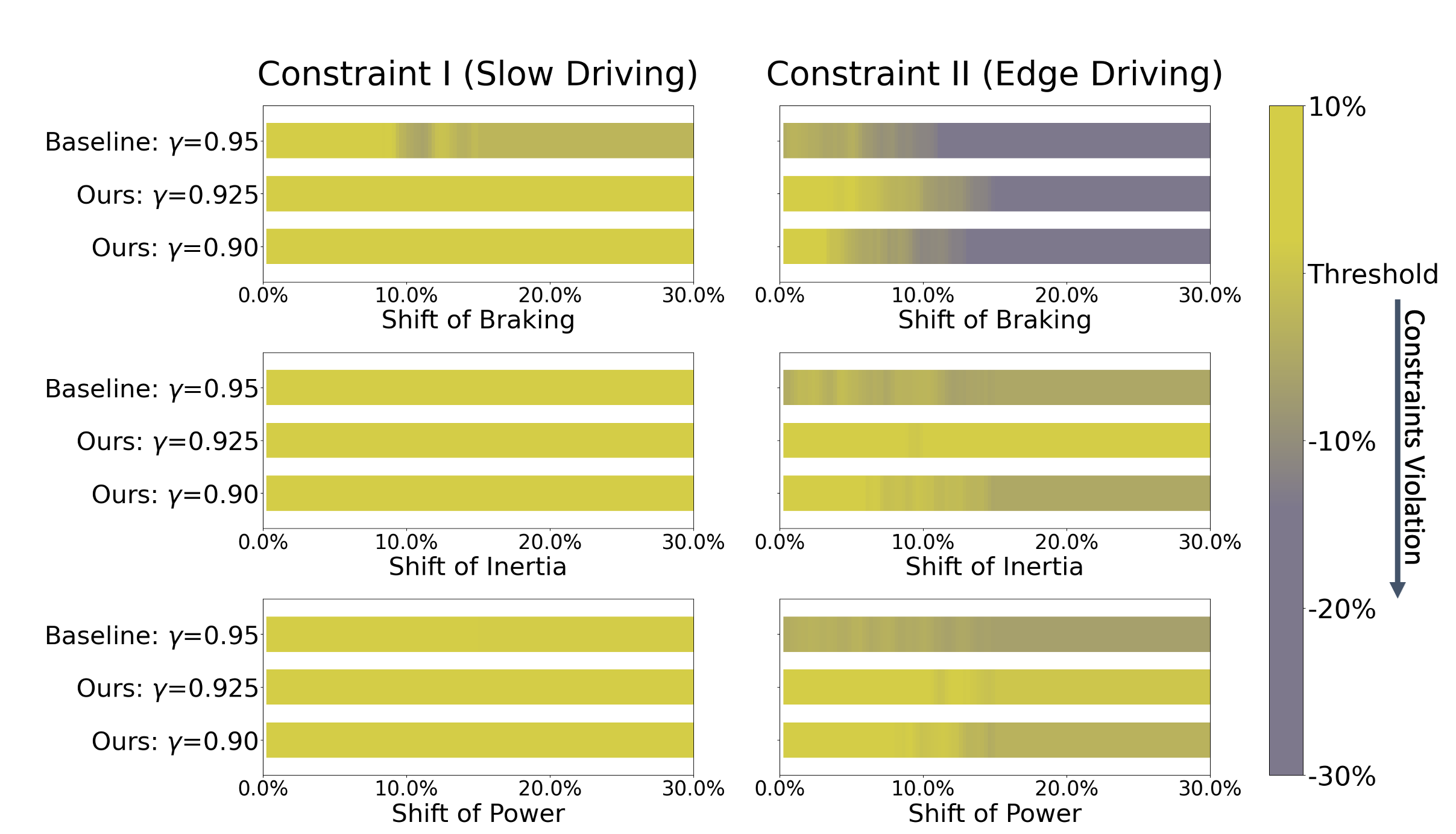
0
Distributionally Robust Constrained Reinforcement Learning under Strong Duality
Zhengfei Zhang, Kishan Panaganti, Laixi Shi, Yanan Sui, Adam Wierman, Yisong Yue
We study the problem of Distributionally Robust Constrained RL (DRC-RL), where the goal is to maximize the expected reward subject to environmental distribution shifts and constraints. This setting captures situations where training and testing environments differ, and policies must satisfy constraints motivated by safety or limited budgets. Despite significant progress toward algorithm design for the separate problems of distributionally robust RL and constrained RL, there do not yet exist algorithms with end-to-end convergence guarantees for DRC-RL. We develop an algorithmic framework based on strong duality that enables the first efficient and provable solution in a class of environmental uncertainties. Further, our framework exposes an inherent structure of DRC-RL that arises from the combination of distributional robustness and constraints, which prevents a popular class of iterative methods from tractably solving DRC-RL, despite such frameworks being applicable for each of distributionally robust RL and constrained RL individually. Finally, we conduct experiments on a car racing benchmark to evaluate the effectiveness of the proposed algorithm.
Read more6/26/2024
0
Sample-Efficient Robust Multi-Agent Reinforcement Learning in the Face of Environmental Uncertainty
Laixi Shi, Eric Mazumdar, Yuejie Chi, Adam Wierman
To overcome the sim-to-real gap in reinforcement learning (RL), learned policies must maintain robustness against environmental uncertainties. While robust RL has been widely studied in single-agent regimes, in multi-agent environments, the problem remains understudied -- despite the fact that the problems posed by environmental uncertainties are often exacerbated by strategic interactions. This work focuses on learning in distributionally robust Markov games (RMGs), a robust variant of standard Markov games, wherein each agent aims to learn a policy that maximizes its own worst-case performance when the deployed environment deviates within its own prescribed uncertainty set. This results in a set of robust equilibrium strategies for all agents that align with classic notions of game-theoretic equilibria. Assuming a non-adaptive sampling mechanism from a generative model, we propose a sample-efficient model-based algorithm (DRNVI) with finite-sample complexity guarantees for learning robust variants of various notions of game-theoretic equilibria. We also establish an information-theoretic lower bound for solving RMGs, which confirms the near-optimal sample complexity of DRNVI with respect to problem-dependent factors such as the size of the state space, the target accuracy, and the horizon length.
Read more5/10/2024