Skeleton-Based Human Action Recognition with Noisy Labels

0

Sign in to get full access
Overview
- This research paper explores a method for human action recognition using skeleton data, even when the training labels are noisy or imperfect.
- The proposed approach leverages the rich contextual information in skeleton data to overcome the challenges posed by inaccurate or incomplete labels.
- The paper presents a novel model architecture and training strategy to make skeleton-based action recognition more robust to noisy labels.
Plain English Explanation
Imagine you're trying to teach a computer to recognize different human actions, like walking, jumping, or waving. One way to do this is by using "skeleton data" - the positions of key joints in the body over time. This can provide a lot of useful information about the shape and movement of the human body.
However, the data you use to train the computer (the "labels") might not always be perfect. There could be mistakes or inconsistencies in how the actions were originally labeled. This can make it really hard for the computer to learn the correct associations between the skeleton data and the different actions.
The researchers in this paper came up with a new approach to make the computer's learning more robust to these noisy or imperfect labels. Instead of just relying on the labels, their model also looks at the rich contextual information in the skeleton data itself. This helps the computer figure out the right actions, even when the labels aren't 100% accurate.
The key innovation is a special model architecture and training strategy that allows the computer to learn effective action recognition despite the noisy labels. This could be really useful in real-world applications where perfect training data is hard to come by, but skeleton data is available.
Technical Explanation
The paper proposes a Skeleton-based Human Action Recognition with Noisy Labels model that can effectively learn action recognition from noisy or imperfect training labels.
The core idea is to leverage the rich contextual information contained in skeleton data to overcome the challenges posed by inaccurate or incomplete labels. The authors introduce a novel model architecture and training strategy that enables robust action recognition even when the training labels are noisy.
Specifically, the model uses a Transformer-based backbone to capture the complex spatial-temporal relationships in the skeleton data. This is combined with a Self-Supervised Learning module that learns useful feature representations without relying solely on the provided labels.
During training, the model employs a Joint Optimization strategy that simultaneously optimizes the action recognition task and the self-supervised learning objective. This allows the model to learn robust features that are less sensitive to label noise.
The authors evaluate their approach on several benchmark datasets for skeleton-based action recognition, including NTU RGB+D and Kinetics. The results demonstrate that their method significantly outperforms baseline approaches, especially when the training labels are noisy or corrupted.
Critical Analysis
The paper presents a compelling approach to improving skeleton-based action recognition in the presence of noisy labels. The authors' key insight - leveraging the rich contextual information in skeleton data to overcome label noise - is well-justified and the proposed model architecture seems well-designed to implement this idea.
One potential limitation is the computational complexity of the Transformer-based backbone, which could make the model less efficient for real-time applications. The authors do not provide an in-depth analysis of the model's inference speed or resource requirements.
Additionally, the paper does not explore the impact of different types or degrees of label noise on the model's performance. It would be helpful to understand how the approach scales as the label noise becomes more severe or follows different statistical distributions.
Further research could also investigate the generalization of this method to other modalities beyond skeleton data, such as RGB video or multimodal inputs. Exploring ways to actively identify and correct noisy labels during training could also be a fruitful direction.
Overall, this paper presents an interesting and promising approach to making skeleton-based action recognition more robust and practical for real-world applications with imperfect training data.
Conclusion
This research paper introduces a novel method for skeleton-based human action recognition that can effectively learn from noisy or imperfect training labels. By leveraging the rich contextual information in skeleton data and employing a carefully designed model architecture and training strategy, the proposed approach demonstrates significant improvements over baseline methods, especially when dealing with noisy labels.
The key contributions of this work include the innovative use of self-supervised learning and joint optimization to make the model more robust to label noise, as well as the demonstrated performance gains on standard benchmarks. While the computational complexity of the model could be a consideration for some applications, the paper presents an important step towards making skeleton-based action recognition more practical and reliable in real-world settings with imperfect training data.
Further research exploring the generalization of this approach, as well as its scalability to different types and degrees of label noise, could lead to even more impactful advancements in this area of computer vision and human activity understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Skeleton-Based Human Action Recognition with Noisy Labels
Yi Xu, Kunyu Peng, Di Wen, Ruiping Liu, Junwei Zheng, Yufan Chen, Jiaming Zhang, Alina Roitberg, Kailun Yang, Rainer Stiefelhagen
Understanding human actions from body poses is critical for assistive robots sharing space with humans in order to make informed and safe decisions about the next interaction. However, precise temporal localization and annotation of activity sequences is time-consuming and the resulting labels are often noisy. If not effectively addressed, label noise negatively affects the model's training, resulting in lower recognition quality. Despite its importance, addressing label noise for skeleton-based action recognition has been overlooked so far. In this study, we bridge this gap by implementing a framework that augments well-established skeleton-based human action recognition methods with label-denoising strategies from various research areas to serve as the initial benchmark. Observations reveal that these baselines yield only marginal performance when dealing with sparse skeleton data. Consequently, we introduce a novel methodology, NoiseEraSAR, which integrates global sample selection, co-teaching, and Cross-Modal Mixture-of-Experts (CM-MOE) strategies, aimed at mitigating the adverse impacts of label noise. Our proposed approach demonstrates better performance on the established benchmark, setting new state-of-the-art standards. The source code for this study is accessible at https://github.com/xuyizdby/NoiseEraSAR.
Read more8/7/2024
0
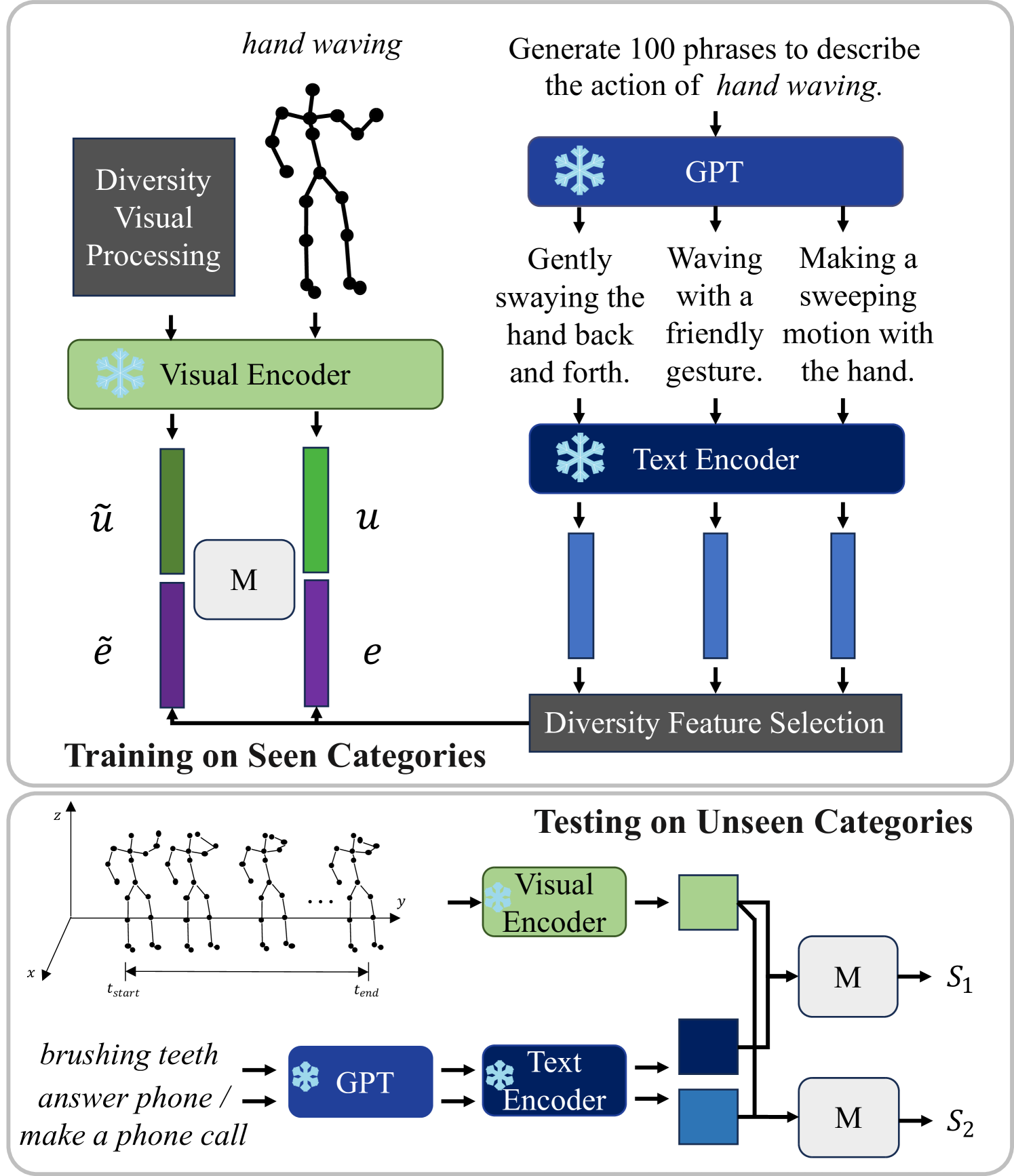
An Information Compensation Framework for Zero-Shot Skeleton-based Action Recognition
Haojun Xu, Yan Gao, Jie Li, Xinbo Gao
Zero-shot human skeleton-based action recognition aims to construct a model that can recognize actions outside the categories seen during training. Previous research has focused on aligning sequences' visual and semantic spatial distributions. However, these methods extract semantic features simply. They ignore that proper prompt design for rich and fine-grained action cues can provide robust representation space clustering. In order to alleviate the problem of insufficient information available for skeleton sequences, we design an information compensation learning framework from an information-theoretic perspective to improve zero-shot action recognition accuracy with a multi-granularity semantic interaction mechanism. Inspired by ensemble learning, we propose a multi-level alignment (MLA) approach to compensate information for action classes. MLA aligns multi-granularity embeddings with visual embedding through a multi-head scoring mechanism to distinguish semantically similar action names and visually similar actions. Furthermore, we introduce a new loss function sampling method to obtain a tight and robust representation. Finally, these multi-granularity semantic embeddings are synthesized to form a proper decision surface for classification. Significant action recognition performance is achieved when evaluated on the challenging NTU RGB+D, NTU RGB+D 120, and PKU-MMD benchmarks and validate that multi-granularity semantic features facilitate the differentiation of action clusters with similar visual features.
Read more6/4/2024

0
Multi-Modality Co-Learning for Efficient Skeleton-based Action Recognition
Jinfu Liu, Chen Chen, Mengyuan Liu
Skeleton-based action recognition has garnered significant attention due to the utilization of concise and resilient skeletons. Nevertheless, the absence of detailed body information in skeletons restricts performance, while other multimodal methods require substantial inference resources and are inefficient when using multimodal data during both training and inference stages. To address this and fully harness the complementary multimodal features, we propose a novel multi-modality co-learning (MMCL) framework by leveraging the multimodal large language models (LLMs) as auxiliary networks for efficient skeleton-based action recognition, which engages in multi-modality co-learning during the training stage and keeps efficiency by employing only concise skeletons in inference. Our MMCL framework primarily consists of two modules. First, the Feature Alignment Module (FAM) extracts rich RGB features from video frames and aligns them with global skeleton features via contrastive learning. Second, the Feature Refinement Module (FRM) uses RGB images with temporal information and text instruction to generate instructive features based on the powerful generalization of multimodal LLMs. These instructive text features will further refine the classification scores and the refined scores will enhance the model's robustness and generalization in a manner similar to soft labels. Extensive experiments on NTU RGB+D, NTU RGB+D 120 and Northwestern-UCLA benchmarks consistently verify the effectiveness of our MMCL, which outperforms the existing skeleton-based action recognition methods. Meanwhile, experiments on UTD-MHAD and SYSU-Action datasets demonstrate the commendable generalization of our MMCL in zero-shot and domain-adaptive action recognition. Our code is publicly available at: https://github.com/liujf69/MMCL-Action.
Read more8/7/2024
👁️
0
Expressive Keypoints for Skeleton-based Action Recognition via Skeleton Transformation
Yijie Yang, Jinlu Zhang, Jiaxu Zhang, Zhigang Tu
In the realm of skeleton-based action recognition, the traditional methods which rely on coarse body keypoints fall short of capturing subtle human actions. In this work, we propose Expressive Keypoints that incorporates hand and foot details to form a fine-grained skeletal representation, improving the discriminative ability for existing models in discerning intricate actions. To efficiently model Expressive Keypoints, the Skeleton Transformation strategy is presented to gradually downsample the keypoints and prioritize prominent joints by allocating the importance weights. Additionally, a plug-and-play Instance Pooling module is exploited to extend our approach to multi-person scenarios without surging computation costs. Extensive experimental results over seven datasets present the superiority of our method compared to the state-of-the-art for skeleton-based human action recognition. Code is available at https://github.com/YijieYang23/SkeleT-GCN.
Read more6/27/2024