Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
2402.14800
0
0

Abstract
A pivotal advancement in the progress of large language models (LLMs) is the emergence of the Mixture-of-Experts (MoE) LLMs. Compared to traditional LLMs, MoE LLMs can achieve higher performance with fewer parameters, but it is still hard to deploy them due to their immense parameter sizes. Different from previous weight pruning methods that rely on specifically designed hardware, this paper mainly aims to enhance the deployment efficiency of MoE LLMs by introducing plug-and-play expert-level sparsification techniques. Specifically, we propose, for the first time to our best knowledge, post-training approaches for task-agnostic and task-specific expert pruning and skipping of MoE LLMs, tailored to improve deployment efficiency while maintaining model performance across a wide range of tasks. Extensive experiments show that our proposed methods can simultaneously reduce model sizes and increase the inference speed, while maintaining satisfactory performance. Data and code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
Create account to get full access
Overview
- This paper introduces a method for efficiently pruning and skipping experts in Mixture-of-Experts (MoE) Large Language Models (LLMs).
- MoE LLMs are a type of AI model that uses a collection of specialized "expert" sub-models to process different parts of the input, rather than a single monolithic model.
- The proposed method aims to improve the efficiency of MoE LLMs by selectively activating only the most relevant experts for a given input, reducing the computational cost without sacrificing performance.
Plain English Explanation
Large language models (LLMs) are advanced AI systems that can generate human-like text, answer questions, and perform a variety of language-related tasks. These models are often very complex and computationally intensive, making them expensive to run and difficult to deploy in real-world applications.
To address this, researchers have developed a technique called Mixture-of-Experts (MoE), where the LLM is divided into a collection of smaller, specialized "expert" sub-models. When presented with an input, the MoE model selects the most relevant experts to process that input, rather than using the entire model.
This paper introduces a method to further improve the efficiency of MoE LLMs by selectively activating only the most relevant experts for each input. This is done through a process of "expert pruning" and "expert skipping," which allows the model to quickly identify the most important experts and focus its computational resources on those, rather than processing all the experts for every input.
The key idea is that not all experts are equally important for a given input, so by quickly identifying and activating only the most relevant experts, the model can become more efficient without sacrificing performance. This could make MoE LLMs more practical for real-world applications, such as powering chatbots, language translation tools, or content generation systems.
Technical Explanation
The paper proposes two main techniques to improve the efficiency of MoE LLMs:
-
Expert Pruning: The model first assigns a relevance score to each expert, indicating how important that expert is for a given input. It then selectively activates only the top-k most relevant experts, pruning the less important ones to save computational resources.
-
Expert Skipping: In addition to pruning, the model can also skip the activation of certain experts entirely, further reducing the computational cost. This is done by predicting which experts are unlikely to be relevant and bypassing them without even computing their relevance scores.
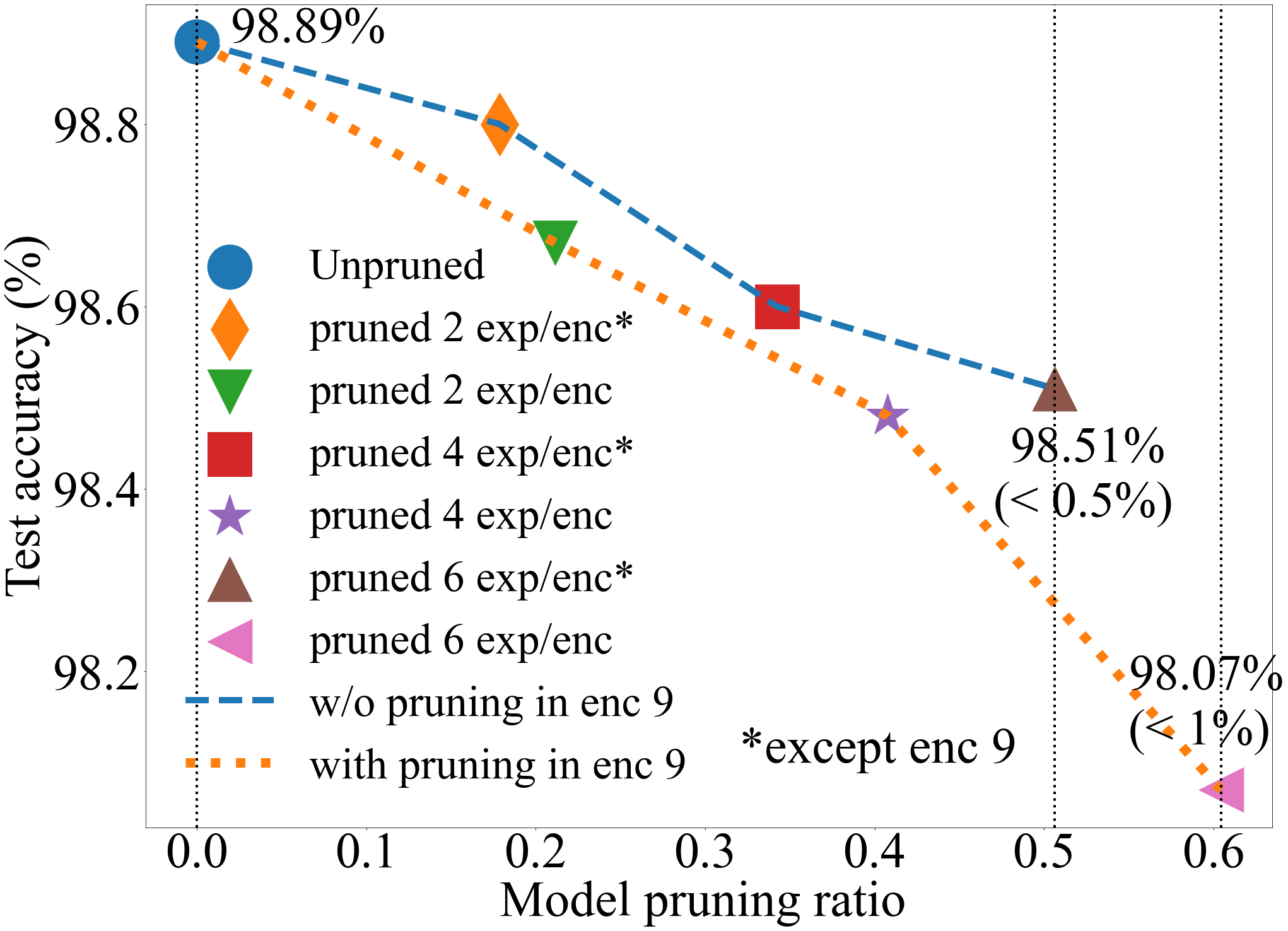
The authors demonstrate the effectiveness of their approach through a series of experiments on various MoE LLM architectures, including XMoE, iaMoE, and HyperMoE. They show that their methods can achieve significant computational savings (up to 50% reduction in FLOPs) without compromising the model's performance on a variety of language tasks.
The key insight is that not all experts are equally important for a given input, and by selectively activating only the most relevant ones, the model can become more efficient. This builds on prior work in Provably Effective Pruning of Experts in Fine-tuned Models and Toward Inference-Optimal Mixture of Experts for Large Language Models.
Critical Analysis
The proposed methods for expert pruning and skipping seem well-designed and effectively demonstrated on several MoE LLM architectures. The authors provide a thorough analysis of the trade-offs between computational savings and model performance, showing that their techniques can achieve significant efficiency gains without sacrificing accuracy.
However, one potential limitation is that the methods may not generalize as well to more complex or diverse input data distributions. The experiments in the paper focus on standard language modeling and question-answering tasks, but it's possible that the expert pruning and skipping strategies could be less effective in more open-ended or domain-specific applications.
Additionally, the paper does not explore the potential implications of selectively activating experts on the overall interpretability and explainability of the MoE LLM. By prioritizing certain experts over others, the model's decision-making process may become less transparent, which could be a concern in applications where accountability and trust are important.
Further research could investigate the robustness of the proposed techniques to more challenging or diverse tasks, as well as the potential impacts on model interpretability and trustworthiness. Nonetheless, this paper represents an important contribution to the ongoing efforts to make large language models more efficient and practical for real-world use.
Conclusion
This paper introduces a novel method for efficiently pruning and skipping experts in Mixture-of-Experts large language models. By selectively activating only the most relevant experts for a given input, the proposed techniques can achieve significant computational savings without compromising model performance.
The insights and techniques presented in this work have the potential to make large language models more practical and cost-effective for deployment in a wide range of applications, from chatbots and language translation to content generation and personalized recommendations. As the field of natural language processing continues to advance, research like this will be crucial in bridging the gap between powerful AI models and real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Provably Effective Method for Pruning Experts in Fine-tuned Sparse Mixture-of-Experts
Mohammed Nowaz Rabbani Chowdhury, Meng Wang, Kaoutar El Maghraoui, Naigang Wang, Pin-Yu Chen, Christopher Carothers
0
0
The sparsely gated mixture of experts (MoE) architecture sends different inputs to different subnetworks, i.e., experts, through trainable routers. MoE reduces the training computation significantly for large models, but its deployment can be still memory or computation expensive for some downstream tasks. Model pruning is a popular approach to reduce inference computation, but its application in MoE architecture is largely unexplored. To the best of our knowledge, this paper provides the first provably efficient technique for pruning experts in finetuned MoE models. We theoretically prove that prioritizing the pruning of the experts with a smaller change of the routers l2 norm from the pretrained model guarantees the preservation of test accuracy, while significantly reducing the model size and the computational requirements. Although our theoretical analysis is centered on binary classification tasks on simplified MoE architecture, our expert pruning method is verified on large vision MoE models such as VMoE and E3MoE finetuned on benchmark datasets such as CIFAR10, CIFAR100, and ImageNet.
5/31/2024

Demystifying the Compression of Mixture-of-Experts Through a Unified Framework
Shwai He, Daize Dong, Liang Ding, Ang Li
0
0
Scaling large language models has revolutionized the performance across diverse domains, yet the continual growth in model size poses significant challenges for real-world deployment. The Mixture of Experts (MoE) approach addresses this by dynamically selecting and activating only a subset of experts, significantly reducing computational costs while maintaining high performance. However, MoE introduces potential redundancy (e.g., parameters) and extra costs (e.g., communication overhead). Despite numerous compression techniques developed for mitigating the redundancy in dense models, the compression of MoE remains under-explored. We first bridge this gap with a cutting-edge unified framework that not only seamlessly integrates mainstream compression methods but also helps systematically understand MoE compression. This framework approaches compression from two perspectives: Expert Slimming which compresses individual experts and Expert Trimming which removes structured modules. Within this framework, we explore the optimization space unexplored by existing methods,and further introduce aggressive Expert Trimming techniques, i.e., Layer Drop and Block Drop, to eliminate redundancy at larger scales. Based on these insights,we present a comprehensive recipe to guide practitioners in compressing MoE effectively. Extensive experimental results demonstrate the effectiveness of the compression methods under our framework and the proposed recipe, achieving a 6.05x speedup and only 20.0GB memory usage while maintaining over 92% of performance on Mixtral-8x7B.
6/5/2024

A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
0
0
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
6/27/2024
XMoE: Sparse Models with Fine-grained and Adaptive Expert Selection
Yuanhang Yang, Shiyi Qi, Wenchao Gu, Chaozheng Wang, Cuiyun Gao, Zenglin Xu
0
0
Sparse models, including sparse Mixture-of-Experts (MoE) models, have emerged as an effective approach for scaling Transformer models. However, they often suffer from computational inefficiency since a significant number of parameters are unnecessarily involved in computations via multiplying values by zero or low activation values. To address this issue, we present tool, a novel MoE designed to enhance both the efficacy and efficiency of sparse MoE models. tool leverages small experts and a threshold-based router to enable tokens to selectively engage only essential parameters. Our extensive experiments on language modeling and machine translation tasks demonstrate that tool can enhance model performance while decreasing the computation load at MoE layers by over 50% without sacrificing performance. Furthermore, we present the versatility of tool by applying it to dense models, enabling sparse computation during inference. We provide a comprehensive analysis and make our code available at https://github.com/ysngki/XMoE.
5/27/2024