SleepVST: Sleep Staging from Near-Infrared Video Signals using Pre-Trained Transformers
2404.03831
0
0

Abstract
Advances in camera-based physiological monitoring have enabled the robust, non-contact measurement of respiration and the cardiac pulse, which are known to be indicative of the sleep stage. This has led to research into camera-based sleep monitoring as a promising alternative to gold-standard polysomnography, which is cumbersome, expensive to administer, and hence unsuitable for longer-term clinical studies. In this paper, we introduce SleepVST, a transformer model which enables state-of-the-art performance in camera-based sleep stage classification (sleep staging). After pre-training on contact sensor data, SleepVST outperforms existing methods for cardio-respiratory sleep staging on the SHHS and MESA datasets, achieving total Cohen's kappa scores of 0.75 and 0.77 respectively. We then show that SleepVST can be successfully transferred to cardio-respiratory waveforms extracted from video, enabling fully contact-free sleep staging. Using a video dataset of 50 nights, we achieve a total accuracy of 78.8% and a Cohen's $kappa$ of 0.71 in four-class video-based sleep staging, setting a new state-of-the-art in the domain.
Create account to get full access
Overview
- This paper presents a new sleep staging model called SleepVST that uses pre-trained transformer networks to analyze near-infrared video signals and classify sleep stages.
- The model is designed to enable contact-free, continuous sleep monitoring using non-invasive video cameras.
- The authors evaluate SleepVST on several public sleep datasets and show it outperforms existing video-based sleep staging approaches.
Plain English Explanation
The paper introduces a new AI system called SleepVST that can analyze video footage to automatically detect different stages of sleep, such as light sleep, deep sleep, and REM sleep. Unlike traditional sleep monitoring methods that require attaching sensors to a person's body, SleepVST uses a video camera to observe the person non-intrusively.
The key innovation is that SleepVST leverages large, pre-trained neural network models called "transformers" that have been proven effective at various visual recognition tasks. The authors show that by fine-tuning these pre-trained transformers on sleep data, they can create a highly accurate sleep staging system using just the video footage, without needing any additional sensor data.
This contactless approach could enable new applications for continuous, long-term sleep monitoring in the home or clinical settings, without the discomfort and inconvenience of wearable sensors. By providing detailed insights into a person's sleep patterns, SleepVST could help identify and manage sleep disorders, optimize sleep hygiene, and enhance overall health and wellbeing.
Technical Explanation
The SleepVST model uses a vision transformer architecture pre-trained on large image datasets, which the authors then fine-tune on several public polysomnography (PSG) datasets that include synchronized video, physiological, and sleep stage annotations. The transformer's visual encoding capabilities allow it to effectively learn sleep-relevant patterns directly from the near-infrared video frames, without needing handcrafted features or additional sensor modalities.
The authors experiment with different backbone transformer models, including ViT, Swin Transformer, and ConvNeXt, and find that the Swin Transformer provides the best performance for sleep staging. They also explore techniques like co-attention fusion and temporal modeling to integrate information across video frames and improve the model's ability to capture dynamic sleep-related behaviors.
Evaluated on multiple public datasets, including EventSleep, Transformer-based Diffusion, and State-Space Models, the SleepVST model achieves state-of-the-art performance in sleep stage classification, outperforming previous video-based approaches and even some methods that use additional physiological signals.
Critical Analysis
The paper presents a well-designed study with thorough experiments and rigorous evaluation. However, a few potential limitations and areas for future work are worth noting:
-
The performance of SleepVST is still not on par with the best methods that use a combination of video, physiological signals, and expert annotations, as seen in studies like Alzheimer's Disease Detection. Incorporating additional sensing modalities, such as audio or pressure sensors, could further improve the model's accuracy.
-
The authors do not provide much insight into the model's interpretability or explainability. Understanding the specific visual cues and sleep-related behaviors the model learns could enable better clinical interpretability and usability.
-
The paper does not address the potential privacy concerns associated with continuous, video-based sleep monitoring. Exploring techniques for Background Noise Reduction or anonymization could help address these issues.
-
The study is conducted on relatively small, curated datasets. Evaluating the model's performance on larger, more diverse and realistic home sleep monitoring scenarios would be an important next step.
Conclusion
Overall, the SleepVST model represents a promising step towards contact-free, continuous sleep monitoring using pre-trained vision transformers. By eliminating the need for wearable sensors, this approach could enable more accessible and user-friendly sleep tracking solutions, with potential applications in sleep disorder diagnosis, sleep research, and personal wellness. Further advancements in interpretability, privacy, and real-world deployments could help realize the full potential of this contactless sleep staging technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
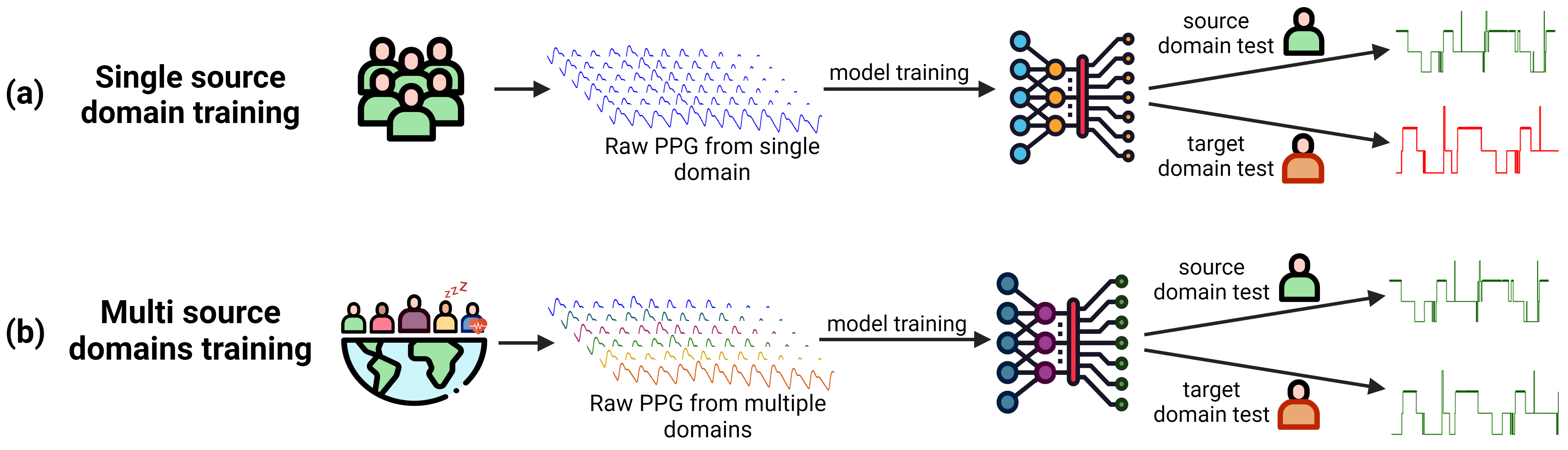
SleepPPG-Net2: Deep learning generalization for sleep staging from photoplethysmography
Shirel Attia, Revital Shani Hershkovich, Alissa Tabakhov, Angeleene Ang, Sharon Haimov, Riva Tauman, Joachim A. Behar
0
0
Background: Sleep staging is a fundamental component in the diagnosis of sleep disorders and the management of sleep health. Traditionally, this analysis is conducted in clinical settings and involves a time-consuming scoring procedure. Recent data-driven algorithms for sleep staging, using the photoplethysmogram (PPG) time series, have shown high performance on local test sets but lower performance on external datasets due to data drift. Methods: This study aimed to develop a generalizable deep learning model for the task of four class (wake, light, deep, and rapid eye movement (REM)) sleep staging from raw PPG physiological time-series. Six sleep datasets, totaling 2,574 patients recordings, were used. In order to create a more generalizable representation, we developed and evaluated a deep learning model called SleepPPG-Net2, which employs a multi-source domain training approach.SleepPPG-Net2 was benchmarked against two state-of-the-art models. Results: SleepPPG-Net2 showed consistently higher performance over benchmark approaches, with generalization performance (Cohen's kappa) improving by up to 19%. Performance disparities were observed in relation to age, sex, and sleep apnea severity. Conclusion: SleepPPG-Net2 sets a new standard for staging sleep from raw PPG time-series.
4/11/2024
🏷️
Multi-View Spectrogram Transformer for Respiratory Sound Classification
Wentao He, Yuchen Yan, Jianfeng Ren, Ruibin Bai, Xudong Jiang
0
0
Deep neural networks have been applied to audio spectrograms for respiratory sound classification. Existing models often treat the spectrogram as a synthetic image while overlooking its physical characteristics. In this paper, a Multi-View Spectrogram Transformer (MVST) is proposed to embed different views of time-frequency characteristics into the vision transformer. Specifically, the proposed MVST splits the mel-spectrogram into different sized patches, representing the multi-view acoustic elements of a respiratory sound. These patches and positional embeddings are then fed into transformer encoders to extract the attentional information among patches through a self-attention mechanism. Finally, a gated fusion scheme is designed to automatically weigh the multi-view features to highlight the best one in a specific scenario. Experimental results on the ICBHI dataset demonstrate that the proposed MVST significantly outperforms state-of-the-art methods for classifying respiratory sounds.
5/31/2024

EventSleep: Sleep Activity Recognition with Event Cameras
Carlos Plou, Nerea Gallego, Alberto Sabater, Eduardo Montijano, Pablo Urcola, Luis Montesano, Ruben Martinez-Cantin, Ana C. Murillo
0
0
Event cameras are a promising technology for activity recognition in dark environments due to their unique properties. However, real event camera datasets under low-lighting conditions are still scarce, which also limits the number of approaches to solve these kind of problems, hindering the potential of this technology in many applications. We present EventSleep, a new dataset and methodology to address this gap and study the suitability of event cameras for a very relevant medical application: sleep monitoring for sleep disorders analysis. The dataset contains synchronized event and infrared recordings emulating common movements that happen during the sleep, resulting in a new challenging and unique dataset for activity recognition in dark environments. Our novel pipeline is able to achieve high accuracy under these challenging conditions and incorporates a Bayesian approach (Laplace ensembles) to increase the robustness in the predictions, which is fundamental for medical applications. Our work is the first application of Bayesian neural networks for event cameras, the first use of Laplace ensembles in a realistic problem, and also demonstrates for the first time the potential of event cameras in a new application domain: to enhance current sleep evaluation procedures. Our activity recognition results highlight the potential of event cameras under dark conditions, and its capacity and robustness for sleep activity recognition, and open problems as the adaptation of event data pre-processing techniques to dark environments.
4/3/2024
👀
Use of a Multiscale Vision Transformer to predict Nursing Activities Score from Low Resolution Thermal Videos in an Intensive Care Unit
Isaac YL Lee, Thanh Nguyen-Duc, Ryo Ueno, Jesse Smith, Peter Y Chan
0
0
Excessive caregiver workload in hospital nurses has been implicated in poorer patient care and increased worker burnout. Measurement of this workload in the Intensive Care Unit (ICU) is often done using the Nursing Activities Score (NAS), but this is usually recorded manually and sporadically. Previous work has made use of Ambient Intelligence (AmI) by using computer vision to passively derive caregiver-patient interaction times to monitor staff workload. In this letter, we propose using a Multiscale Vision Transformer (MViT) to passively predict the NAS from low-resolution thermal videos recorded in an ICU. 458 videos were obtained from an ICU in Melbourne, Australia and used to train a MViTv2 model using an indirect prediction and a direct prediction method. The indirect method predicted 1 of 8 potentially identifiable NAS activities from the video before inferring the NAS. The direct method predicted the NAS score immediately from the video. The indirect method yielded an average 5-fold accuracy of 57.21%, an area under the receiver operating characteristic curve (ROC AUC) of 0.865, a F1 score of 0.570 and a mean squared error (MSE) of 28.16. The direct method yielded a MSE of 18.16. We also showed that the MViTv2 outperforms similar models such as R(2+1)D and ResNet50-LSTM under identical settings. This study shows the feasibility of using a MViTv2 to passively predict the NAS in an ICU and monitor staff workload automatically. Our results above also show an increased accuracy in predicting NAS directly versus predicting NAS indirectly. We hope that our study can provide a direction for future work and further improve the accuracy of passive NAS monitoring.
6/10/2024