State Space Models for Event Cameras
2402.15584
0
0
Abstract
Today, state-of-the-art deep neural networks that process event-camera data first convert a temporal window of events into dense, grid-like input representations. As such, they exhibit poor generalizability when deployed at higher inference frequencies (i.e., smaller temporal windows) than the ones they were trained on. We address this challenge by introducing state-space models (SSMs) with learnable timescale parameters to event-based vision. This design adapts to varying frequencies without the need to retrain the network at different frequencies. Additionally, we investigate two strategies to counteract aliasing effects when deploying the model at higher frequencies. We comprehensively evaluate our approach against existing methods based on RNN and Transformer architectures across various benchmarks, including Gen1 and 1 Mpx event camera datasets. Our results demonstrate that SSM-based models train 33% faster and also exhibit minimal performance degradation when tested at higher frequencies than the training input. Traditional RNN and Transformer models exhibit performance drops of more than 20 mAP, with SSMs having a drop of 3.76 mAP, highlighting the effectiveness of SSMs in event-based vision tasks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper explores the use of state space models for analyzing data from event cameras, a type of vision sensor that captures changes in pixel brightness rather than full video frames.
- The paper discusses how state space models, which represent dynamic systems using a set of internal state variables, can be applied to event camera data to enable tasks like object detection, tracking, and segmentation.
- The paper covers related work in using event cameras for computer vision, as well as the technical details of the state space model approach and experimental results on various benchmark datasets.
Plain English Explanation
State space models are a way of mathematically representing how a dynamic system changes over time. In the context of computer vision, a state space model could be used to track the movement and evolution of objects in a scene captured by a camera.
Event cameras are a special type of vision sensor that work differently from traditional cameras. Instead of capturing full video frames at regular intervals, event cameras only detect and record changes in brightness at each pixel. This can provide some advantages, like faster response times and lower power consumption, but also presents new challenges for processing the data.
This research explores how state space models can be adapted to work with the unique data format of event cameras. By modeling the scene as a set of dynamic state variables, the researchers show how event camera data can be used for tasks like object detection, tracking, and semantic segmentation. The state space approach allows the system to maintain an internal representation of the scene that can be efficiently updated as new event data arrives.
Technical Explanation
The paper begins by reviewing prior work on using event cameras for computer vision applications like object detection and semantic segmentation. It then introduces the state space modeling framework and explains how it can be applied to event camera data.
The key idea is to represent the scene as a set of dynamic state variables that evolve over time. For example, the position and velocity of an object could be modeled as state variables. As new event data is observed, the state variables are updated using a recursive filtering algorithm like a Kalman filter. This allows the model to maintain an internal representation of the scene that can be used for tasks like object tracking and segmentation.
The paper discusses several specific state space models that were explored, including constant velocity and coordinated turn models. Experiments were conducted on benchmark event camera datasets to evaluate the performance of the state space approach on tasks like object detection and tracking. The results show that the state space models can achieve competitive accuracy while being more efficient than some alternative deep learning-based methods, particularly for long-term tracking.
Critical Analysis
The paper provides a thorough technical treatment of using state space models for event camera data processing. The state space framework is well-suited to the event-based, asynchronous nature of event cameras, and the authors demonstrate its effectiveness on several computer vision benchmarks.
However, the paper does acknowledge some limitations of the state space approach. For example, the models rely on making assumptions about the dynamics of the scene, which may not always hold true in practice. Additionally, the state space formulation may struggle to capture more complex, non-linear object behaviors.
Another potential issue is the reliance on accurate calibration of the event camera. Small errors in the sensor model or camera parameters could negatively impact the performance of the state space estimator. The paper does not explore the robustness of the approach to such calibration errors.
Overall, the research presented in this paper represents an interesting and promising direction for leveraging the unique properties of event cameras. State space models provide a principled way of fusing the sparse, asynchronous event data into a coherent representation of the scene. Further work on relaxing model assumptions, improving robustness, and combining state space methods with deep learning techniques could lead to even more powerful event camera-based vision systems.
Conclusion
This research paper explores the use of state space models for processing data from event cameras, a novel type of vision sensor that captures changes in pixel brightness rather than full video frames. The state space approach allows the system to maintain an internal representation of the scene that can be efficiently updated as new event data arrives, enabling tasks like object detection, tracking, and semantic segmentation.
The paper provides a technical explanation of the state space modeling framework and its application to event camera data, as well as an evaluation of the approach on benchmark datasets. While the state space models have some limitations, the research represents an important step in leveraging the unique properties of event cameras for computer vision tasks. Further advancements in this area could lead to more efficient and robust vision systems for a variety of applications.
Related Papers
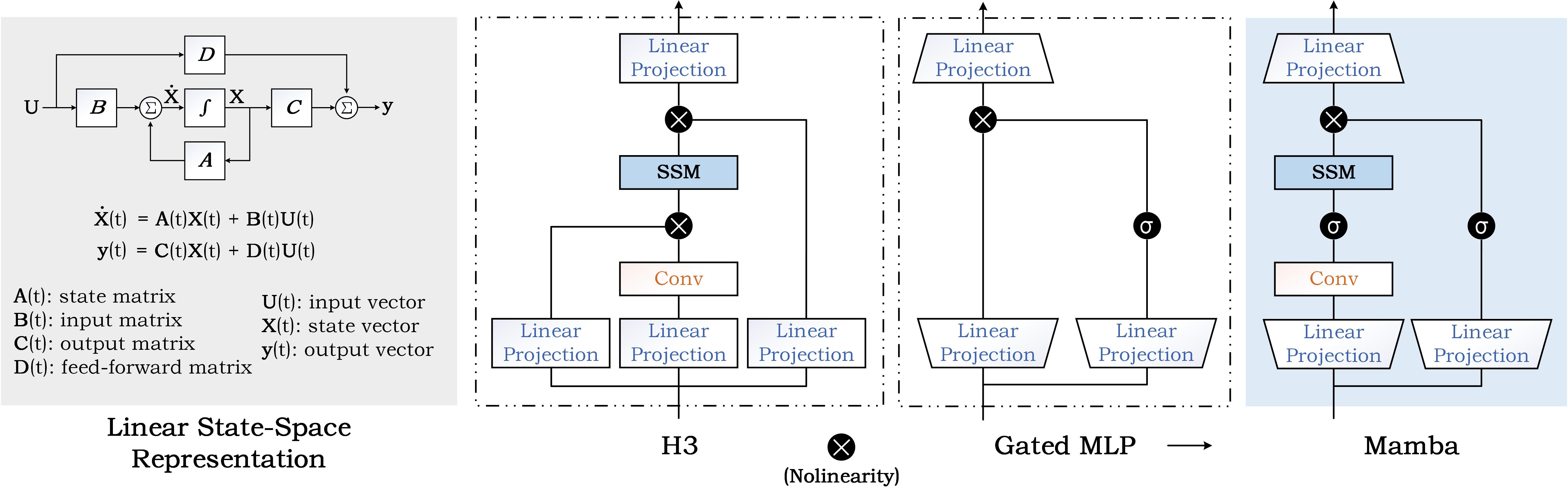
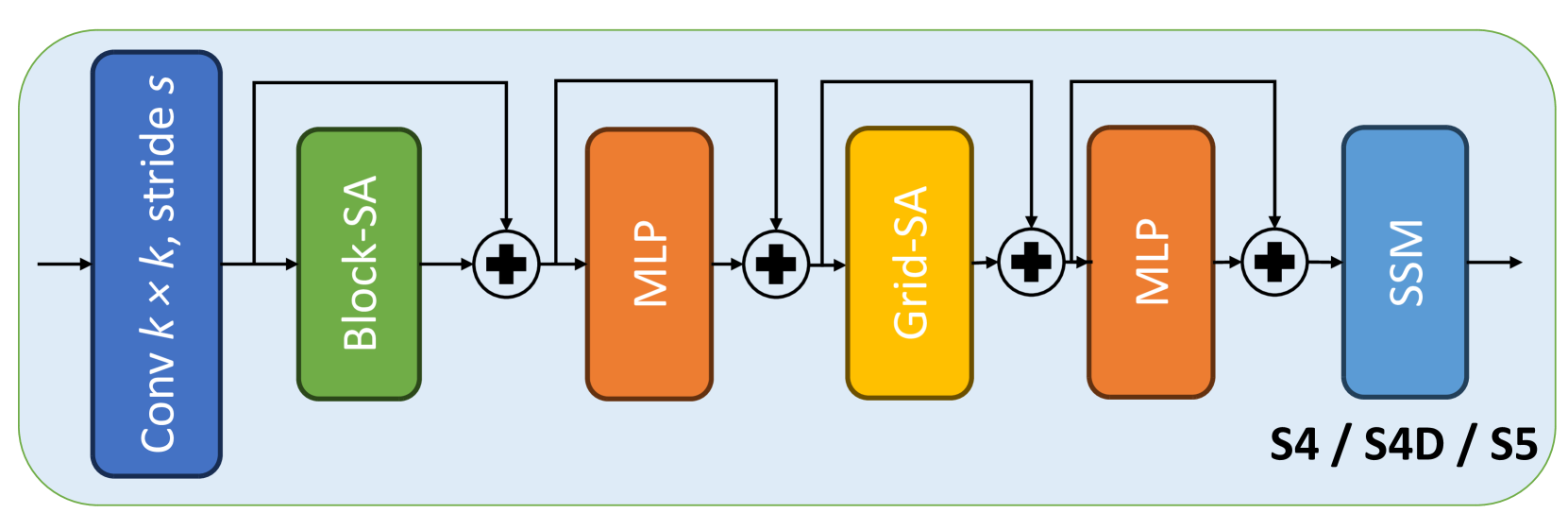
State Space Model for New-Generation Network Alternative to Transformers: A Survey
Xiao Wang, Shiao Wang, Yuhe Ding, Yuehang Li, Wentao Wu, Yao Rong, Weizhe Kong, Ju Huang, Shihao Li, Haoxiang Yang, Ziwen Wang, Bo Jiang, Chenglong Li, Yaowei Wang, Yonghong Tian, Jin Tang
0
0
In the post-deep learning era, the Transformer architecture has demonstrated its powerful performance across pre-trained big models and various downstream tasks. However, the enormous computational demands of this architecture have deterred many researchers. To further reduce the complexity of attention models, numerous efforts have been made to design more efficient methods. Among them, the State Space Model (SSM), as a possible replacement for the self-attention based Transformer model, has drawn more and more attention in recent years. In this paper, we give the first comprehensive review of these works and also provide experimental comparisons and analysis to better demonstrate the features and advantages of SSM. Specifically, we first give a detailed description of principles to help the readers quickly capture the key ideas of SSM. After that, we dive into the reviews of existing SSMs and their various applications, including natural language processing, computer vision, graph, multi-modal and multi-media, point cloud/event stream, time series data, and other domains. In addition, we give statistical comparisons and analysis of these models and hope it helps the readers to understand the effectiveness of different structures on various tasks. Then, we propose possible research points in this direction to better promote the development of the theoretical model and application of SSM. More related works will be continuously updated on the following GitHub: https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List.
4/16/2024
Scalable Event-by-event Processing of Neuromorphic Sensory Signals With Deep State-Space Models
Mark Schone, Neeraj Mohan Sushma, Jingyue Zhuge, Christian Mayr, Anand Subramoney, David Kappel
0
0
Event-based sensors are well suited for real-time processing due to their fast response times and encoding of the sensory data as successive temporal differences. These and other valuable properties, such as a high dynamic range, are suppressed when the data is converted to a frame-based format. However, most current methods either collapse events into frames or cannot scale up when processing the event data directly event-by-event. In this work, we address the key challenges of scaling up event-by-event modeling of the long event streams emitted by such sensors, which is a particularly relevant problem for neuromorphic computing. While prior methods can process up to a few thousand time steps, our model, based on modern recurrent deep state-space models, scales to event streams of millions of events for both training and inference.We leverage their stable parameterization for learning long-range dependencies, parallelizability along the sequence dimension, and their ability to integrate asynchronous events effectively to scale them up to long event streams.We further augment these with novel event-centric techniques enabling our model to match or beat the state-of-the-art performance on several event stream benchmarks. In the Spiking Speech Commands task, we improve state-of-the-art by a large margin of 6.6% to 87.1%. On the DVS128-Gestures dataset, we achieve competitive results without using frames or convolutional neural networks. Our work demonstrates, for the first time, that it is possible to use fully event-based processing with purely recurrent networks to achieve state-of-the-art task performance in several event-based benchmarks.
4/30/2024
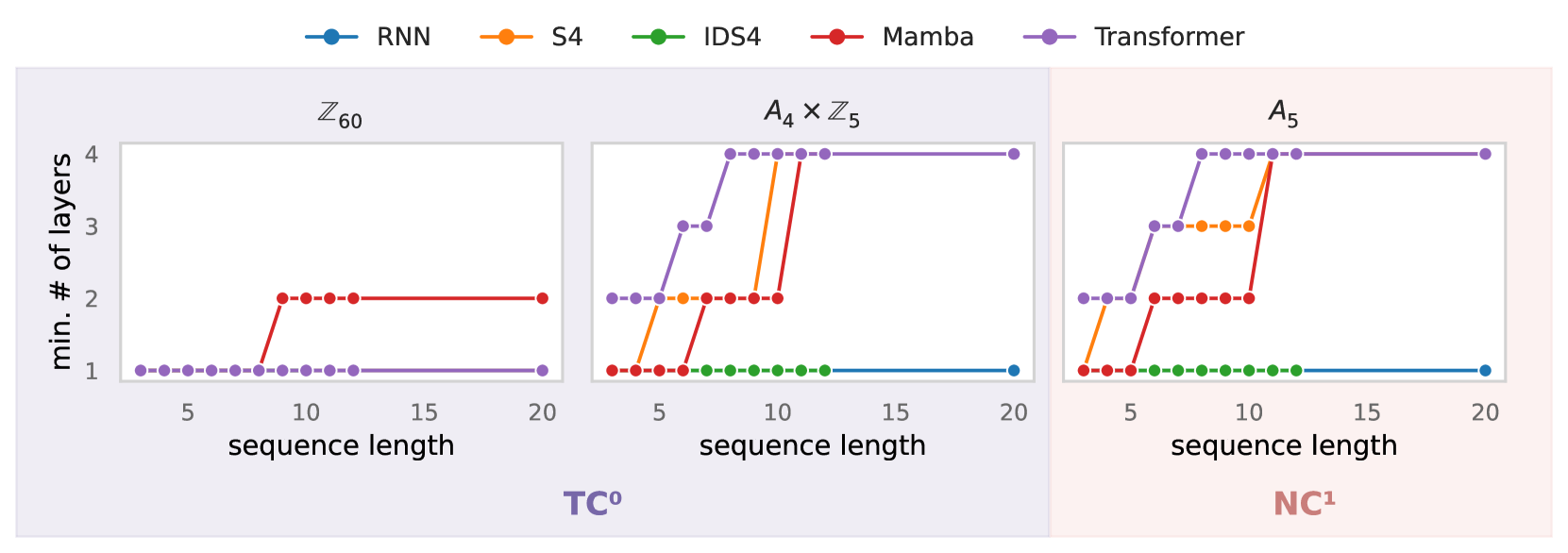
The Illusion of State in State-Space Models
William Merrill, Jackson Petty, Ashish Sabharwal
0
0
State-space models (SSMs) have emerged as a potential alternative architecture for building large language models (LLMs) compared to the previously ubiquitous transformer architecture. One theoretical weakness of transformers is that they cannot express certain kinds of sequential computation and state tracking (Merrill and Sabharwal, 2023), which SSMs are explicitly designed to address via their close architectural similarity to recurrent neural networks (RNNs). But do SSMs truly have an advantage (over transformers) in expressive power for state tracking? Surprisingly, the answer is no. Our analysis reveals that the expressive power of SSMs is limited very similarly to transformers: SSMs cannot express computation outside the complexity class $mathsf{TC}^0$. In particular, this means they cannot solve simple state-tracking problems like permutation composition. It follows that SSMs are provably unable to accurately track chess moves with certain notation, evaluate code, or track entities in a long narrative. To supplement our formal analysis, we report experiments showing that Mamba-style SSMs indeed struggle with state tracking. Thus, despite its recurrent formulation, the state in an SSM is an illusion: SSMs have similar expressiveness limitations to non-recurrent models like transformers, which may fundamentally limit their ability to solve real-world state-tracking problems.
4/16/2024
🤿
Mamba-360: Survey of State Space Models as Transformer Alternative for Long Sequence Modelling: Methods, Applications, and Challenges
Badri Narayana Patro, Vijay Srinivas Agneeswaran
0
0
Sequence modeling is a crucial area across various domains, including Natural Language Processing (NLP), speech recognition, time series forecasting, music generation, and bioinformatics. Recurrent Neural Networks (RNNs) and Long Short Term Memory Networks (LSTMs) have historically dominated sequence modeling tasks like Machine Translation, Named Entity Recognition (NER), etc. However, the advancement of transformers has led to a shift in this paradigm, given their superior performance. Yet, transformers suffer from $O(N^2)$ attention complexity and challenges in handling inductive bias. Several variations have been proposed to address these issues which use spectral networks or convolutions and have performed well on a range of tasks. However, they still have difficulty in dealing with long sequences. State Space Models(SSMs) have emerged as promising alternatives for sequence modeling paradigms in this context, especially with the advent of S4 and its variants, such as S4nd, Hippo, Hyena, Diagnol State Spaces (DSS), Gated State Spaces (GSS), Linear Recurrent Unit (LRU), Liquid-S4, Mamba, etc. In this survey, we categorize the foundational SSMs based on three paradigms namely, Gating architectures, Structural architectures, and Recurrent architectures. This survey also highlights diverse applications of SSMs across domains such as vision, video, audio, speech, language (especially long sequence modeling), medical (including genomics), chemical (like drug design), recommendation systems, and time series analysis, including tabular data. Moreover, we consolidate the performance of SSMs on benchmark datasets like Long Range Arena (LRA), WikiText, Glue, Pile, ImageNet, Kinetics-400, sstv2, as well as video datasets such as Breakfast, COIN, LVU, and various time series datasets. The project page for Mamba-360 work is available on this webpage.url{https://github.com/badripatro/mamba360}.
4/26/2024