SLMRec: Empowering Small Language Models for Sequential Recommendation
2405.17890
0
0

Abstract
The sequential Recommendation (SR) task involves predicting the next item a user is likely to interact with, given their past interactions. The SR models examine the sequence of a user's actions to discern more complex behavioral patterns and temporal dynamics. Recent research demonstrates the great impact of LLMs on sequential recommendation systems, either viewing sequential recommendation as language modeling or serving as the backbone for user representation. Although these methods deliver outstanding performance, there is scant evidence of the necessity of a large language model and how large the language model is needed, especially in the sequential recommendation scene. Meanwhile, due to the huge size of LLMs, it is inefficient and impractical to apply a LLM-based model in real-world platforms that often need to process billions of traffic logs daily. In this paper, we explore the influence of LLMs' depth by conducting extensive experiments on large-scale industry datasets. Surprisingly, we discover that most intermediate layers of LLMs are redundant. Motivated by this insight, we empower small language models for SR, namely SLMRec, which adopt a simple yet effective knowledge distillation method. Moreover, SLMRec is orthogonal to other post-training efficiency techniques, such as quantization and pruning, so that they can be leveraged in combination. Comprehensive experimental results illustrate that the proposed SLMRec model attains the best performance using only 13% of the parameters found in LLM-based recommendation models, while simultaneously achieving up to 6.6x and 8.0x speedups in training and inference time costs, respectively.
Create account to get full access
Overview
- This paper introduces SLMRec, a method to empower small language models (SLMs) for sequential recommendation tasks.
- SLMs are more efficient and deployable than large language models (LLMs), but typically underperform LLMs on complex tasks like sequential recommendation.
- The key idea of SLMRec is to leverage the strengths of SLMs and LLMs in a complementary way to achieve strong recommendation performance.
Plain English Explanation
The paper focuses on a problem in the field of recommender systems - how to make effective recommendations to users based on their past interactions. The researchers recognized that while large language models (LLMs) can perform well on this task, they are often computationally expensive and difficult to deploy.
In contrast, small language models (SLMs) are more efficient and practical, but tend to underperform LLMs on complex tasks like sequential recommendation, where the model needs to understand the user's interests over time.
The key innovation in this paper is a method called SLMRec that allows SLMs to leverage the strengths of LLMs in a complementary way. This helps SLMs achieve strong recommendation performance while maintaining their efficiency and deployability.
Technical Explanation
The researchers propose the SLMRec framework, which consists of two main components:
-
SLM-based Sequential Recommendation: An SLM is used as the base model for sequential recommendation. The SLM is fine-tuned on the recommendation task using a contrastive learning objective that improves its temporal awareness.
-
LLM-guided Knowledge Distillation: The knowledge and capabilities of a larger, more powerful LLM are distilled into the SLM through a contrastive alignment process. This helps the SLM make more accurate recommendations by leveraging the LLM's broader understanding.
The experiments show that SLMRec outperforms both standalone SLMs and LLMs on several sequential recommendation benchmarks, while maintaining the efficiency and deployability advantages of SLMs.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the SLMRec approach, including comparisons to state-of-the-art methods and ablation studies. However, the authors acknowledge some limitations:
- The performance gains of SLMRec may diminish as LLM sizes and capabilities continue to improve, potentially reducing the relative advantage of the proposed approach.
- The knowledge distillation process relies on the availability of a suitable LLM, which may not always be the case, especially for domain-specific applications.
Additionally, the paper does not explore the potential fairness or bias implications of leveraging large, pre-trained language models in recommendation systems. Further research in this area would be valuable.
Conclusion
This paper presents a novel approach, SLMRec, that empowers small language models to achieve strong performance on sequential recommendation tasks. By leveraging the complementary strengths of SLMs and LLMs, SLMRec offers an efficient and practical solution for real-world recommendation systems.
The insights from this work could inform the development of more robust and accessible recommender systems, with potential applications in e-commerce, content platforms, and personalized services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models Enhanced Sequential Recommendation for Long-tail User and Item
Qidong Liu, Xian Wu, Xiangyu Zhao, Yejing Wang, Zijian Zhang, Feng Tian, Yefeng Zheng
0
0
Sequential recommendation systems (SRS) serve the purpose of predicting users' subsequent preferences based on their past interactions and have been applied across various domains such as e-commerce and social networking platforms. However, practical SRS encounters challenges due to the fact that most users engage with only a limited number of items, while the majority of items are seldom consumed. These challenges, termed as the long-tail user and long-tail item dilemmas, often create obstacles for traditional SRS methods. Mitigating these challenges is crucial as they can significantly impact user satisfaction and business profitability. While some research endeavors have alleviated these issues, they still grapple with issues such as seesaw or noise stemming from the scarcity of interactions. The emergence of large language models (LLMs) presents a promising avenue to address these challenges from a semantic standpoint. In this study, we introduce the Large Language Models Enhancement framework for Sequential Recommendation (LLM-ESR), which leverages semantic embeddings from LLMs to enhance SRS performance without increasing computational overhead. To combat the long-tail item challenge, we propose a dual-view modeling approach that fuses semantic information from LLMs with collaborative signals from traditional SRS. To address the long-tail user challenge, we introduce a retrieval augmented self-distillation technique to refine user preference representations by incorporating richer interaction data from similar users. Through comprehensive experiments conducted on three authentic datasets using three widely used SRS models, our proposed enhancement framework demonstrates superior performance compared to existing methodologies.
6/3/2024
The Elephant in the Room: Rethinking the Usage of Pre-trained Language Model in Sequential Recommendation
Zekai Qu, Ruobing Xie, Chaojun Xiao, Xingwu Sun, Zhanhui Kang
0
0
Sequential recommendation (SR) has seen significant advancements with the help of Pre-trained Language Models (PLMs). Some PLM-based SR models directly use PLM to encode user historical behavior's text sequences to learn user representations, while there is seldom an in-depth exploration of the capability and suitability of PLM in behavior sequence modeling. In this work, we first conduct extensive model analyses between PLMs and PLM-based SR models, discovering great underutilization and parameter redundancy of PLMs in behavior sequence modeling. Inspired by this, we explore different lightweight usages of PLMs in SR, aiming to maximally stimulate the ability of PLMs for SR while satisfying the efficiency and usability demands of practical systems. We discover that adopting behavior-tuned PLMs for item initializations of conventional ID-based SR models is the most economical framework of PLM-based SR, which would not bring in any additional inference cost but could achieve a dramatic performance boost compared with the original version. Extensive experiments on five datasets show that our simple and universal framework leads to significant improvement compared to classical SR and SOTA PLM-based SR models without additional inference costs.
4/16/2024

DELRec: Distilling Sequential Pattern to Enhance LLM-based Recommendation
Guohao Sun, Haoyi Zhang
0
0
Sequential recommendation (SR) tasks enhance recommendation accuracy by capturing the connection between users' past interactions and their changing preferences. Conventional models often focus solely on capturing sequential patterns within the training data, neglecting the broader context and semantic information embedded in item titles from external sources. This limits their predictive power and adaptability. Recently, large language models (LLMs) have shown promise in SR tasks due to their advanced understanding capabilities and strong generalization abilities. Researchers have attempted to enhance LLMs' recommendation performance by incorporating information from SR models. However, previous approaches have encountered problems such as 1) only influencing LLMs at the result level; 2) increased complexity of LLMs recommendation methods leading to reduced interpretability; 3) incomplete understanding and utilization of SR models information by LLMs. To address these problems, we proposes a novel framework, DELRec, which aims to extract knowledge from SR models and enable LLMs to easily comprehend and utilize this supplementary information for more effective sequential recommendations. DELRec consists of two main stages: 1) SR Models Pattern Distilling, focusing on extracting behavioral patterns exhibited by SR models using soft prompts through two well-designed strategies; 2) LLMs-based Sequential Recommendation, aiming to fine-tune LLMs to effectively use the distilled auxiliary information to perform SR tasks. Extensive experimental results conducted on three real datasets validate the effectiveness of the DELRec framework.
6/19/2024
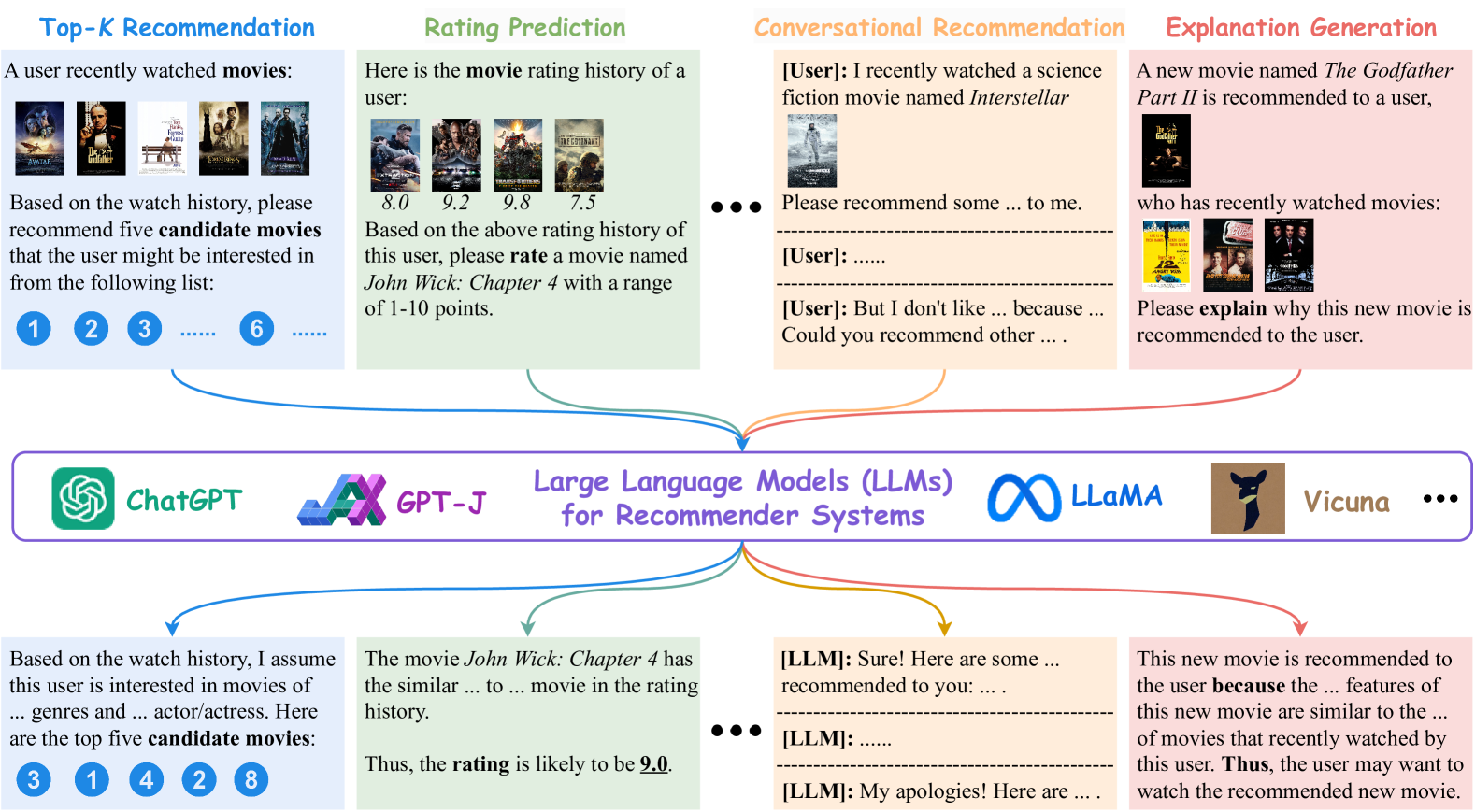
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
0
0
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
4/23/2024