SmurfCat at SemEval-2024 Task 6: Leveraging Synthetic Data for Hallucination Detection
2404.06137
0
0
Abstract
In this paper, we present our novel systems developed for the SemEval-2024 hallucination detection task. Our investigation spans a range of strategies to compare model predictions with reference standards, encompassing diverse baselines, the refinement of pre-trained encoders through supervised learning, and an ensemble approaches utilizing several high-performing models. Through these explorations, we introduce three distinct methods that exhibit strong performance metrics. To amplify our training data, we generate additional training samples from unlabelled training subset. Furthermore, we provide a detailed comparative analysis of our approaches. Notably, our premier method achieved a commendable 9th place in the competition's model-agnostic track and 17th place in model-aware track, highlighting its effectiveness and potential.
Create account to get full access
Overview
- This paper describes the approach taken by the "SmurfCat" team for the SemEval-2024 Task 6: Hallucination Detection.
- The team leveraged synthetic data to improve their model's ability to detect hallucinations in text summaries.
- Hallucinations are factual inconsistencies or fabricated content that can arise in language models.
Plain English Explanation
The researchers from the "SmurfCat" team participated in a competition to develop models that can identify hallucinations in text summaries. Hallucinations are cases where the summary includes information that is not actually present in the original text. This can be a problem for applications like automated summarization, where the model might generate fake or inconsistent information.
To address this, the SmurfCat team used synthetic data to train their model. Synthetic data refers to artificially generated text that mimics real-world examples. By including synthetic hallucinated samples in their training data, the team aimed to help their model better recognize and flag hallucinations when it encounters them.
The core idea is that exposing the model to a wider range of possible hallucinations during training will make it more adept at spotting them in the real world. This approach builds on prior work that has explored leveraging synthetic data for hallucination detection.
Technical Explanation
The SmurfCat team participated in the SemEval-2024 Task 6: Hallucination Detection, where the goal was to develop models that can identify hallucinations in text summaries. Hallucinations are factual inconsistencies or fabricated content that can arise in language models.
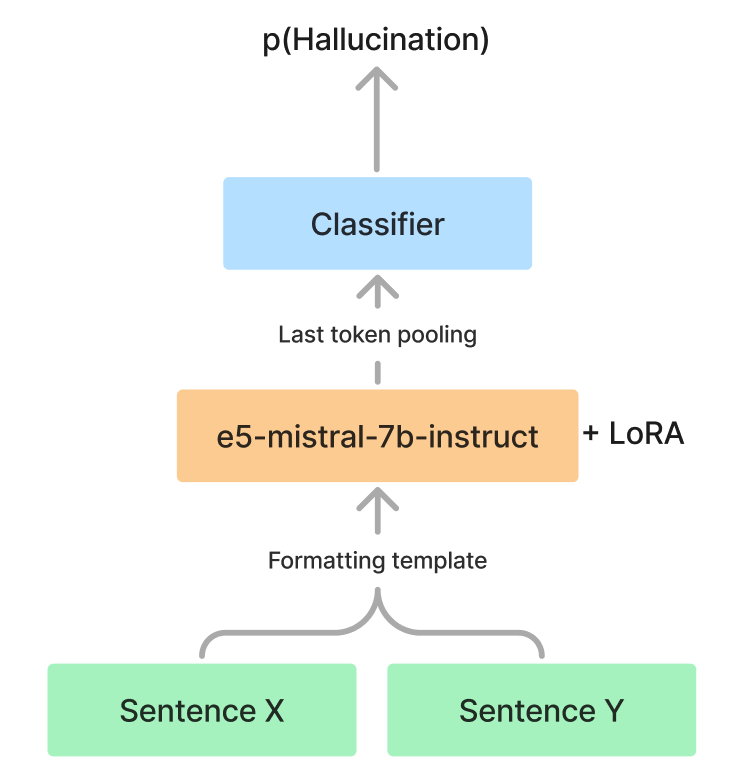
To improve their model's hallucination detection capabilities, the SmurfCat team leveraged synthetic data. They generated additional training samples that contained hallucinated content, mixing them with the real-world examples provided in the task dataset. This allowed the model to learn more robust patterns for distinguishing genuine information from fabricated content.
The team's approach builds on prior work that has explored using synthetic data to enhance summarization models and make them less prone to generating hallucinations. By exposing the model to a wider range of possible hallucinations during training, the researchers aimed to improve its ability to detect such issues in the real-world summaries it encounters.
Critical Analysis
The SmurfCat team's approach of leveraging synthetic data is a promising direction for improving hallucination detection in text summarization models. By augmenting the training data with artificially generated hallucinated samples, the model can learn more robust patterns for identifying fabricated or inconsistent information.
However, the paper does not provide details on the specific synthetic data generation techniques used or the evaluation of their effectiveness. It would be valuable to understand how the synthetic samples were created, the criteria used to ensure their realism and diversity, and the impact they had on the model's performance.
Additionally, the paper does not address potential limitations or caveats of this approach. For example, it's unclear how the model would generalize to hallucinations that differ significantly from the synthetic samples used during training. There may also be concerns about the model overfitting to the synthetic data or developing biases towards certain types of hallucinations.
Further research and experimentation would be needed to fully assess the strengths, weaknesses, and broader applicability of the SmurfCat team's approach. Incorporating feedback from the hallucinations leaderboard and engaging with the wider research community could help refine and validate this technique for real-world deployment.
Conclusion
The SmurfCat team's work at the SemEval-2024 Task 6 demonstrates the potential of leveraging synthetic data to improve hallucination detection in text summarization models. By augmenting the training data with artificially generated hallucinated samples, the team aimed to equip their model with a more comprehensive understanding of the patterns and characteristics of fabricated content.
This approach builds on previous research exploring the use of synthetic data to enhance summarization models and make them less prone to hallucinations. If further developed and validated, techniques like the one used by the SmurfCat team could contribute to the ongoing efforts to improve the reliability and trustworthiness of language models in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SLPL SHROOM at SemEval-2024 Task 06: A comprehensive study on models ability to detect hallucination
Pouya Fallah, Soroush Gooran, Mohammad Jafarinasab, Pouya Sadeghi, Reza Farnia, Amirreza Tarabkhah, Zainab Sadat Taghavi, Hossein Sameti
0
0
Language models, particularly generative models, are susceptible to hallucinations, generating outputs that contradict factual knowledge or the source text. This study explores methods for detecting hallucinations in three SemEval-2024 Task 6 tasks: Machine Translation, Definition Modeling, and Paraphrase Generation. We evaluate two methods: semantic similarity between the generated text and factual references, and an ensemble of language models that judge each other's outputs. Our results show that semantic similarity achieves moderate accuracy and correlation scores in trial data, while the ensemble method offers insights into the complexities of hallucination detection but falls short of expectations. This work highlights the challenges of hallucination detection and underscores the need for further research in this critical area.
4/10/2024

AILS-NTUA at SemEval-2024 Task 6: Efficient model tuning for hallucination detection and analysis
Natalia Grigoriadou, Maria Lymperaiou, Giorgos Filandrianos, Giorgos Stamou
0
0
In this paper, we present our team's submissions for SemEval-2024 Task-6 - SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes. The participants were asked to perform binary classification to identify cases of fluent overgeneration hallucinations. Our experimentation included fine-tuning a pre-trained model on hallucination detection and a Natural Language Inference (NLI) model. The most successful strategy involved creating an ensemble of these models, resulting in accuracy rates of 77.8% and 79.9% on model-agnostic and model-aware datasets respectively, outperforming the organizers' baseline and achieving notable results when contrasted with the top-performing results in the competition, which reported accuracies of 84.7% and 81.3% correspondingly.
4/15/2024

SHROOM-INDElab at SemEval-2024 Task 6: Zero- and Few-Shot LLM-Based Classification for Hallucination Detection
Bradley P. Allen, Fina Polat, Paul Groth
0
0
We describe the University of Amsterdam Intelligent Data Engineering Lab team's entry for the SemEval-2024 Task 6 competition. The SHROOM-INDElab system builds on previous work on using prompt programming and in-context learning with large language models (LLMs) to build classifiers for hallucination detection, and extends that work through the incorporation of context-specific definition of task, role, and target concept, and automated generation of examples for use in a few-shot prompting approach. The resulting system achieved fourth-best and sixth-best performance in the model-agnostic track and model-aware tracks for Task 6, respectively, and evaluation using the validation sets showed that the system's classification decisions were consistent with those of the crowd-sourced human labellers. We further found that a zero-shot approach provided better accuracy than a few-shot approach using automatically generated examples. Code for the system described in this paper is available on Github.
4/8/2024

Exploiting Semantic Reconstruction to Mitigate Hallucinations in Vision-Language Models
Minchan Kim, Minyeong Kim, Junik Bae, Suhwan Choi, Sungkyung Kim, Buru Chang
0
0
Hallucinations in vision-language models pose a significant challenge to their reliability, particularly in the generation of long captions. Current methods fall short of accurately identifying and mitigating these hallucinations. To address this issue, we introduce ESREAL, a novel unsupervised learning framework designed to suppress the generation of hallucinations through accurate localization and penalization of hallucinated tokens. Initially, ESREAL creates a reconstructed image based on the generated caption and aligns its corresponding regions with those of the original image. This semantic reconstruction aids in identifying both the presence and type of token-level hallucinations within the generated caption. Subsequently, ESREAL computes token-level hallucination scores by assessing the semantic similarity of aligned regions based on the type of hallucination. Finally, ESREAL employs a proximal policy optimization algorithm, where it selectively penalizes hallucinated tokens according to their token-level hallucination scores. Our framework notably reduces hallucinations in LLaVA, InstructBLIP, and mPLUG-Owl2 by 32.81%, 27.08%, and 7.46% on the CHAIR metric. This improvement is achieved solely through signals derived from the image itself, without the need for any image-text pairs.
5/7/2024