SLVideo: A Sign Language Video Moment Retrieval Framework

0

Sign in to get full access
Overview
- SLVideo is a framework for retrieving sign language video moments from a video library.
- It allows users to find relevant sign language video clips based on natural language queries.
- The framework includes tools for annotating sign language videos and indexing them for efficient retrieval.
Plain English Explanation
SLVideo: A Sign Language Video Moment Retrieval Framework is a system that helps people find specific sign language video clips from a larger collection of videos. Imagine you're trying to find a video showing how to sign a particular word or phrase in sign language. With SLVideo, you could search for that word or phrase using normal language, and the system would show you the relevant video clip(s) from its library.
The key components of SLVideo include tools for annotating the sign language videos with information about what's happening in each clip. This allows the system to understand the content of the videos and match them to users' search queries. SLVideo also has an indexing system that efficiently stores and retrieves the video clips based on the annotations.
Overall, SLVideo aims to make it easier for people who use sign language to find relevant video examples, which could be helpful for language learning, research, or other applications.
Technical Explanation
The SLVideo framework consists of several key components. First, it includes tools for annotating sign language videos with information about the content, such as the signs being performed, the context, and any other relevant details. This annotation data is then used to index the video clips in a way that allows for efficient retrieval based on natural language queries.
The indexing system in SLVideo uses a combination of techniques, including text-based indexing of the annotations and visual similarity-based indexing of the video content. This allows the system to quickly identify relevant video clips that match a user's query, even if the query doesn't exactly match the annotation text.
The experiment section of the paper describes how the researchers evaluated the performance of SLVideo on a dataset of sign language videos. They measured the system's ability to accurately retrieve relevant video clips based on different types of queries, and found that it outperformed baseline methods.
Critical Analysis
The paper provides a thorough description of the SLVideo framework and its key components. However, it does not address some potential limitations or areas for further research.
For example, the annotation process relies on human annotators, which could be time-consuming and potentially introduce inconsistencies. Exploring ways to automate or semi-automate the annotation process could improve the scalability of the system.
Additionally, the evaluation focuses on retrieval performance, but does not consider other important factors, such as the usability of the system for end-users or the long-term sustainability of the video library. Incorporating user feedback and studying the system's real-world deployment could provide valuable insights.
Conclusion
SLVideo: A Sign Language Video Moment Retrieval Framework presents a promising approach for improving access to sign language video resources. By providing tools for annotating and indexing sign language videos, the system allows users to easily find relevant video clips based on natural language queries.
While the paper demonstrates the technical capabilities of SLVideo, there are opportunities to further enhance the system, such as by exploring ways to streamline the annotation process and gather feedback from end-users. Addressing these areas could help make SLVideo an even more valuable tool for the sign language community and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SLVideo: A Sign Language Video Moment Retrieval Framework
Gonc{c}alo Vinagre Martins, Afonso Quinaz, Carla Viegas, Sofia Cavaco, Jo~ao Magalh~aes
Sign Language Recognition has been studied and developed throughout the years to help the deaf and hard-of-hearing people in their day-to-day lives. These technologies leverage manual sign recognition algorithms, however, most of them lack the recognition of facial expressions, which are also an essential part of Sign Language as they allow the speaker to add expressiveness to their dialogue or even change the meaning of certain manual signs. SLVideo is a video moment retrieval software for Sign Language videos with a focus on both hands and facial signs. The system extracts embedding representations for the hand and face signs from video frames to capture the language signs in full. This will then allow the user to search for a specific sign language video segment with text queries, or to search by similar sign language videos. To test this system, a collection of five hours of annotated Sign Language videos is used as the dataset, and the initial results are promising in a zero-shot setting.SLVideo is shown to not only address the problem of searching sign language videos but also supports a Sign Language thesaurus with a search by similarity technique. Project web page: https://novasearch.github.io/SLVideo/
Read more7/23/2024

0
EvSign: Sign Language Recognition and Translation with Streaming Events
Pengyu Zhang, Hao Yin, Zeren Wang, Wenyue Chen, Shengming Li, Dong Wang, Huchuan Lu, Xu Jia
Sign language is one of the most effective communication tools for people with hearing difficulties. Most existing works focus on improving the performance of sign language tasks on RGB videos, which may suffer from degraded recording conditions, such as fast movement of hands with motion blur and textured signer's appearance. The bio-inspired event camera, which asynchronously captures brightness change with high speed, could naturally perceive dynamic hand movements, providing rich manual clues for sign language tasks. In this work, we aim at exploring the potential of event camera in continuous sign language recognition (CSLR) and sign language translation (SLT). To promote the research, we first collect an event-based benchmark EvSign for those tasks with both gloss and spoken language annotations. EvSign dataset offers a substantial amount of high-quality event streams and an extensive vocabulary of glosses and words, thereby facilitating the development of sign language tasks. In addition, we propose an efficient transformer-based framework for event-based SLR and SLT tasks, which fully leverages the advantages of streaming events. The sparse backbone is employed to extract visual features from sparse events. Then, the temporal coherence is effectively utilized through the proposed local token fusion and gloss-aware temporal aggregation modules. Extensive experimental results are reported on both simulated (PHOENIX14T) and EvSign datasets. Our method performs favorably against existing state-of-the-art approaches with only 0.34% computational cost (0.84G FLOPS per video) and 44.2% network parameters. The project is available at https://zhang-pengyu.github.io/EVSign.
Read more7/23/2024
🖼️
0
New Capability to Look Up an ASL Sign from a Video Example
Carol Neidle, Augustine Opoku, Carey Ballard, Yang Zhou, Xiaoxiao He, Gregory Dimitriadis, Dimitris Metaxas
Looking up an unknown sign in an ASL dictionary can be difficult. Most ASL dictionaries are organized based on English glosses, despite the fact that (1) there is no convention for assigning English-based glosses to ASL signs; and (2) there is no 1-1 correspondence between ASL signs and English words. Furthermore, what if the user does not know either the meaning of the target sign or its possible English translation(s)? Some ASL dictionaries enable searching through specification of articulatory properties, such as handshapes, locations, movement properties, etc. However, this is a cumbersome process and does not always result in successful lookup. Here we describe a new system, publicly shared on the Web, to enable lookup of a video of an ASL sign (e.g., a webcam recording or a clip from a continuous signing video). The user submits a video for analysis and is presented with the five most likely sign matches, in decreasing order of likelihood, so that the user can confirm the selection and then be taken to our ASLLRP Sign Bank entry for that sign. Furthermore, this video lookup is also integrated into our newest version of SignStream(R) software to facilitate linguistic annotation of ASL video data, enabling the user to directly look up a sign in the video being annotated, and, upon confirmation of the match, to directly enter into the annotation the gloss and features of that sign, greatly increasing the efficiency and consistency of linguistic annotations of ASL video data.
Read more7/19/2024
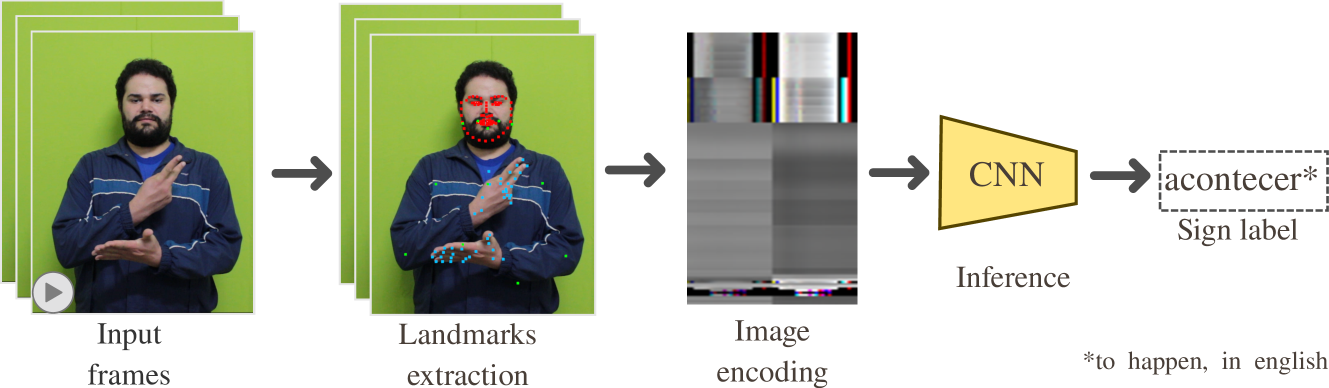
0
Enhancing Brazilian Sign Language Recognition through Skeleton Image Representation
Carlos Eduardo G. R. Alves, Francisco de Assis Boldt, Thiago M. Paix~ao
Effective communication is paramount for the inclusion of deaf individuals in society. However, persistent communication barriers due to limited Sign Language (SL) knowledge hinder their full participation. In this context, Sign Language Recognition (SLR) systems have been developed to improve communication between signing and non-signing individuals. In particular, there is the problem of recognizing isolated signs (Isolated Sign Language Recognition, ISLR) of great relevance in the development of vision-based SL search engines, learning tools, and translation systems. This work proposes an ISLR approach where body, hands, and facial landmarks are extracted throughout time and encoded as 2-D images. These images are processed by a convolutional neural network, which maps the visual-temporal information into a sign label. Experimental results demonstrate that our method surpassed the state-of-the-art in terms of performance metrics on two widely recognized datasets in Brazilian Sign Language (LIBRAS), the primary focus of this study. In addition to being more accurate, our method is more time-efficient and easier to train due to its reliance on a simpler network architecture and solely RGB data as input.
Read more5/1/2024