Small noise analysis for Tikhonov and RKHS regularizations

0
🚀
Sign in to get full access
Overview
- Regularization is crucial for addressing ill-posed machine learning and inverse problems.
- The paper aims to analyze the comparative effects of different regularization norms in the context of ill-posed linear inverse problems with Gaussian noise.
- The authors propose a framework to study the convergence rates of regularized estimators in the small noise limit, revealing potential instability of the conventional L2-regularizer.
- To address this issue, the authors introduce a new class of adaptive fractional RKHS regularizers that cover L2 Tikhonov and RKHS regularizations.
Plain English Explanation
In machine learning and data analysis, there are often problems that are inherently difficult to solve, known as ill-posed problems. These problems lack a clear or unique solution, making them challenging to work with. Regularization is a technique used to address these ill-posed problems by adding additional constraints or information to the problem, guiding the solution towards a more stable and meaningful result.
The paper focuses on comparing the effects of different types of regularization norms, which are the specific mathematical forms used to introduce the additional constraints. The authors develop a framework to analyze how these different norms behave in the context of ill-posed linear inverse problems with Gaussian noise.
The key finding is that the conventional L2-regularizer, which is a commonly used approach, can be potentially unstable in certain situations. To address this, the authors propose a new class of adaptive fractional RKHS regularizers, which can provide better stability and convergence properties. These new regularizers cover the L2 Tikhonov and RKHS regularizations by adjusting a parameter that controls the smoothness of the solution.
Interestingly, the authors discover that over-smoothing using these fractional RKHS regularizers can consistently yield optimal convergence rates, but the optimal hyperparameter (a parameter that needs to be tuned) may decay too quickly to be easily selected in practice.
Technical Explanation
The paper establishes a small noise analysis framework to assess the effects of different regularization norms in the context of ill-posed linear inverse problems with Gaussian noise. This framework studies the convergence rates of regularized estimators in the small noise limit, revealing the potential instability of the conventional L2-regularizer.
To address this issue, the authors propose an innovative class of adaptive fractional RKHS (Reproducing Kernel Hilbert Space) regularizers. These regularizers cover the L2 Tikhonov and RKHS regularizations by adjusting a fractional smoothness parameter. A surprising finding is that over-smoothing via these fractional RKHSs consistently yields optimal convergence rates, but the optimal hyperparameter may decay too rapidly to be selected in practice.
The authors conduct a comparative analysis of various regularization norms, including the L2-regularizer and the proposed fractional RKHS regularizers. They derive theoretical guarantees on the convergence rates of the regularized estimators in the small noise limit, highlighting the advantages and limitations of the different approaches.
Critical Analysis
The paper provides a thorough theoretical analysis of the comparative effects of various regularization norms in the context of ill-posed linear inverse problems. The proposed framework for small noise analysis and the introduction of the adaptive fractional RKHS regularizers are significant contributions to the field.
One potential limitation of the research is the focus on linear inverse problems with Gaussian noise. While this setting is a common and important one, it may not capture the full complexity of real-world machine learning and inverse problems, which often involve nonlinear relationships and non-Gaussian noise.
Additionally, the finding that the optimal hyperparameter for the fractional RKHS regularizers may decay too quickly to be selected in practice could be a practical challenge. Further research may be needed to explore more robust hyperparameter tuning methods or alternative regularization approaches that are less sensitive to hyperparameter selection.
It would also be valuable to see empirical evaluations of the proposed fractional RKHS regularizers on a wider range of real-world applications, to assess their practical performance and identify any potential limitations or edge cases.
Conclusion
This paper makes important contributions to the understanding of regularization in ill-posed machine learning and inverse problems. The authors' small noise analysis framework and the introduction of adaptive fractional RKHS regularizers provide valuable insights into the comparative effects of different regularization norms.
The discovery that over-smoothing via fractional RKHSs can yield optimal convergence rates is a surprising and notable finding, although the practical challenges of hyperparameter selection may limit their immediate applicability. Overall, the research advances the theoretical foundations of regularization and opens up new avenues for further exploration in this critical area of machine learning and data analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
Small noise analysis for Tikhonov and RKHS regularizations
Quanjun Lang, Fei Lu
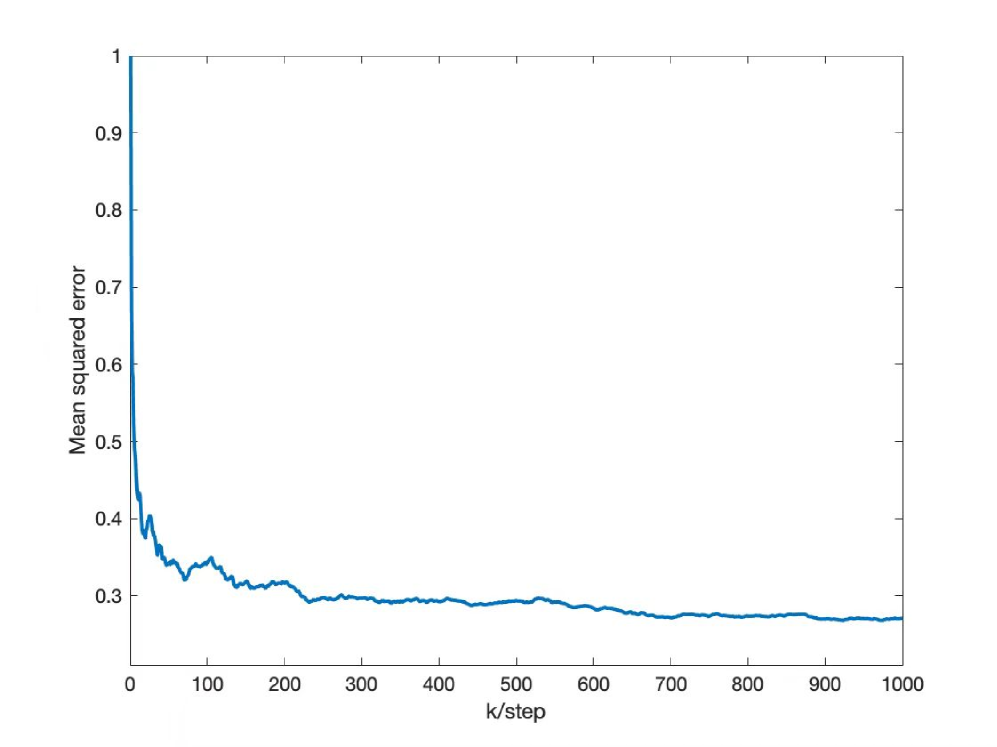
Regularization plays a pivotal role in ill-posed machine learning and inverse problems. However, the fundamental comparative analysis of various regularization norms remains open. We establish a small noise analysis framework to assess the effects of norms in Tikhonov and RKHS regularizations, in the context of ill-posed linear inverse problems with Gaussian noise. This framework studies the convergence rates of regularized estimators in the small noise limit and reveals the potential instability of the conventional L2-regularizer. We solve such instability by proposing an innovative class of adaptive fractional RKHS regularizers, which covers the L2 Tikhonov and RKHS regularizations by adjusting the fractional smoothness parameter. A surprising insight is that over-smoothing via these fractional RKHSs consistently yields optimal convergence rates, but the optimal hyper-parameter may decay too fast to be selected in practice.
Read more9/5/2024
0
Convergence Conditions of Online Regularized Statistical Learning in Reproducing Kernel Hilbert Space With Non-Stationary Data
Xiwei Zhang, Tao Li
We study the convergence of recursive regularized learning algorithms in the reproducing kernel Hilbert space (RKHS) with dependent and non-stationary online data streams. Firstly, we study the mean square asymptotic stability of a class of random difference equations in RKHS, whose non-homogeneous terms are martingale difference sequences dependent on the homogeneous ones. Secondly, we introduce the concept of random Tikhonov regularization path, and show that if the regularization path is slowly time-varying in some sense, then the output of the algorithm is consistent with the regularization path in mean square. Furthermore, if the data streams also satisfy the RKHS persistence of excitation condition, i.e. there exists a fixed length of time period, such that the conditional expectation of the operators induced by the input data accumulated over every time period has a uniformly strictly positive compact lower bound in the sense of the operator order with respect to time, then the output of the algorithm is consistent with the unknown function in mean square. Finally, for the case with independent and non-identically distributed data streams, the algorithm achieves the mean square consistency provided the marginal probability measures induced by the input data are slowly time-varying and the average measure over each fixed-length time period has a uniformly strictly positive lower bound.
Read more6/11/2024
↗️
0
Convergence analysis of online algorithms for vector-valued kernel regression
Michael Griebel, Peter Oswald
We consider the problem of approximating the regression function from noisy vector-valued data by an online learning algorithm using an appropriate reproducing kernel Hilbert space (RKHS) as prior. In an online algorithm, i.i.d. samples become available one by one by a random process and are successively processed to build approximations to the regression function. We are interested in the asymptotic performance of such online approximation algorithms and show that the expected squared error in the RKHS norm can be bounded by $C^2 (m+1)^{-s/(2+s)}$, where $m$ is the current number of processed data, the parameter $0<sleq 1$ expresses an additional smoothness assumption on the regression function and the constant $C$ depends on the variance of the input noise, the smoothness of the regression function and further parameters of the algorithm.
Read more4/30/2024
↗️
0
Learning Analysis of Kernel Ridgeless Regression with Asymmetric Kernel Learning
Fan He, Mingzhen He, Lei Shi, Xiaolin Huang, Johan A. K. Suykens
Ridgeless regression has garnered attention among researchers, particularly in light of the ``Benign Overfitting'' phenomenon, where models interpolating noisy samples demonstrate robust generalization. However, kernel ridgeless regression does not always perform well due to the lack of flexibility. This paper enhances kernel ridgeless regression with Locally-Adaptive-Bandwidths (LAB) RBF kernels, incorporating kernel learning techniques to improve performance in both experiments and theory. For the first time, we demonstrate that functions learned from LAB RBF kernels belong to an integral space of Reproducible Kernel Hilbert Spaces (RKHSs). Despite the absence of explicit regularization in the proposed model, its optimization is equivalent to solving an $ell_0$-regularized problem in the integral space of RKHSs, elucidating the origin of its generalization ability. Taking an approximation analysis viewpoint, we introduce an $l_q$-norm analysis technique (with $0<q<1$) to derive the learning rate for the proposed model under mild conditions. This result deepens our theoretical understanding, explaining that our algorithm's robust approximation ability arises from the large capacity of the integral space of RKHSs, while its generalization ability is ensured by sparsity, controlled by the number of support vectors. Experimental results on both synthetic and real datasets validate our theoretical conclusions.
Read more6/4/2024