A Statistical Theory of Regularization-Based Continual Learning
2406.06213
0
0

Abstract
We provide a statistical analysis of regularization-based continual learning on a sequence of linear regression tasks, with emphasis on how different regularization terms affect the model performance. We first derive the convergence rate for the oracle estimator obtained as if all data were available simultaneously. Next, we consider a family of generalized $ell_2$-regularization algorithms indexed by matrix-valued hyperparameters, which includes the minimum norm estimator and continual ridge regression as special cases. As more tasks are introduced, we derive an iterative update formula for the estimation error of generalized $ell_2$-regularized estimators, from which we determine the hyperparameters resulting in the optimal algorithm. Interestingly, the choice of hyperparameters can effectively balance the trade-off between forward and backward knowledge transfer and adjust for data heterogeneity. Moreover, the estimation error of the optimal algorithm is derived explicitly, which is of the same order as that of the oracle estimator. In contrast, our lower bounds for the minimum norm estimator and continual ridge regression show their suboptimality. A byproduct of our theoretical analysis is the equivalence between early stopping and generalized $ell_2$-regularization in continual learning, which may be of independent interest. Finally, we conduct experiments to complement our theory.
Create account to get full access
Overview
- This paper presents a statistical theory for understanding regularization-based continual learning, which is the problem of training a model to learn a sequence of tasks without forgetting previous knowledge.
- The paper analyzes the dynamics of regularization-based continual learning algorithms and derives analytical expressions for the generalization error and catastrophic forgetting in various settings.
- The analysis reveals insights into the role of model heterogeneity, the choice of regularization hyperparameters, and the impact of the training schedule on continual learning performance.
Plain English Explanation
Continual learning is the challenge of training an AI model to learn a series of tasks one after the other, without forgetting what it has learned before. This is a difficult problem because there is a tendency for the model to "catastrophically forget" its previous knowledge as it learns new information.
This paper develops a statistical theory to help understand how regularization-based continual learning algorithms work. Regularization refers to techniques that add extra constraints or penalties to the training process to help the model generalize better.
The paper analyzes the mathematical dynamics of how these regularization-based continual learning algorithms behave. It derives equations that describe how the model's performance and ability to retain previous knowledge are affected by factors like:
- The diversity of the tasks the model is learning - models that learn more heterogeneous tasks tend to perform better
- The choice of regularization hyperparameters - the authors provide guidance on how to set these for optimal continual learning
- The order and timing of when the different tasks are presented during training - the training schedule can significantly impact performance
By understanding these factors through a rigorous mathematical analysis, the paper aims to provide insights that can help improve the design of continual learning systems.
Technical Explanation
The paper develops a statistical theory for analyzing regularization-based continual learning algorithms. The authors model the continual learning process as a sequence of linear regression tasks, where the model parameters evolve over time as new tasks are encountered.
The core of the analysis focuses on deriving expressions for the model's generalization error and the degree of catastrophic forgetting, as functions of the regularization hyperparameters, the task heterogeneity, and the training schedule.
Key technical insights from the analysis include:
-
Task heterogeneity plays a crucial role - models that learn more diverse tasks tend to exhibit less catastrophic forgetting and better overall performance.
-
The choice of regularization hyperparameters is important - the authors provide guidelines for setting these parameters to balance learning new tasks and retaining old knowledge.
-
The order and timing of task presentation impacts performance - the authors show how the training schedule can be optimized to mitigate catastrophic forgetting.
-
[Regularization-based continual learning can be analyzed using a vector-valued spectral regularization framework - this provides a unifying perspective that connects various continual learning algorithms.
The paper validates these theoretical insights through numerical experiments on synthetic and real-world datasets.
Critical Analysis
The paper provides a comprehensive theoretical analysis of regularization-based continual learning, deriving important insights that can inform the design of more effective continual learning systems. However, there are some limitations and areas for further research:
-
The analysis is primarily focused on linear regression tasks, which may not fully capture the complexity of real-world continual learning problems involving deep neural networks. Extending the theory to more expressive model classes would be valuable.
-
The paper assumes a specific regularization-based framework and does not consider other continual learning approaches, such as rehearsal-based methods or meta-learning techniques. Exploring the connections between these different approaches would provide a more holistic understanding of continual learning.
-
While the paper offers guidance on setting regularization hyperparameters, the sensitivity of continual learning performance to these choices could be further investigated. Developing more robust and adaptive hyperparameter tuning strategies would be valuable.
-
The theoretical analysis assumes a somewhat idealized setting, and it would be important to validate the insights on more realistic and challenging continual learning benchmarks, including tasks with non-stationary data distributions and complex dependencies between tasks.
Overall, this paper represents an important step towards a more rigorous and principled understanding of continual learning, but there is still much work to be done to fully address the challenges of this critical problem in machine learning.
Conclusion
This paper presents a statistical theory for analyzing regularization-based continual learning algorithms. The key insights derived from the analysis include the crucial role of task heterogeneity, the importance of carefully selecting regularization hyperparameters, and the impact of the training schedule on mitigating catastrophic forgetting.
By providing a rigorous mathematical framework for understanding the dynamics of continual learning, this work lays the groundwork for the development of more effective and robust continual learning systems. The insights gained can inform the design of improved regularization techniques, task-scheduling strategies, and other continual learning approaches, ultimately advancing the field's ability to build AI systems that can continuously adapt and learn over time.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
Fixed Design Analysis of Regularization-Based Continual Learning
Haoran Li, Jingfeng Wu, Vladimir Braverman
0
0
We consider a continual learning (CL) problem with two linear regression tasks in the fixed design setting, where the feature vectors are assumed fixed and the labels are assumed to be random variables. We consider an $ell_2$-regularized CL algorithm, which computes an Ordinary Least Squares parameter to fit the first dataset, then computes another parameter that fits the second dataset under an $ell_2$-regularization penalizing its deviation from the first parameter, and outputs the second parameter. For this algorithm, we provide tight bounds on the average risk over the two tasks. Our risk bounds reveal a provable trade-off between forgetting and intransigence of the $ell_2$-regularized CL algorithm: with a large regularization parameter, the algorithm output forgets less information about the first task but is intransigent to extract new information from the second task; and vice versa. Our results suggest that catastrophic forgetting could happen for CL with dissimilar tasks (under a precise similarity measurement) and that a well-tuned $ell_2$-regularization can partially mitigate this issue by introducing intransigence.
6/19/2024
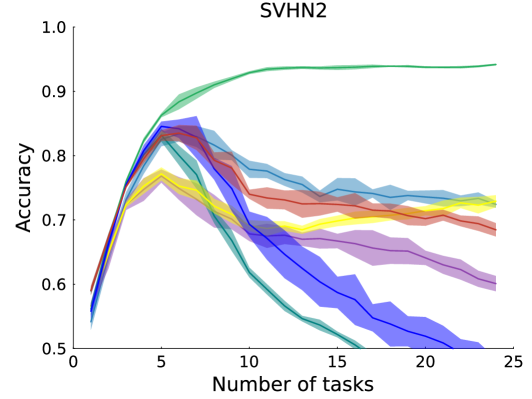
Learning Continually by Spectral Regularization
Alex Lewandowski, Saurabh Kumar, Dale Schuurmans, Andr'as Gyorgy, Marlos C. Machado
0
0
Loss of plasticity is a phenomenon where neural networks become more difficult to train during the course of learning. Continual learning algorithms seek to mitigate this effect by sustaining good predictive performance while maintaining network trainability. We develop new techniques for improving continual learning by first reconsidering how initialization can ensure trainability during early phases of learning. From this perspective, we derive new regularization strategies for continual learning that ensure beneficial initialization properties are better maintained throughout training. In particular, we investigate two new regularization techniques for continual learning: (i) Wasserstein regularization toward the initial weight distribution, which is less restrictive than regularizing toward initial weights; and (ii) regularizing weight matrix singular values, which directly ensures gradient diversity is maintained throughout training. We present an experimental analysis that shows these alternative regularizers can improve continual learning performance across a range of supervised learning tasks and model architectures. The alternative regularizers prove to be less sensitive to hyperparameters while demonstrating better training in individual tasks, sustaining trainability as new tasks arrive, and achieving better generalization performance.
6/12/2024
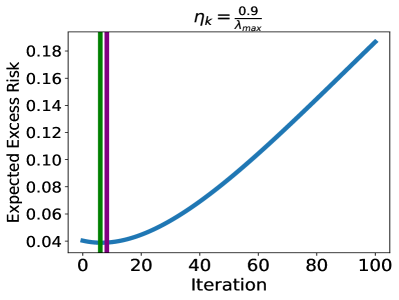
On Regularization via Early Stopping for Least Squares Regression
Rishi Sonthalia, Jackie Lok, Elizaveta Rebrova
0
0
A fundamental problem in machine learning is understanding the effect of early stopping on the parameters obtained and the generalization capabilities of the model. Even for linear models, the effect is not fully understood for arbitrary learning rates and data. In this paper, we analyze the dynamics of discrete full batch gradient descent for linear regression. With minimal assumptions, we characterize the trajectory of the parameters and the expected excess risk. Using this characterization, we show that when training with a learning rate schedule $eta_k$, and a finite time horizon $T$, the early stopped solution $beta_T$ is equivalent to the minimum norm solution for a generalized ridge regularized problem. We also prove that early stopping is beneficial for generic data with arbitrary spectrum and for a wide variety of learning rate schedules. We provide an estimate for the optimal stopping time and empirically demonstrate the accuracy of our estimate.
6/10/2024
🌿
Decentralized Online Regularized Learning Over Random Time-Varying Graphs
Xiwei Zhang, Tao Li, Xiaozheng Fu
0
0
We study the decentralized online regularized linear regression algorithm over random time-varying graphs. At each time step, every node runs an online estimation algorithm consisting of an innovation term processing its own new measurement, a consensus term taking a weighted sum of estimations of its own and its neighbors with additive and multiplicative communication noises and a regularization term preventing over-fitting. It is not required that the regression matrices and graphs satisfy special statistical assumptions such as mutual independence, spatio-temporal independence or stationarity. We develop the nonnegative supermartingale inequality of the estimation error, and prove that the estimations of all nodes converge to the unknown true parameter vector almost surely if the algorithm gains, graphs and regression matrices jointly satisfy the sample path spatio-temporal persistence of excitation condition. Especially, this condition holds by choosing appropriate algorithm gains if the graphs are uniformly conditionally jointly connected and conditionally balanced, and the regression models of all nodes are uniformly conditionally spatio-temporally jointly observable, under which the algorithm converges in mean square and almost surely. In addition, we prove that the regret upper bound is $O(T^{1-tau}ln T)$, where $tauin (0.5,1)$ is a constant depending on the algorithm gains.
4/23/2024