Smart Expert System: Large Language Models as Text Classifiers
2405.10523
0
0
Abstract
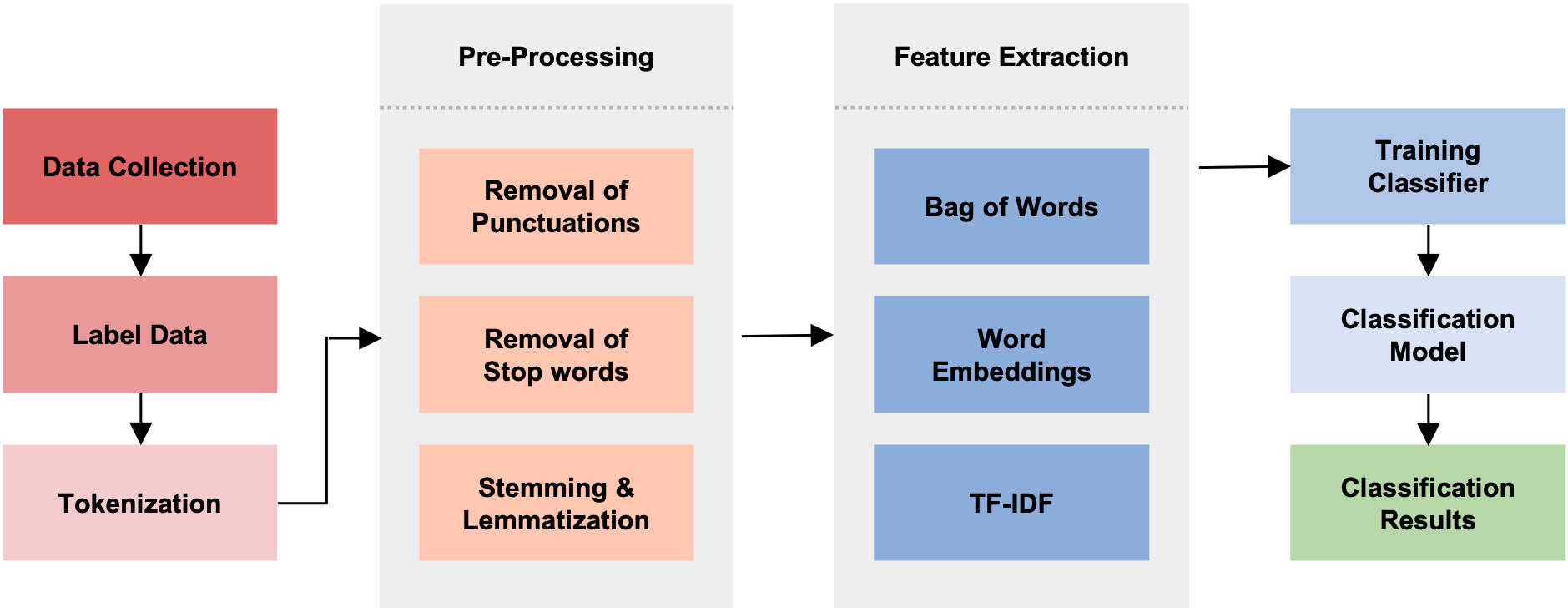
Text classification is a fundamental task in Natural Language Processing (NLP), and the advent of Large Language Models (LLMs) has revolutionized the field. This paper introduces the Smart Expert System, a novel approach that leverages LLMs as text classifiers. The system simplifies the traditional text classification workflow, eliminating the need for extensive preprocessing and domain expertise. The performance of several LLMs, machine learning (ML) algorithms, and neural network (NN) based structures is evaluated on four datasets. Results demonstrate that certain LLMs surpass traditional methods in sentiment analysis, spam SMS detection and multi-label classification. Furthermore, it is shown that the system's performance can be further enhanced through few-shot or fine-tuning strategies, making the fine-tuned model the top performer across all datasets. Source code and datasets are available in this GitHub repository: https://github.com/yeyimilk/llm-zero-shot-classifiers.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) as text classifiers for building smart expert systems.
- It investigates the performance of LLMs, such as GPT-4, in text classification tasks across various domains.
- The paper also examines the potential of LLMs for few-shot learning and fine-tuning in these classification tasks.
Plain English Explanation
Large language models (LLMs) like GPT-4 are powerful AI systems that can understand and generate human-like text. This paper looks at how these LLMs can be used as "text classifiers" - systems that can analyze and categorize different types of text.
The researchers tested LLMs on a variety of text classification tasks, such as determining the sentiment or topic of a piece of writing. They found that LLMs can perform well on these tasks, often matching or even exceeding the performance of traditional machine learning models. This suggests that LLMs could be useful for building "smart expert systems" - AI systems that can provide expert-level analysis and decision-making in different domains.
The paper also explores how LLMs can be fine-tuned or adapted to specific tasks using only a small amount of training data. This "few-shot learning" approach could make it easier to apply LLMs to new classification problems without requiring a large dataset. Overall, the findings indicate that LLMs have significant potential for powering the next generation of advanced text analysis tools and smart expert systems.
Technical Explanation
The researchers evaluated the performance of large language models (LLMs), such as GPT-4, on a variety of text classification tasks. They compared the LLMs' performance to that of traditional machine learning models across different domains, including sentiment analysis, topic classification, and more.
The paper's key experimental findings include:
- LLMs were able to match or outperform traditional models on many text classification tasks, demonstrating their strong capabilities as text classifiers.
- LLMs were effective at few-shot learning, requiring only a small amount of training data to adapt to new classification problems.
- Fine-tuning LLMs on specific tasks further improved their performance, suggesting that they can be effectively customized for various smart expert system applications.
The researchers also discussed the implications of their findings for the development of advanced text analysis tools and smart expert systems that leverage the power of large language models.
Critical Analysis
The paper provides a comprehensive evaluation of LLMs as text classifiers, but it also acknowledges several caveats and areas for further research:
- The performance of LLMs may vary depending on the specific task and dataset, and the researchers note that more extensive testing is needed to fully understand their capabilities and limitations.
- The paper does not delve into the interpretability or explainability of the LLM-based text classification models, which is an important consideration for deploying such systems in real-world applications.
- The researchers suggest that future work should explore ways to further improve the efficiency and scalability of LLM-based text classifiers, as well as investigate their robustness to noisy or adversarial input data.
Overall, the paper presents a promising exploration of the use of LLMs for text classification and smart expert systems, but more research is needed to fully understand the practical implications and potential challenges of this approach.
Conclusion
This paper demonstrates the strong potential of large language models (LLMs) as text classifiers for building smart expert systems. The researchers found that LLMs can match or exceed the performance of traditional machine learning models on a variety of text classification tasks, while also showing promise for few-shot learning and fine-tuning.
These findings suggest that LLMs could be a powerful tool for developing advanced text analysis and decision-support systems that can provide expert-level insights across different domains. As the capabilities of LLMs continue to evolve, the integration of these models into smart expert systems could lead to significant advancements in areas such as recommender systems, educational assessment, and other applications that require accurate and adaptable text-based analysis.
While further research is needed to address certain limitations and challenges, this paper provides an important step forward in understanding how large language models can be leveraged to build the next generation of smart expert systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Model Enhanced Machine Learning Estimators for Classification
Yuhang Wu, Yingfei Wang, Chu Wang, Zeyu Zheng
0
0
Pre-trained large language models (LLM) have emerged as a powerful tool for simulating various scenarios and generating output given specific instructions and multimodal input. In this work, we analyze the specific use of LLM to enhance a classical supervised machine learning method for classification problems. We propose a few approaches to integrate LLM into a classical machine learning estimator to further enhance the prediction performance. We examine the performance of the proposed approaches through both standard supervised learning binary classification tasks, and a transfer learning task where the test data observe distribution changes compared to the training data. Numerical experiments using four publicly available datasets are conducted and suggest that using LLM to enhance classical machine learning estimators can provide significant improvement on prediction performance.
5/10/2024

Fine-Tuned 'Small' LLMs (Still) Significantly Outperform Zero-Shot Generative AI Models in Text Classification
Martin Juan Jos'e Bucher, Marco Martini
0
0
Generative AI offers a simple, prompt-based alternative to fine-tuning smaller BERT-style LLMs for text classification tasks. This promises to eliminate the need for manually labeled training data and task-specific model training. However, it remains an open question whether tools like ChatGPT can deliver on this promise. In this paper, we show that smaller, fine-tuned LLMs (still) consistently and significantly outperform larger, zero-shot prompted models in text classification. We compare three major generative AI models (ChatGPT with GPT-3.5/GPT-4 and Claude Opus) with several fine-tuned LLMs across a diverse set of classification tasks (sentiment, approval/disapproval, emotions, party positions) and text categories (news, tweets, speeches). We find that fine-tuning with application-specific training data achieves superior performance in all cases. To make this approach more accessible to a broader audience, we provide an easy-to-use toolkit alongside this paper. Our toolkit, accompanied by non-technical step-by-step guidance, enables users to select and fine-tune BERT-like LLMs for any classification task with minimal technical and computational effort.
6/14/2024

Zero-Shot Spam Email Classification Using Pre-trained Large Language Models
Sergio Rojas-Galeano
0
0
This paper investigates the application of pre-trained large language models (LLMs) for spam email classification using zero-shot prompting. We evaluate the performance of both open-source (Flan-T5) and proprietary LLMs (ChatGPT, GPT-4) on the well-known SpamAssassin dataset. Two classification approaches are explored: (1) truncated raw content from email subject and body, and (2) classification based on summaries generated by ChatGPT. Our empirical analysis, leveraging the entire dataset for evaluation without further training, reveals promising results. Flan-T5 achieves a 90% F1-score on the truncated content approach, while GPT-4 reaches a 95% F1-score using summaries. While these initial findings on a single dataset suggest the potential for classification pipelines of LLM-based subtasks (e.g., summarisation and classification), further validation on diverse datasets is necessary. The high operational costs of proprietary models, coupled with the general inference costs of LLMs, could significantly hinder real-world deployment for spam filtering.
5/28/2024
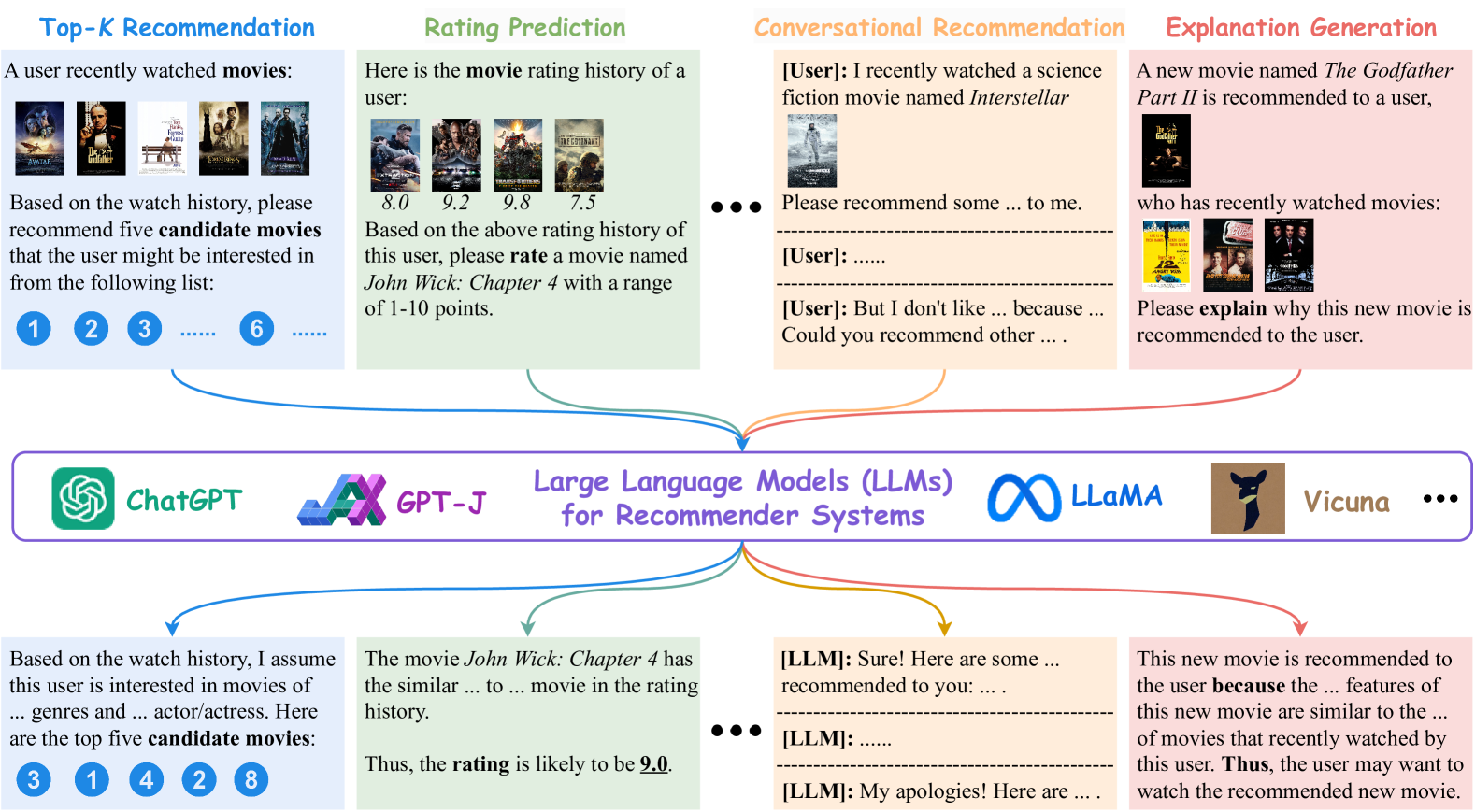
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
0
0
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
4/23/2024