Zero-Shot Spam Email Classification Using Pre-trained Large Language Models
2405.15936
0
0

Abstract
This paper investigates the application of pre-trained large language models (LLMs) for spam email classification using zero-shot prompting. We evaluate the performance of both open-source (Flan-T5) and proprietary LLMs (ChatGPT, GPT-4) on the well-known SpamAssassin dataset. Two classification approaches are explored: (1) truncated raw content from email subject and body, and (2) classification based on summaries generated by ChatGPT. Our empirical analysis, leveraging the entire dataset for evaluation without further training, reveals promising results. Flan-T5 achieves a 90% F1-score on the truncated content approach, while GPT-4 reaches a 95% F1-score using summaries. While these initial findings on a single dataset suggest the potential for classification pipelines of LLM-based subtasks (e.g., summarisation and classification), further validation on diverse datasets is necessary. The high operational costs of proprietary models, coupled with the general inference costs of LLMs, could significantly hinder real-world deployment for spam filtering.
Create account to get full access
Overview
- The paper explores using pre-trained large language models (LLMs) for zero-shot spam email classification, where the model is trained on a general task and then applied to the spam classification problem without any additional training.
- The researchers investigate the performance of various state-of-the-art LLMs, including GPT-3, BERT, and other models, on spam email classification tasks.
- The goal is to demonstrate the ability of these pre-trained models to effectively tackle the spam email classification problem without the need for specialized training, which can be time-consuming and resource-intensive.
Plain English Explanation
The paper explores a novel approach to identifying spam emails using pre-trained large language models (LLMs). These LLMs, such as GPT-3 and BERT, are powerful AI systems that have been trained on vast amounts of text data to understand and generate human-like language.
The researchers wanted to see if these pre-trained LLMs could be used to classify emails as spam or not, without having to train the models specifically on spam data. This "zero-shot" approach is appealing because it means the spam classification can be done without the need for laborious and expensive data annotation and model fine-tuning.
The key idea is to use the general language understanding capabilities of the LLMs to identify patterns and characteristics that distinguish spam emails from legitimate ones. The researchers tested various state-of-the-art LLMs on spam email classification tasks and found that they were able to achieve promising results, demonstrating the potential of this approach.
This research is significant because it suggests that pre-trained LLMs could be leveraged to tackle a wide range of text-based classification tasks, including spam detection, without the need for extensive specialized training. This could lead to more efficient and cost-effective solutions for real-world problems, as well as accelerate progress in natural language processing (NLP) and AI more broadly.
Technical Explanation
The paper presents a study on using pre-trained large language models for zero-shot spam email classification. The researchers evaluate the performance of various state-of-the-art LLMs, including GPT-3, BERT, and others, on the task of identifying spam emails without any model fine-tuning or specialized training on spam data.
The researchers first curate a dataset of labeled spam and non-spam emails. They then use a "zero-shot" approach, where the pre-trained LLMs are directly applied to the spam classification task without any additional training. The key idea is to leverage the general language understanding capabilities of the LLMs to identify patterns and characteristics that distinguish spam emails from legitimate ones.
The paper compares the performance of different LLMs on the spam classification task, using metrics such as accuracy, precision, recall, and F1-score. The results show that the LLMs are able to achieve promising results on the spam detection task, with some models outperforming others.
The researchers also conduct an in-depth analysis of the LLMs' performance, investigating the impact of various factors such as model size, task-specific prompting, and the use of ensemble methods. Additionally, they explore the potential of incorporating domain-specific knowledge into the LLMs to further enhance their spam detection capabilities.
The findings of this study suggest that pre-trained LLMs can be effectively leveraged for zero-shot spam email classification, without the need for specialized training. This approach has the potential to streamline the development of spam detection systems, reducing the time and resources required for data annotation and model fine-tuning.
Critical Analysis
The paper presents a compelling and well-designed study on the use of pre-trained LLMs for zero-shot spam email classification. The researchers have done a commendable job in curating a relevant dataset, evaluating the performance of various state-of-the-art models, and providing a thorough analysis of the results.
One potential limitation of the study is the reliance on a single dataset for evaluation. It would be valuable to see the performance of the LLMs tested on a more diverse set of spam email datasets, as the characteristics and composition of spam can vary across different domains and time periods. Expanding the evaluation to include multiple datasets could help validate the robustness and generalizability of the findings.
Additionally, the paper does not delve deeply into the underlying reasons for the differences in performance between the various LLMs. It would be interesting to investigate the specific linguistic and semantic features that enable some models to outperform others on the spam detection task. This could provide valuable insights into the strengths and limitations of different LLM architectures and training approaches.
Finally, the paper briefly mentions the potential of incorporating domain-specific knowledge into the LLMs to further enhance their spam detection capabilities. Exploring this direction in more depth, perhaps through the use of expert systems or other knowledge-based techniques, could lead to even more robust and reliable spam classification systems.
Overall, the research presented in this paper is a valuable contribution to the field of NLP and spam detection. The findings demonstrate the potential of leveraging pre-trained LLMs for zero-shot classification tasks, which could have far-reaching implications for a variety of real-world applications.
Conclusion
This paper explores the use of pre-trained large language models (LLMs) for zero-shot spam email classification, a task that typically requires specialized training and data annotation. The researchers evaluate the performance of various state-of-the-art LLMs, including GPT-3, BERT, and others, on spam detection without any additional fine-tuning or model training.
The results show that these pre-trained LLMs are able to achieve promising performance on the spam classification task, demonstrating the potential of this "zero-shot" approach. This is a significant finding, as it suggests that LLMs can be leveraged to tackle a wide range of text-based classification problems without the need for extensive specialized training, which can be time-consuming and resource-intensive.
The implications of this research are far-reaching. By enabling more efficient and cost-effective solutions for spam detection and other text-based classification tasks, the use of pre-trained LLMs could have a transformative impact on a variety of real-world applications, from email management to content moderation and beyond. Additionally, this study contributes to the broader progress in natural language processing and artificial intelligence, paving the way for further advancements in these fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Fine-Tuned 'Small' LLMs (Still) Significantly Outperform Zero-Shot Generative AI Models in Text Classification
Martin Juan Jos'e Bucher, Marco Martini
0
0
Generative AI offers a simple, prompt-based alternative to fine-tuning smaller BERT-style LLMs for text classification tasks. This promises to eliminate the need for manually labeled training data and task-specific model training. However, it remains an open question whether tools like ChatGPT can deliver on this promise. In this paper, we show that smaller, fine-tuned LLMs (still) consistently and significantly outperform larger, zero-shot prompted models in text classification. We compare three major generative AI models (ChatGPT with GPT-3.5/GPT-4 and Claude Opus) with several fine-tuned LLMs across a diverse set of classification tasks (sentiment, approval/disapproval, emotions, party positions) and text categories (news, tweets, speeches). We find that fine-tuning with application-specific training data achieves superior performance in all cases. To make this approach more accessible to a broader audience, we provide an easy-to-use toolkit alongside this paper. Our toolkit, accompanied by non-technical step-by-step guidance, enables users to select and fine-tune BERT-like LLMs for any classification task with minimal technical and computational effort.
6/14/2024
Evaluating the Performance of ChatGPT for Spam Email Detection
Shijing Si, Yuwei Wu, Le Tang, Yugui Zhang, Jedrek Wosik
0
0
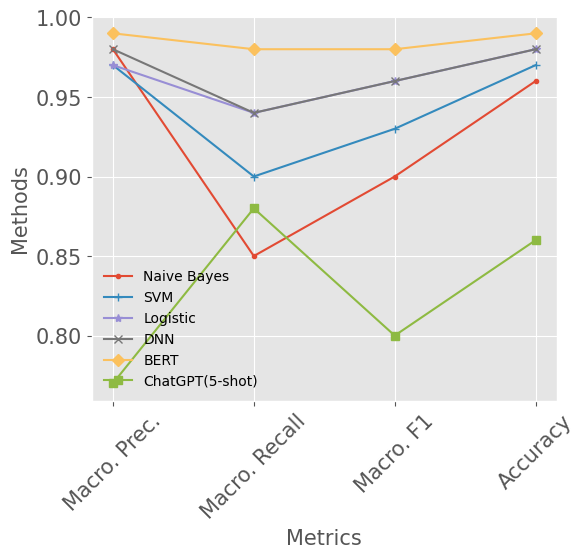
Email continues to be a pivotal and extensively utilized communication medium within professional and commercial domains. Nonetheless, the prevalence of spam emails poses a significant challenge for users, disrupting their daily routines and diminishing productivity. Consequently, accurately identifying and filtering spam based on content has become crucial for cybersecurity. Recent advancements in natural language processing, particularly with large language models like ChatGPT, have shown remarkable performance in tasks such as question answering and text generation. However, its potential in spam identification remains underexplored. To fill in the gap, this study attempts to evaluate ChatGPT's capabilities for spam identification in both English and Chinese email datasets. We employ ChatGPT for spam email detection using in-context learning, which requires a prompt instruction and a few demonstrations. We also investigate how the number of demonstrations in the prompt affects the performance of ChatGPT. For comparison, we also implement five popular benchmark methods, including naive Bayes, support vector machines (SVM), logistic regression (LR), feedforward dense neural networks (DNN), and BERT classifiers. Through extensive experiments, the performance of ChatGPT is significantly worse than deep supervised learning methods in the large English dataset, while it presents superior performance on the low-resourced Chinese dataset.
6/21/2024
💬
A Zero-shot and Few-shot Study of Instruction-Finetuned Large Language Models Applied to Clinical and Biomedical Tasks
Yanis Labrak, Mickael Rouvier, Richard Dufour
0
0
We evaluate four state-of-the-art instruction-tuned large language models (LLMs) -- ChatGPT, Flan-T5 UL2, Tk-Instruct, and Alpaca -- on a set of 13 real-world clinical and biomedical natural language processing (NLP) tasks in English, such as named-entity recognition (NER), question-answering (QA), relation extraction (RE), etc. Our overall results demonstrate that the evaluated LLMs begin to approach performance of state-of-the-art models in zero- and few-shot scenarios for most tasks, and particularly well for the QA task, even though they have never seen examples from these tasks before. However, we observed that the classification and RE tasks perform below what can be achieved with a specifically trained model for the medical field, such as PubMedBERT. Finally, we noted that no LLM outperforms all the others on all the studied tasks, with some models being better suited for certain tasks than others.
6/11/2024
Smart Expert System: Large Language Models as Text Classifiers
Zhiqiang Wang, Yiran Pang, Yanbin Lin
0
0
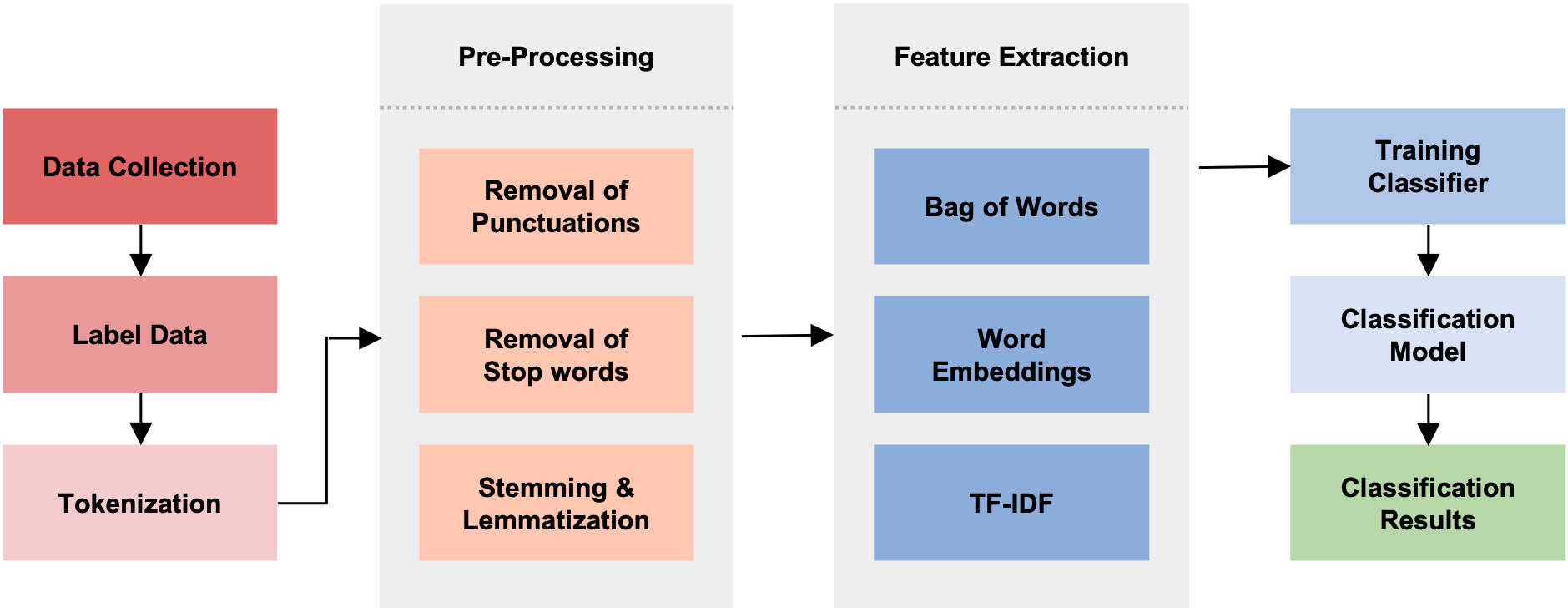
Text classification is a fundamental task in Natural Language Processing (NLP), and the advent of Large Language Models (LLMs) has revolutionized the field. This paper introduces the Smart Expert System, a novel approach that leverages LLMs as text classifiers. The system simplifies the traditional text classification workflow, eliminating the need for extensive preprocessing and domain expertise. The performance of several LLMs, machine learning (ML) algorithms, and neural network (NN) based structures is evaluated on four datasets. Results demonstrate that certain LLMs surpass traditional methods in sentiment analysis, spam SMS detection and multi-label classification. Furthermore, it is shown that the system's performance can be further enhanced through few-shot or fine-tuning strategies, making the fine-tuned model the top performer across all datasets. Source code and datasets are available in this GitHub repository: https://github.com/yeyimilk/llm-zero-shot-classifiers.
5/20/2024