SMC++: Masked Learning of Unsupervised Video Semantic Compression
2406.04765
0
0
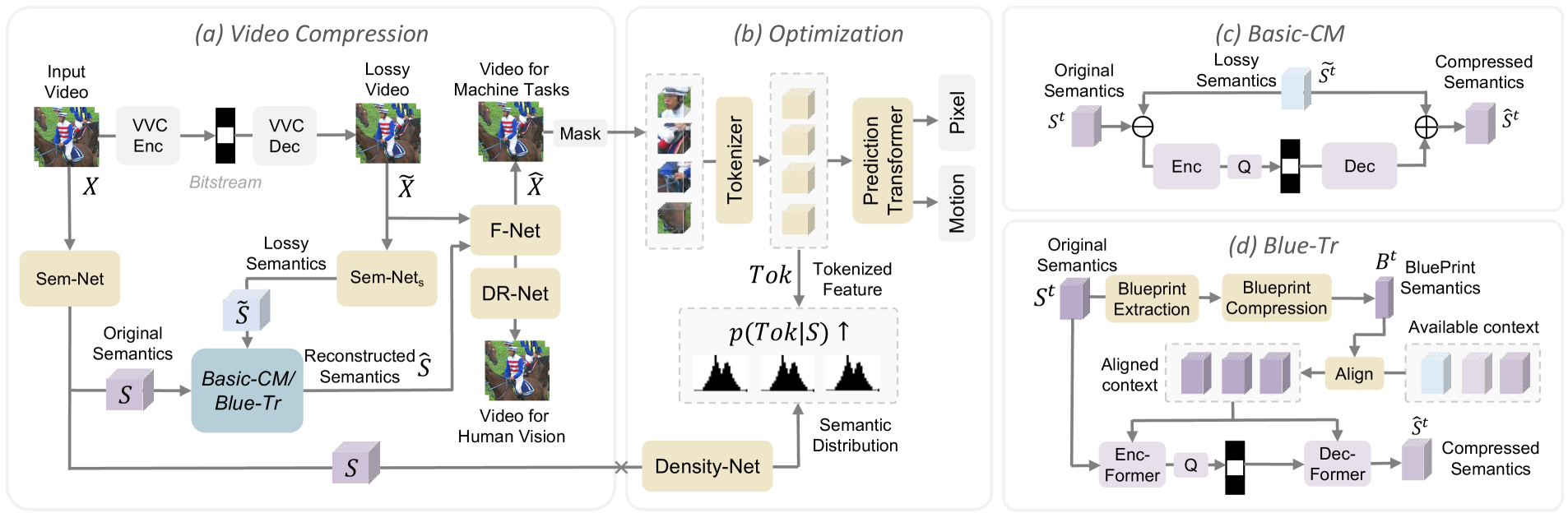
Abstract
Most video compression methods focus on human visual perception, neglecting semantic preservation. This leads to severe semantic loss during the compression, hampering downstream video analysis tasks. In this paper, we propose a Masked Video Modeling (MVM)-powered compression framework that particularly preserves video semantics, by jointly mining and compressing the semantics in a self-supervised manner. While MVM is proficient at learning generalizable semantics through the masked patch prediction task, it may also encode non-semantic information like trivial textural details, wasting bitcost and bringing semantic noises. To suppress this, we explicitly regularize the non-semantic entropy of the compressed video in the MVM token space. The proposed framework is instantiated as a simple Semantic-Mining-then-Compression (SMC) model. Furthermore, we extend SMC as an advanced SMC++ model from several aspects. First, we equip it with a masked motion prediction objective, leading to better temporal semantic learning ability. Second, we introduce a Transformer-based compression module, to improve the semantic compression efficacy. Considering that directly mining the complex redundancy among heterogeneous features in different coding stages is non-trivial, we introduce a compact blueprint semantic representation to align these features into a similar form, fully unleashing the power of the Transformer-based compression module. Extensive results demonstrate the proposed SMC and SMC++ models show remarkable superiority over previous traditional, learnable, and perceptual quality-oriented video codecs, on three video analysis tasks and seven datasets. textit{Codes and model are available at: url{https://github.com/tianyuan168326/VideoSemanticCompression-Pytorch}.
Create account to get full access
Overview
• This paper presents SMC++, a novel approach to unsupervised video semantic compression that uses masked learning techniques. • The method aims to learn compact video representations that can be used for various downstream tasks, such as video action recognition. • The key ideas include masking video frames during training to encourage the model to learn semantically meaningful representations, and incorporating a disentanglement module to separate content and motion information.
Plain English Explanation
The researchers developed a new technique called SMC++ for compressing video data in a way that preserves the semantic meaning of the content. Unlike traditional video compression methods that focus on reducing file size, SMC++ tries to learn a compact representation of the video that can be used for tasks like identifying the actions and events happening in the video.
The core idea is to randomly "mask" or hide parts of the video frames during the training process. This forces the model to learn how to fill in the missing information and understand the overall meaning of the video, rather than just memorizing the raw pixel data. The model also includes a special module to separate the "content" (what's in the scene) from the "motion" (how things are moving), which helps it to generate more meaningful compressed representations.
By learning these semantically-rich video representations in an unsupervised way (without human-labeled data), the SMC++ model can be applied to a variety of video understanding tasks, like recognizing the actions and events happening in a video. This could be useful for applications like video search, surveillance, or virtual reality.
Technical Explanation
The key technical innovations in SMC++ include:
- Masked Video Modeling: The model is trained to predict the masked parts of video frames, forcing it to learn semantically meaningful representations of the video content.
- Content-Motion Disentanglement: SMC++ includes a disentanglement module that separates the video's content (what's in the scene) from its motion (how things are moving), allowing for more efficient compression.
- Unsupervised Pre-training: The model is pre-trained on large unlabeled video datasets, enabling it to learn general video representations without the need for human-annotated data.
The architecture consists of an encoder that maps the input video into a compressed latent representation, a decoder that reconstructs the original video from the latent representation, and the disentanglement module that separates content and motion. During training, the model is tasked with predicting the masked parts of the video frames, encouraging it to learn semantically meaningful features.
The researchers evaluate SMC++ on various video compression and understanding tasks, including video action recognition and video semantic segmentation. The results demonstrate that SMC++ can outperform previous video compression methods while also enabling better performance on downstream video understanding tasks.
Critical Analysis
The paper provides a thorough evaluation of SMC++ and highlights its strengths, but also acknowledges some potential limitations and areas for future work:
- The model's performance is still dependent on the quality and diversity of the pre-training data, which may limit its generalization to unseen domains.
- The content-motion disentanglement module, while effective, may not fully capture all the nuances of video semantics, and further research is needed to improve this aspect.
- The paper focuses on static video compression, but extending the approach to handle dynamic, time-varying video content could be an interesting direction for future work.
Additionally, while the paper demonstrates the benefits of SMC++ for video understanding tasks, there may be some concerns about the potential privacy and ethical implications of such powerful video compression and analysis technologies, especially in surveillance or monitoring applications. These are important considerations that the research community should continue to explore.
Conclusion
Overall, the SMC++ paper presents a promising approach to unsupervised video semantic compression that could have significant implications for a wide range of video-based applications, from video search and summarization to virtual reality and autonomous systems. By learning semantically-rich video representations in an efficient and scalable way, SMC++ opens up new opportunities for more intelligent and responsive video processing technologies that can better understand and interact with the visual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Semantic Segmentation on VSPW Dataset through Masked Video Consistency
Chen Liang, Qiang Guo, Chongkai Yu, Chengjing Wu, Ting Liu, Luoqi Liu
0
0
Pixel-level Video Understanding requires effectively integrating three-dimensional data in both spatial and temporal dimensions to learn accurate and stable semantic information from continuous frames. However, existing advanced models on the VSPW dataset have not fully modeled spatiotemporal relationships. In this paper, we present our solution for the PVUW competition, where we introduce masked video consistency (MVC) based on existing models. MVC enforces the consistency between predictions of masked frames where random patches are withheld. The model needs to learn the segmentation results of the masked parts through the context of images and the relationship between preceding and succeeding frames of the video. Additionally, we employed test-time augmentation, model aggeregation and a multimodal model-based post-processing method. Our approach achieves 67.27% mIoU performance on the VSPW dataset, ranking 2nd place in the PVUW2024 challenge VSS track.
6/10/2024

SemanticMIM: Marring Masked Image Modeling with Semantics Compression for General Visual Representation
Yike Yuan, Huanzhang Dou, Fengjun Guo, Xi Li
0
0
This paper represents a neat yet effective framework, named SemanticMIM, to integrate the advantages of masked image modeling (MIM) and contrastive learning (CL) for general visual representation. We conduct a thorough comparative analysis between CL and MIM, revealing that their complementary advantages fundamentally stem from two distinct phases, i.e., compression and reconstruction. Specifically, SemanticMIM leverages a proxy architecture that customizes interaction between image and mask tokens, bridging these two phases to achieve general visual representation with the property of abundant semantic and positional awareness. Through extensive qualitative and quantitative evaluations, we demonstrate that SemanticMIM effectively amalgamates the benefits of CL and MIM, leading to significant enhancement of performance and feature linear separability. SemanticMIM also offers notable interpretability through attention response visualization. Codes are available at https://github.com/yyk-wew/SemanticMIM.
6/18/2024

MambaVC: Learned Visual Compression with Selective State Spaces
Shiyu Qin, Jinpeng Wang, Yimin Zhou, Bin Chen, Tianci Luo, Baoyi An, Tao Dai, Shutao Xia, Yaowei Wang
0
0
Learned visual compression is an important and active task in multimedia. Existing approaches have explored various CNN- and Transformer-based designs to model content distribution and eliminate redundancy, where balancing efficacy (i.e., rate-distortion trade-off) and efficiency remains a challenge. Recently, state-space models (SSMs) have shown promise due to their long-range modeling capacity and efficiency. Inspired by this, we take the first step to explore SSMs for visual compression. We introduce MambaVC, a simple, strong and efficient compression network based on SSM. MambaVC develops a visual state space (VSS) block with a 2D selective scanning (2DSS) module as the nonlinear activation function after each downsampling, which helps to capture informative global contexts and enhances compression. On compression benchmark datasets, MambaVC achieves superior rate-distortion performance with lower computational and memory overheads. Specifically, it outperforms CNN and Transformer variants by 9.3% and 15.6% on Kodak, respectively, while reducing computation by 42% and 24%, and saving 12% and 71% of memory. MambaVC shows even greater improvements with high-resolution images, highlighting its potential and scalability in real-world applications. We also provide a comprehensive comparison of different network designs, underscoring MambaVC's advantages. Code is available at https://github.com/QinSY123/2024-MambaVC.
5/29/2024
↗️
MCDS-VSS: Moving Camera Dynamic Scene Video Semantic Segmentation by Filtering with Self-Supervised Geometry and Motion
Angel Villar-Corrales, Moritz Austermann, Sven Behnke
0
0
Autonomous systems, such as self-driving cars, rely on reliable semantic environment perception for decision making. Despite great advances in video semantic segmentation, existing approaches ignore important inductive biases and lack structured and interpretable internal representations. In this work, we propose MCDS-VSS, a structured filter model that learns in a self-supervised manner to estimate scene geometry and ego-motion of the camera, while also estimating the motion of external objects. Our model leverages these representations to improve the temporal consistency of semantic segmentation without sacrificing segmentation accuracy. MCDS-VSS follows a prediction-fusion approach in which scene geometry and camera motion are first used to compensate for ego-motion, then residual flow is used to compensate motion of dynamic objects, and finally the predicted scene features are fused with the current features to obtain a temporally consistent scene segmentation. Our model parses automotive scenes into multiple decoupled interpretable representations such as scene geometry, ego-motion, and object motion. Quantitative evaluation shows that MCDS-VSS achieves superior temporal consistency on video sequences while retaining competitive segmentation performance.
5/31/2024