A Unified Masked Autoencoder with Patchified Skeletons for Motion Synthesis
2308.07301
0
0
📶
Abstract
The synthesis of human motion has traditionally been addressed through task-dependent models that focus on specific challenges, such as predicting future motions or filling in intermediate poses conditioned on known key-poses. In this paper, we present a novel task-independent model called UNIMASK-M, which can effectively address these challenges using a unified architecture. Our model obtains comparable or better performance than the state-of-the-art in each field. Inspired by Vision Transformers (ViTs), our UNIMASK-M model decomposes a human pose into body parts to leverage the spatio-temporal relationships existing in human motion. Moreover, we reformulate various pose-conditioned motion synthesis tasks as a reconstruction problem with different masking patterns given as input. By explicitly informing our model about the masked joints, our UNIMASK-M becomes more robust to occlusions. Experimental results show that our model successfully forecasts human motion on the Human3.6M dataset. Moreover, it achieves state-of-the-art results in motion inbetweening on the LaFAN1 dataset, particularly in long transition periods. More information can be found on the project website https://evm7.github.io/UNIMASKM-page/
Create account to get full access
Overview
- This paper presents a novel AI model called UNIMASK-M that can effectively address various human motion synthesis tasks using a unified architecture.
- Inspired by Vision Transformers (ViTs), UNIMASK-M decomposes a human pose into body parts to leverage the spatio-temporal relationships in human motion.
- The model can perform tasks like motion forecasting and motion in-betweening by reformulating them as reconstruction problems with different masking patterns.
- UNIMASK-M achieves comparable or better performance than state-of-the-art models on these tasks, and is more robust to occlusions.
Plain English Explanation
UNIMASK-M is an AI model that can generate and manipulate human motion in a versatile way. Unlike previous models that were designed for specific tasks, UNIMASK-M uses a single architecture to handle a variety of motion-related challenges.
The key idea is to break down a human pose into different body parts, and then use a Transformer-based Social-MAE approach to understand the relationships between these parts over time. This allows the model to make predictions about future motion or fill in missing parts of a motion sequence.
UNIMASK-M is particularly good at handling occlusions - situations where some body parts are hidden or missing from the input. By explicitly informing the model about which parts are masked, it can learn to be more robust and accurately reconstruct the full motion.
The model has been tested on standard human motion datasets and shows improved performance compared to specialized models, especially for long-term motion prediction and interpolation. This suggests UNIMASK-M is a powerful and versatile tool for a range of human motion synthesis tasks.
Technical Explanation
The key innovation in UNIMASK-M is the use of a Transformer-based architecture inspired by Vision Transformers (ViTs) to model the spatio-temporal relationships in human motion. The model decomposes a human pose into individual body parts, and then uses self-attention to capture the dependencies between these parts over time.
This unified architecture allows UNIMASK-M to address various pose-conditioned motion synthesis tasks, such as motion forecasting and motion in-betweening. The model reformulates these tasks as reconstruction problems with different masking patterns applied to the input poses. By explicitly providing information about the masked joints, UNIMASK-M becomes more robust to occlusions.
Experimental results show that UNIMASK-M achieves state-of-the-art performance on the Human3.6M dataset for motion forecasting, and the LaFAN1 dataset for motion in-betweening, particularly during long transition periods. The model's versatility and occlusion robustness are key advantages over previous task-specific approaches like ImpitationNet and UniEdit.
Critical Analysis
The paper provides a thorough evaluation of UNIMASK-M's performance on standard benchmarks, demonstrating its effectiveness across multiple human motion synthesis tasks. However, the authors do not address some potential limitations of the approach.
For example, the model's reliance on pose decomposition and Transformer-based architectures may limit its scalability to more complex, whole-body motion patterns or scenarios with large numbers of people, as seen in Unified Framework for Human-Centric Point Cloud Video. Additionally, the paper does not explore the model's robustness to noisy or incomplete input data, which could be an important consideration for real-world applications.
Further research could also investigate the interpretability of UNIMASK-M's internal representations and their correspondence to known principles of human motor control and biomechanics. This could lead to additional insights and potential improvements to the model's design.
Conclusion
UNIMASK-M represents a significant advancement in the field of human motion synthesis by introducing a versatile, task-independent model that can handle a variety of challenges, including motion forecasting and in-betweening. Its Transformer-based architecture and pose decomposition approach allow it to capture the complex spatio-temporal relationships in human motion, leading to state-of-the-art performance on standard benchmarks.
While the paper does not address all potential limitations of the approach, UNIMASK-M's demonstrated capabilities suggest it could be a valuable tool for various applications, such as computer animation, robotics, and human-computer interaction. As the field of human motion synthesis continues to evolve, models like UNIMASK-M will play an increasingly important role in advancing our understanding and manipulation of this fundamental aspect of human behavior.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Social-MAE: Social Masked Autoencoder for Multi-person Motion Representation Learning
Mahsa Ehsanpour, Ian Reid, Hamid Rezatofighi
0
0
For a complete comprehension of multi-person scenes, it is essential to go beyond basic tasks like detection and tracking. Higher-level tasks, such as understanding the interactions and social activities among individuals, are also crucial. Progress towards models that can fully understand scenes involving multiple people is hindered by a lack of sufficient annotated data for such high-level tasks. To address this challenge, we introduce Social-MAE, a simple yet effective transformer-based masked autoencoder framework for multi-person human motion data. The framework uses masked modeling to pre-train the encoder to reconstruct masked human joint trajectories, enabling it to learn generalizable and data efficient representations of motion in human crowded scenes. Social-MAE comprises a transformer as the MAE encoder and a lighter-weight transformer as the MAE decoder which operates on multi-person joints' trajectory in the frequency domain. After the reconstruction task, the MAE decoder is replaced with a task-specific decoder and the model is fine-tuned end-to-end for a variety of high-level social tasks. Our proposed model combined with our pre-training approach achieves the state-of-the-art results on various high-level social tasks, including multi-person pose forecasting, social grouping, and social action understanding. These improvements are demonstrated across four popular multi-person datasets encompassing both human 2D and 3D body pose.
4/9/2024
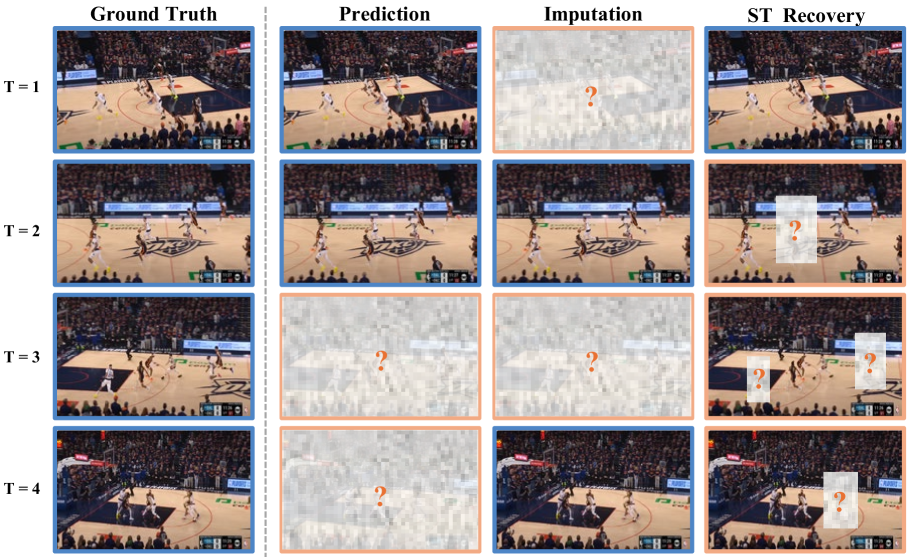
Deciphering Movement: Unified Trajectory Generation Model for Multi-Agent
Yi Xu, Yun Fu
0
0
Understanding multi-agent behavior is critical across various fields. The conventional approach involves analyzing agent movements through three primary tasks: trajectory prediction, imputation, and spatial-temporal recovery. Considering the unique input formulation and constraint of these tasks, most existing methods are tailored to address only one specific task. However, in real-world applications, these scenarios frequently occur simultaneously. Consequently, methods designed for one task often fail to adapt to others, resulting in performance drops. To overcome this limitation, we propose a Unified Trajectory Generation model, UniTraj, that processes arbitrary trajectories as masked inputs, adaptable to diverse scenarios. Specifically, we introduce a Ghost Spatial Masking (GSM) module embedded within a Transformer encoder for spatial feature extraction. We further extend recent successful State Space Models (SSMs), particularly the Mamba model, into a Bidirectional Temporal Mamba to effectively capture temporal dependencies. Additionally, we incorporate a Bidirectional Temporal Scaled (BTS) module to comprehensively scan trajectories while maintaining the temporal missing relationships within the sequence. We curate and benchmark three practical sports game datasets, Basketball-U, Football-U, and Soccer-U, for evaluation. Extensive experiments demonstrate the superior performance of our model. To the best of our knowledge, this is the first work that addresses this unified problem through a versatile generative framework, thereby enhancing our understanding of multi-agent movement. Our datasets, code, and model weights are available at https://github.com/colorfulfuture/UniTraj-pytorch.
5/29/2024
👀
Exploring Vision Transformers for 3D Human Motion-Language Models with Motion Patches
Qing Yu, Mikihiro Tanaka, Kent Fujiwara
0
0
To build a cross-modal latent space between 3D human motion and language, acquiring large-scale and high-quality human motion data is crucial. However, unlike the abundance of image data, the scarcity of motion data has limited the performance of existing motion-language models. To counter this, we introduce motion patches, a new representation of motion sequences, and propose using Vision Transformers (ViT) as motion encoders via transfer learning, aiming to extract useful knowledge from the image domain and apply it to the motion domain. These motion patches, created by dividing and sorting skeleton joints based on body parts in motion sequences, are robust to varying skeleton structures, and can be regarded as color image patches in ViT. We find that transfer learning with pre-trained weights of ViT obtained through training with 2D image data can boost the performance of motion analysis, presenting a promising direction for addressing the issue of limited motion data. Our extensive experiments show that the proposed motion patches, used jointly with ViT, achieve state-of-the-art performance in the benchmarks of text-to-motion retrieval, and other novel challenging tasks, such as cross-skeleton recognition, zero-shot motion classification, and human interaction recognition, which are currently impeded by the lack of data.
5/9/2024
🛠️
Semi-supervised 2D Human Pose Estimation via Adaptive Keypoint Masking
Kexin Meng, Ruirui Li, Daguang Jiang
0
0
Human pose estimation is a fundamental and challenging task in computer vision. Larger-scale and more accurate keypoint annotations, while helpful for improving the accuracy of supervised pose estimation, are often expensive and difficult to obtain. Semi-supervised pose estimation tries to leverage a large amount of unlabeled data to improve model performance, which can alleviate the problem of insufficient labeled samples. The latest semi-supervised learning usually adopts a strong and weak data augmented teacher-student learning framework to deal with the challenge of Human postural diversity and its long-tailed distribution. Appropriate data augmentation method is one of the key factors affecting the accuracy and generalization of semi-supervised models. Aiming at the problem that the difference of sample learning is not considered in the fixed keypoint masking augmentation method, this paper proposes an adaptive keypoint masking method, which can fully mine the information in the samples and obtain better estimation performance. In order to further improve the generalization and robustness of the model, this paper proposes a dual-branch data augmentation scheme, which can perform Mixup on samples and features on the basis of adaptive keypoint masking. The effectiveness of the proposed method is verified on COCO and MPII, outperforming the state-of-the-art semi-supervised pose estimation by 5.2% and 0.3%, respectively.
4/24/2024