A Sober Look at LLMs for Material Discovery: Are They Actually Good for Bayesian Optimization Over Molecules?

0
🛠️
Sign in to get full access
Overview
- Automation is crucial for discovering new materials.
- Bayesian optimization (BO) is a key part of this process, allowing scientists to efficiently explore a large molecular space using their prior knowledge.
- While large language models (LLMs) have been explored for heuristic materials searches, their usefulness for accelerating principled BO in the molecular space is still an open question.
Plain English Explanation
Discovering new materials is crucial for technological progress, and automation is a key part of this process. Bayesian optimization (BO) is an essential technique that helps scientists explore a vast number of potential molecules efficiently by leveraging their prior knowledge about the problem.
Recently, there has been a lot of excitement around using large language models (LLMs) to assist in materials discovery. LLMs are powerful AI models that can process and generate human-like text, and they may contain valuable scientific knowledge that could be useful for BO. However, existing work has only explored using LLMs for basic materials searches, not for the more principled BO approach.
In this paper, the researchers investigate whether LLMs can truly be useful for accelerating BO in the molecular space. They take a careful, unbiased look at this question, exploring different ways of incorporating LLMs into BO models and testing them on real-world chemistry problems.
Technical Explanation
The researchers in this paper study the potential of using large language models (LLMs) to accelerate principled Bayesian optimization (BO) in the molecular space. While previous work has explored using LLMs for heuristic materials searches, the authors note that these approaches have not leveraged the full power of BO, which relies on accurate uncertainty estimates.
To address this, the researchers take two key steps:
- They view LLMs as fixed feature extractors for standard BO surrogate models, rather than using them directly for heuristic searches.
- They leverage parameter-efficient finetuning methods and Bayesian neural networks to obtain the posterior of the LLM surrogate, which is crucial for BO.
The researchers extensively test their approach on real-world chemistry problems and find that LLMs can be useful for BO over molecules, but only if they have been pretrained or finetuned on domain-specific data. This suggests that the general scientific knowledge captured in LLMs may need to be tailored to the specific materials domain to be truly beneficial for principled BO.
Critical Analysis
The researchers in this paper take a thoughtful and rigorous approach to evaluating the usefulness of LLMs for accelerating Bayesian optimization in the molecular space. They acknowledge the limitations of previous work, which has only explored LLMs for heuristic materials searches, and aim to investigate whether these models can be effectively incorporated into more principled BO frameworks.
One potential concern raised in the paper is the need for domain-specific pretraining or finetuning of the LLMs in order for them to be useful for BO. This suggests that the general scientific knowledge captured in LLMs may not be directly applicable to materials discovery, and that significant effort may be required to adapt these models to the specifics of the chemistry domain.
Additionally, the paper does not explore the potential limitations or biases of the BO framework itself, which could also impact the effectiveness of LLM-powered BO. It would be valuable to see further research that considers the interplay between the BO approach, the data used to train the models, and the biases or inaccuracies that could arise from the LLM components.
Overall, this paper provides a valuable contribution to the ongoing discussion around the role of large language models in scientific discovery and automation. By taking a balanced and thoughtful approach, the researchers have shed light on the nuances and challenges involved in effectively leveraging LLMs for principled Bayesian optimization in the molecular space.
Conclusion
This paper explores the potential of using large language models (LLMs) to accelerate principled Bayesian optimization (BO) in the molecular space. The researchers take a careful, dispassionate approach, viewing LLMs as fixed feature extractors for standard BO surrogate models and leveraging parameter-efficient finetuning methods and Bayesian neural networks to obtain the posterior of the LLM surrogate.
The researchers' extensive experiments on real-world chemistry problems show that LLMs can be useful for BO over molecules, but only if they have been pretrained or finetuned with domain-specific data. This suggests that the general scientific knowledge captured in LLMs may need to be tailored to the specific materials domain to be truly beneficial for principled BO.
The paper's critical analysis highlights the need for further research to consider the limitations and biases of both the BO framework and the LLM components. By taking a balanced and thoughtful approach, this work contributes valuable insights to the ongoing discussion around the role of large language models in scientific discovery and automation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
A Sober Look at LLMs for Material Discovery: Are They Actually Good for Bayesian Optimization Over Molecules?
Agustinus Kristiadi, Felix Strieth-Kalthoff, Marta Skreta, Pascal Poupart, Al'an Aspuru-Guzik, Geoff Pleiss
Automation is one of the cornerstones of contemporary material discovery. Bayesian optimization (BO) is an essential part of such workflows, enabling scientists to leverage prior domain knowledge into efficient exploration of a large molecular space. While such prior knowledge can take many forms, there has been significant fanfare around the ancillary scientific knowledge encapsulated in large language models (LLMs). However, existing work thus far has only explored LLMs for heuristic materials searches. Indeed, recent work obtains the uncertainty estimate -- an integral part of BO -- from point-estimated, non-Bayesian LLMs. In this work, we study the question of whether LLMs are actually useful to accelerate principled Bayesian optimization in the molecular space. We take a sober, dispassionate stance in answering this question. This is done by carefully (i) viewing LLMs as fixed feature extractors for standard but principled BO surrogate models and by (ii) leveraging parameter-efficient finetuning methods and Bayesian neural networks to obtain the posterior of the LLM surrogate. Our extensive experiments with real-world chemistry problems show that LLMs can be useful for BO over molecules, but only if they have been pretrained or finetuned with domain-specific data.
Read more5/30/2024

0
Are LLMs Ready for Real-World Materials Discovery?
Santiago Miret, N M Anoop Krishnan
Large Language Models (LLMs) create exciting possibilities for powerful language processing tools to accelerate research in materials science. While LLMs have great potential to accelerate materials understanding and discovery, they currently fall short in being practical materials science tools. In this position paper, we show relevant failure cases of LLMs in materials science that reveal current limitations of LLMs related to comprehending and reasoning over complex, interconnected materials science knowledge. Given those shortcomings, we outline a framework for developing Materials Science LLMs (MatSci-LLMs) that are grounded in materials science knowledge and hypothesis generation followed by hypothesis testing. The path to attaining performant MatSci-LLMs rests in large part on building high-quality, multi-modal datasets sourced from scientific literature where various information extraction challenges persist. As such, we describe key materials science information extraction challenges which need to be overcome in order to build large-scale, multi-modal datasets that capture valuable materials science knowledge. Finally, we outline a roadmap for applying future MatSci-LLMs for real-world materials discovery via: 1. Automated Knowledge Base Generation; 2. Automated In-Silico Material Design; and 3. MatSci-LLM Integrated Self-Driving Materials Laboratories.
Read more9/26/2024
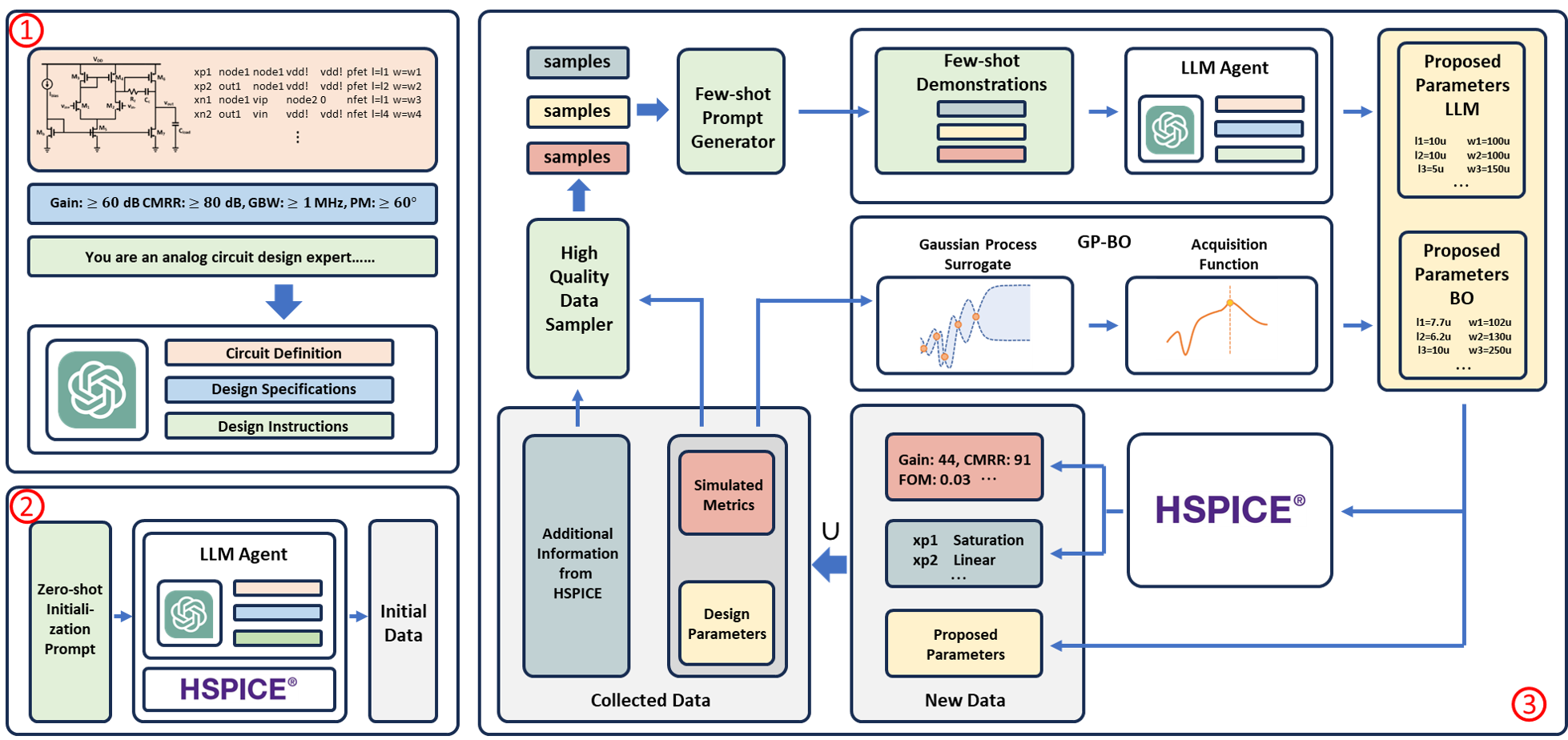
0
ADO-LLM: Analog Design Bayesian Optimization with In-Context Learning of Large Language Models
Yuxuan Yin, Yu Wang, Boxun Xu, Peng Li
Analog circuit design requires substantial human expertise and involvement, which is a significant roadblock to design productivity. Bayesian Optimization (BO), a popular machine learning based optimization strategy, has been leveraged to automate analog design given its applicability across various circuit topologies and technologies. Traditional BO methods employ black box Gaussian Process surrogate models and optimized labeled data queries to find optimization solutions by trading off between exploration and exploitation. However, the search for the optimal design solution in BO can be expensive from both a computational and data usage point of view, particularly for high dimensional optimization problems. This paper presents ADO-LLM, the first work integrating large language models (LLMs) with Bayesian Optimization for analog design optimization. ADO-LLM leverages the LLM's ability to infuse domain knowledge to rapidly generate viable design points to remedy BO's inefficiency in finding high value design areas specifically under the limited design space coverage of the BO's probabilistic surrogate model. In the meantime, sampling of design points evaluated in the iterative BO process provides quality demonstrations for the LLM to generate high quality design points while leveraging infused broad design knowledge. Furthermore, the diversity brought by BO's exploration enriches the contextual understanding of the LLM and allows it to more broadly search in the design space and prevent repetitive and redundant suggestions. We evaluate the proposed framework on two different types of analog circuits and demonstrate notable improvements in design efficiency and effectiveness.
Read more6/28/2024

0
Diagnosing and fixing common problems in Bayesian optimization for molecule design
Austin Tripp, Jos'e Miguel Hern'andez-Lobato
Bayesian optimization (BO) is a principled approach to molecular design tasks. In this paper we explain three pitfalls of BO which can cause poor empirical performance: an incorrect prior width, over-smoothing, and inadequate acquisition function maximization. We show that with these issues addressed, even a basic BO setup is able to achieve the highest overall performance on the PMO benchmark for molecule design (Gao et al 2022). These results suggest that BO may benefit from more attention in the machine learning for molecules community.
Read more7/26/2024