Diagnosing and fixing common problems in Bayesian optimization for molecule design

0

Sign in to get full access
Overview
- This paper discusses common problems encountered when using Bayesian optimization for molecule design and proposes solutions to address them.
- Bayesian optimization is a powerful technique for efficiently exploring high-dimensional search spaces, but it can face challenges like noisy or unreliable objective functions, limited data, and lack of domain knowledge.
- The authors provide a comprehensive review of these issues and offer practical guidance on how to diagnose and mitigate them.
Plain English Explanation
Bayesian optimization is a machine learning technique used to find the best design or configuration for something, like a new drug molecule. It works by building a mathematical model of the problem, then systematically testing different options to find the one that performs the best.
However, Bayesian optimization can encounter some common issues when applied to real-world problems like molecule design. For example, the objective function (the measure of how "good" a molecule is) might be noisy or unreliable, meaning it's hard to tell if a molecule is truly better than another. Or there might not be enough data on existing molecules to build an accurate model. And researchers may lack deep knowledge about the chemistry domain, making it difficult to guide the optimization process.
This paper explores these common problems in depth and offers practical advice on how to diagnose and overcome them. The authors draw on their own experience using Bayesian optimization for molecule design, as well as insights from the broader machine learning literature. Their goal is to help other researchers and practitioners use this powerful technique more effectively, even in challenging real-world scenarios.
Technical Explanation
The paper first provides a background on Bayesian optimization, explaining how it works by building a probabilistic model of the objective function and using that to intelligently explore the search space. It then dives into several key challenges that can arise:
-
Noisy or unreliable objective functions: When the output of the objective function (e.g., a molecule's predicted activity) has high variance or is biased, it becomes difficult for the Bayesian optimizer to reliably distinguish good molecules from bad ones. The authors discuss techniques like adding extra noise modeling, using control variates, and incorporating domain knowledge to address this.
-
Limited data: Bayesian optimization relies on building an accurate model of the objective function, but in many real-world settings (like early-stage drug discovery), there is limited data available on existing molecules. The authors explore ways to leverage transfer learning, active learning, and other strategies to make the most of small datasets.
-
Lack of domain knowledge: Effective Bayesian optimization often requires deep understanding of the problem domain (e.g., chemistry, materials science) to guide the search. The authors propose methods for incorporating prior knowledge, such as using informative kernel functions or physically-inspired features, to steer the optimization in more productive directions.
Throughout the paper, the authors illustrate these concepts and solutions with examples from their own work on Bayesian optimization for molecular design. They also provide guidance on practical matters like hyperparameter tuning and model evaluation.
Critical Analysis
The paper provides a valuable and comprehensive guide to common issues in Bayesian optimization for molecule design, drawing on the authors' extensive experience in this area. The proposed solutions are well-grounded in machine learning theory and seem promising for addressing real-world challenges.
That said, the authors acknowledge that Bayesian optimization still has limitations, particularly in dealing with highly complex or multimodal objective functions. They also note that the effectiveness of their techniques will depend on the specific problem and dataset at hand. More research may be needed to fully understand the tradeoffs and generalize the approaches to a wider range of molecular design tasks.
Additionally, while the paper focuses on Bayesian optimization, many of the issues it discusses (like noisy data and lack of domain knowledge) are common across various machine learning approaches to molecular design. Readers may want to explore complementary research on using other techniques, such as meta-learning or preferential Bayesian optimization, to address these broader challenges.
Conclusion
This paper provides a thorough and practical guide to diagnosing and overcoming common issues in using Bayesian optimization for molecular design. By carefully addressing challenges like noisy data, limited samples, and lack of domain knowledge, the authors demonstrate how this powerful technique can be applied more effectively in real-world scenarios.
Their solutions draw on a range of machine learning and domain-specific strategies, offering a toolbox for researchers and practitioners to better leverage Bayesian optimization in early-stage drug discovery, materials science, and other areas of computational chemistry. As the field continues to evolve, this work can help guide future advancements in the use of Bayesian optimization for complex molecular design problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diagnosing and fixing common problems in Bayesian optimization for molecule design
Austin Tripp, Jos'e Miguel Hern'andez-Lobato
Bayesian optimization (BO) is a principled approach to molecular design tasks. In this paper we explain three pitfalls of BO which can cause poor empirical performance: an incorrect prior width, over-smoothing, and inadequate acquisition function maximization. We show that with these issues addressed, even a basic BO setup is able to achieve the highest overall performance on the PMO benchmark for molecule design (Gao et al 2022). These results suggest that BO may benefit from more attention in the machine learning for molecules community.
Read more7/26/2024
0
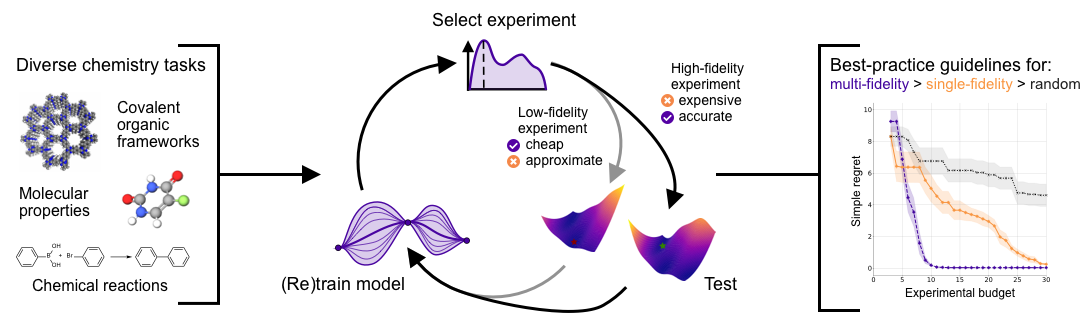
New!Best Practices for Multi-Fidelity Bayesian Optimization in Materials and Molecular Research
V'ictor Sabanza-Gil, Riccardo Barbano, Daniel Pacheco Guti'errez, Jeremy S. Luterbacher, Jos'e Miguel Hern'andez-Lobato, Philippe Schwaller, Loic Roch
Multi-fidelity Bayesian Optimization (MFBO) is a promising framework to speed up materials and molecular discovery as sources of information of different accuracies are at hand at increasing cost. Despite its potential use in chemical tasks, there is a lack of systematic evaluation of the many parameters playing a role in MFBO. In this work, we provide guidelines and recommendations to decide when to use MFBO in experimental settings. We investigate MFBO methods applied to molecules and materials problems. First, we test two different families of acquisition functions in two synthetic problems and study the effect of the informativeness and cost of the approximate function. We use our implementation and guidelines to benchmark three real discovery problems and compare them against their single-fidelity counterparts. Our results may help guide future efforts to implement MFBO as a routine tool in the chemical sciences.
Read more10/2/2024

0
Applying Multi-Fidelity Bayesian Optimization in Chemistry: Open Challenges and Major Considerations
Edmund Judge, Mohammed Azzouzi, Austin M. Mroz, Antonio del Rio Chanona, Kim E. Jelfs
Multi fidelity Bayesian optimization (MFBO) leverages experimental and or computational data of varying quality and resource cost to optimize towards desired maxima cost effectively. This approach is particularly attractive for chemical discovery due to MFBO's ability to integrate diverse data sources. Here, we investigate the application of MFBO to accelerate the identification of promising molecules or materials. We specifically analyze the conditions under which lower fidelity data can enhance performance compared to single-fidelity problem formulations. We address two key challenges, selecting the optimal acquisition function, understanding the impact of cost, and data fidelity correlation. We then discuss how to assess the effectiveness of MFBO for chemical discovery.
Read more9/12/2024
🧠
0
Large-Batch, Iteration-Efficient Neural Bayesian Design Optimization
Navid Ansari, Alireza Javanmardi, Eyke Hullermeier, Hans-Peter Seidel, Vahid Babaei
Bayesian optimization (BO) provides a powerful framework for optimizing black-box, expensive-to-evaluate functions. It is therefore an attractive tool for engineering design problems, typically involving multiple objectives. Thanks to the rapid advances in fabrication and measurement methods as well as parallel computing infrastructure, querying many design problems can be heavily parallelized. This class of problems challenges BO with an unprecedented setup where it has to deal with very large batches, shifting its focus from sample efficiency to iteration efficiency. We present a novel Bayesian optimization framework specifically tailored to address these limitations. Our key contribution is a highly scalable, sample-based acquisition function that performs a non-dominated sorting of not only the objectives but also their associated uncertainty. We show that our acquisition function in combination with different Bayesian neural network surrogates is effective in data-intensive environments with a minimal number of iterations. We demonstrate the superiority of our method by comparing it with state-of-the-art multi-objective optimizations. We perform our evaluation on two real-world problems -- airfoil design and 3D printing -- showcasing the applicability and efficiency of our approach. Our code is available at: https://github.com/an-on-ym-ous/lbn_mobo
Read more9/6/2024