SoK: Unintended Interactions among Machine Learning Defenses and Risks
2312.04542
0
0
Abstract
Machine learning (ML) models cannot neglect risks to security, privacy, and fairness. Several defenses have been proposed to mitigate such risks. When a defense is effective in mitigating one risk, it may correspond to increased or decreased susceptibility to other risks. Existing research lacks an effective framework to recognize and explain these unintended interactions. We present such a framework, based on the conjecture that overfitting and memorization underlie unintended interactions. We survey existing literature on unintended interactions, accommodating them within our framework. We use our framework to conjecture on two previously unexplored interactions, and empirically validate our conjectures.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper provides a systematic exploration of unintended interactions between machine learning defenses and risks.
- The authors analyze how defenses against one type of attack can inadvertently introduce new vulnerabilities or exacerbate other risks.
- The paper examines a range of machine learning models, defenses, and potential attacks, highlighting the complex interplay between security measures and emerging threats.
Plain English Explanation
The paper looks at how different techniques used to protect machine learning models from attacks can sometimes have unintended consequences. The researchers found that defenses against one type of attack can actually create new vulnerabilities or make other problems worse.
They studied a variety of machine learning models, security measures, and possible attacks. The key insight is that the relationships between these different elements are complex. Trying to solve one issue with a defense can end up causing other issues that weren't anticipated.
For example, a defense designed to protect against model extraction attacks might inadvertently make the model more vulnerable to adversarial attacks. Or a technique meant to improve the robustness of a model could end up reducing its capabilities in other areas. The researchers wanted to map out these complex interactions to help ML developers understand the tradeoffs and potential unintended consequences of the security measures they implement.
Technical Explanation
The paper systematically explores the unintended interactions that can arise between machine learning defenses and the risks they are intended to mitigate. The authors analyze how defenses against one type of attack can inadvertently introduce new vulnerabilities or exacerbate other risks.
The researchers examined a range of machine learning models, defenses, and potential attacks, including model extraction, adversarial attacks, membership inference, and model inversion. They identified several key interaction patterns, such as how defenses against model extraction attacks can increase a model's vulnerability to adversarial examples, or how techniques to improve model robustness can reduce a model's capabilities in other areas.
Through this analysis, the authors aimed to provide a more comprehensive understanding of the complex relationships between security measures and emerging threats in machine learning systems. By mapping out these unintended interactions, the paper highlights the importance of considering the broader ecosystem of risks and defenses when designing and deploying machine learning models.
Critical Analysis
The paper offers a valuable systematic exploration of the unintended consequences that can arise from machine learning defenses. The authors acknowledge several limitations and directions for future research, such as the need to study a wider range of model architectures, defenses, and attack vectors.
One potential area for further investigation is the role of transparency and interpretability in mitigating unintended interactions. The paper suggests that increased model transparency could help developers better understand the tradeoffs and potential issues introduced by security measures. Techniques like explainable AI may be worth exploring in this context.
Additionally, the authors note the need for more comprehensive testing and evaluation frameworks to assess the broader impact of machine learning defenses. Current security evaluation often focuses on specific attack scenarios, but the paper highlights the importance of considering the complex interplay between different risks and countermeasures.
Overall, this work represents an important step in advancing our understanding of the challenges and nuances involved in securing machine learning systems. By shedding light on unintended interactions, the paper encourages a more holistic and proactive approach to machine learning security.
Conclusion
This paper provides a systematic analysis of the unintended interactions that can arise between machine learning defenses and the risks they are intended to mitigate. The authors demonstrate how security measures designed to protect against one type of attack can inadvertently introduce new vulnerabilities or exacerbate other threats.
By examining a range of machine learning models, defenses, and potential attacks, the paper highlights the complex and interconnected nature of security considerations in this domain. The insights from this work underscore the importance of taking a comprehensive and proactive approach to machine learning security, one that considers the broader ecosystem of risks and defenses.
As machine learning systems become more widely deployed, understanding and addressing these unintended interactions will be crucial for ensuring the safety, reliability, and trustworthiness of these technologies. This paper lays an important foundation for further research and development in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
From Attack to Defense: Insights into Deep Learning Security Measures in Black-Box Settings
Firuz Juraev, Mohammed Abuhamad, Eric Chan-Tin, George K. Thiruvathukal, Tamer Abuhmed
0
0
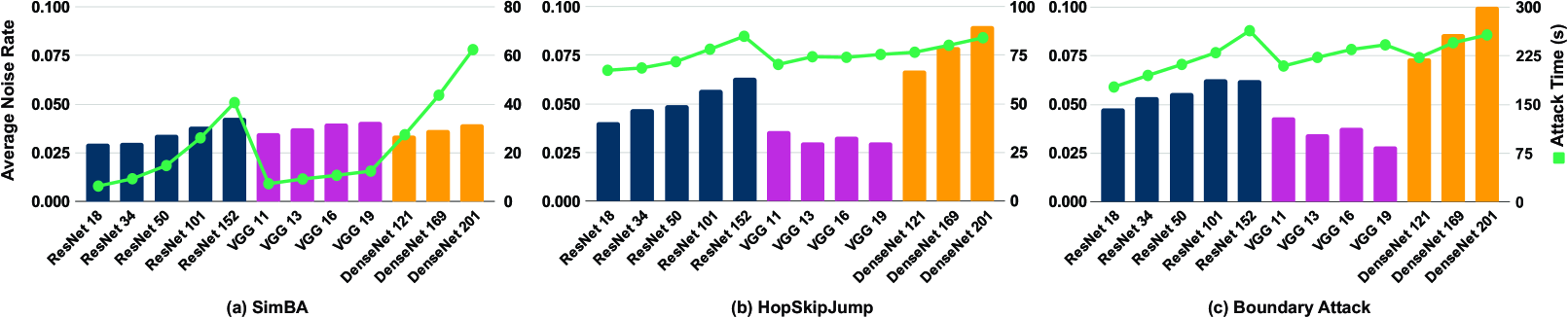
Deep Learning (DL) is rapidly maturing to the point that it can be used in safety- and security-crucial applications. However, adversarial samples, which are undetectable to the human eye, pose a serious threat that can cause the model to misbehave and compromise the performance of such applications. Addressing the robustness of DL models has become crucial to understanding and defending against adversarial attacks. In this study, we perform comprehensive experiments to examine the effect of adversarial attacks and defenses on various model architectures across well-known datasets. Our research focuses on black-box attacks such as SimBA, HopSkipJump, MGAAttack, and boundary attacks, as well as preprocessor-based defensive mechanisms, including bits squeezing, median smoothing, and JPEG filter. Experimenting with various models, our results demonstrate that the level of noise needed for the attack increases as the number of layers increases. Moreover, the attack success rate decreases as the number of layers increases. This indicates that model complexity and robustness have a significant relationship. Investigating the diversity and robustness relationship, our experiments with diverse models show that having a large number of parameters does not imply higher robustness. Our experiments extend to show the effects of the training dataset on model robustness. Using various datasets such as ImageNet-1000, CIFAR-100, and CIFAR-10 are used to evaluate the black-box attacks. Considering the multiple dimensions of our analysis, e.g., model complexity and training dataset, we examined the behavior of black-box attacks when models apply defenses. Our results show that applying defense strategies can significantly reduce attack effectiveness. This research provides in-depth analysis and insight into the robustness of DL models against various attacks, and defenses.
5/6/2024
🎯
Evaluations of Machine Learning Privacy Defenses are Misleading
Michael Aerni, Jie Zhang, Florian Tram`er
0
0
Empirical defenses for machine learning privacy forgo the provable guarantees of differential privacy in the hope of achieving higher utility while resisting realistic adversaries. We identify severe pitfalls in existing empirical privacy evaluations (based on membership inference attacks) that result in misleading conclusions. In particular, we show that prior evaluations fail to characterize the privacy leakage of the most vulnerable samples, use weak attacks, and avoid comparisons with practical differential privacy baselines. In 5 case studies of empirical privacy defenses, we find that prior evaluations underestimate privacy leakage by an order of magnitude. Under our stronger evaluation, none of the empirical defenses we study are competitive with a properly tuned, high-utility DP-SGD baseline (with vacuous provable guarantees).
4/29/2024
🧪
Systematically Assessing the Security Risks of AI/ML-enabled Connected Healthcare Systems
Mohammed Elnawawy, Mohammadreza Hallajiyan, Gargi Mitra, Shahrear Iqbal, Karthik Pattabiraman
0
0
The adoption of machine-learning-enabled systems in the healthcare domain is on the rise. While the use of ML in healthcare has several benefits, it also expands the threat surface of medical systems. We show that the use of ML in medical systems, particularly connected systems that involve interfacing the ML engine with multiple peripheral devices, has security risks that might cause life-threatening damage to a patient's health in case of adversarial interventions. These new risks arise due to security vulnerabilities in the peripheral devices and communication channels. We present a case study where we demonstrate an attack on an ML-enabled blood glucose monitoring system by introducing adversarial data points during inference. We show that an adversary can achieve this by exploiting a known vulnerability in the Bluetooth communication channel connecting the glucose meter with the ML-enabled app. We further show that state-of-the-art risk assessment techniques are not adequate for identifying and assessing these new risks. Our study highlights the need for novel risk analysis methods for analyzing the security of AI-enabled connected health devices.
4/15/2024
An Investigation into the Performances of the State-of-the-art Machine Learning Approaches for Various Cyber-attack Detection: A Survey
Tosin Ige, Christopher Kiekintveld, Aritran Piplai
0
0
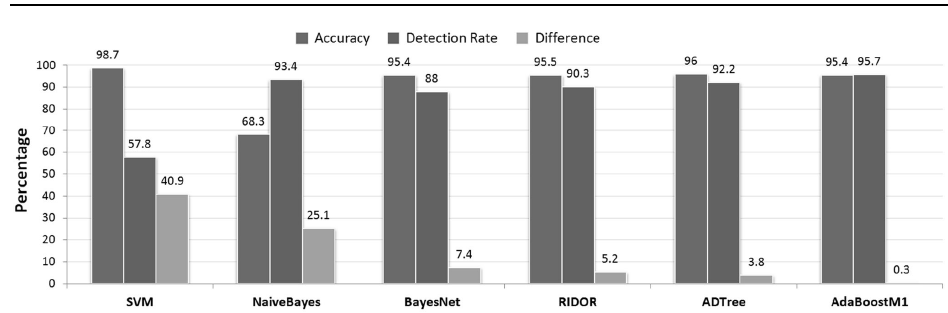
In this research, we analyzed the suitability of each of the current state-of-the-art machine learning models for various cyberattack detection from the past 5 years with a major emphasis on the most recent works for comparative study to identify the knowledge gap where work is still needed to be done with regard to detection of each category of cyberattack. We also reviewed the suitability, effeciency and limitations of recent research on state-of-the-art classifiers and novel frameworks in the detection of differnet cyberattacks. Our result shows the need for; further research and exploration on machine learning approach for the detection of drive-by download attacks, an investigation into the mix performance of Naive Bayes to identify possible research direction on improvement to existing state-of-the-art Naive Bayes classifier, we also identify that current machine learning approach to the detection of SQLi attack cannot detect an already compromised database with SQLi attack signifying another possible future research direction.
5/13/2024