The #Somos600M Project: Generating NLP resources that represent the diversity of the languages from LATAM, the Caribbean, and Spain

0

Sign in to get full access
Overview
- The #Somos600M project aims to generate NLP resources that represent the diversity of languages from Latin America, the Caribbean, and Spain.
- The project focuses on creating multilingual datasets and models to support NLP tasks for underrepresented languages in these regions.
- The paper presents the project's approach and initial results in building these NLP resources.
Plain English Explanation
The #Somos600M Project is an effort to improve natural language processing (NLP) capabilities for languages spoken in Latin America, the Caribbean, and Spain. These languages are often underrepresented in existing NLP datasets and models, which can limit the development of useful technologies for these regions.
The project's goal is to create new multilingual datasets and machine learning models that better reflect the linguistic diversity of these areas. By generating more representative NLP resources, the researchers aim to enable the development of applications and services that work well for a wider range of speakers and dialects.
Some key aspects of the project include:
- Identifying and collecting data from a diverse set of languages in the target regions
- Developing datasets and models for tasks like text classification, machine translation, and conversational AI
- Collaborating with local communities to ensure the resources accurately represent their languages and needs
Overall, the #Somos600M Project is an important step toward making NLP more inclusive and accessible for underserved populations around the world.
Technical Explanation
The #Somos600M Project is focused on creating natural language processing (NLP) resources that better capture the linguistic diversity of Latin America, the Caribbean, and Spain.
The researchers first conducted a survey to identify the most widely spoken languages in these regions, including both official and minority languages. They then set out to collect textual data in these languages from a variety of online sources, such as news articles, social media posts, and online forums.
Using this data, the team has begun developing multilingual datasets and models for key NLP tasks like text classification, machine translation, and conversational AI. For example, they have created a multilingual dataset called Tagengo that covers over 100 languages spoken in Latin America and the Caribbean.
The researchers are also exploring techniques to make their NLP models more robust to linguistic variation, such as incorporating code-switching and dialectal features. Additionally, they are working to ensure the resources they create accurately represent the languages and cultures of the target regions by collaborating with local experts and community members.
Critical Analysis
The #Somos600M Project addresses an important gap in the NLP field by focusing on underrepresented languages from Latin America, the Caribbean, and Spain. By creating more diverse datasets and models, the project has the potential to make NLP technologies more accessible and useful for a wider range of users in these regions.
However, the researchers acknowledge that building comprehensive NLP resources for such a large and linguistically diverse set of languages is an immense challenge. They note that data collection and annotation can be time-consuming and resource-intensive, especially for minority languages with limited online presence.
Additionally, the team highlights the need to carefully consider issues of bias, fairness, and privacy when working with real-world data from social media and other online sources. Addressing these concerns will be critical to ensuring the project's resources are developed and deployed responsibly.
Moving forward, the researchers plan to continue expanding their dataset and model development efforts, while also exploring ways to better incorporate community feedback and oversight. Ongoing collaborations with local experts and organizations will be key to ensuring the project's outputs truly meet the needs of the target populations.
Conclusion
The #Somos600M Project represents an important step toward making natural language processing more inclusive and representative of the world's linguistic diversity. By focusing on underserved regions like Latin America, the Caribbean, and Spain, the project aims to create NLP resources that can enable the development of more accessible and culturally-relevant technologies for these populations.
While the challenges of this undertaking are substantial, the project's initial progress and collaborative approach suggest it has the potential to make a meaningful impact. As the researchers continue to build out their datasets and models, their work could pave the way for a more equitable and inclusive future for natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The #Somos600M Project: Generating NLP resources that represent the diversity of the languages from LATAM, the Caribbean, and Spain
Mar'ia Grandury
We are 600 million Spanish speakers. We launched the #Somos600M Project because the diversity of the languages from LATAM, the Caribbean and Spain needs to be represented in Artificial Intelligence (AI) systems. Despite being the 7.5% of the world population, there is no open dataset to instruction-tune large language models (LLMs), nor a leaderboard to evaluate and compare them. In this paper, we present how we have created as an international open-source community the first versions of the instruction and evaluation datasets, indispensable resources for the advancement of Natural Language Processing (NLP) in our languages.
Read more7/26/2024

0
Open Generative Large Language Models for Galician
Pablo Gamallo, Pablo Rodr'iguez, Iria de-Dios-Flores, Susana Sotelo, Silvia Paniagua, Daniel Bardanca, Jos'e Ramom Pichel, Marcos Garcia
Large language models (LLMs) have transformed natural language processing. Yet, their predominantly English-centric training has led to biases and performance disparities across languages. This imbalance marginalizes minoritized languages, making equitable access to NLP technologies more difficult for languages with lower resources, such as Galician. We present the first two generative LLMs focused on Galician to bridge this gap. These models, freely available as open-source resources, were trained using a GPT architecture with 1.3B parameters on a corpus of 2.1B words. Leveraging continual pretraining, we adapt to Galician two existing LLMs trained on larger corpora, thus mitigating the data constraints that would arise if the training were performed from scratch. The models were evaluated using human judgments and task-based datasets from standardized benchmarks. These evaluations reveal a promising performance, underscoring the importance of linguistic diversity in generative models.
Read more6/21/2024
🖼️
0
Tagengo: A Multilingual Chat Dataset
Peter Devine
Open source large language models (LLMs) have shown great improvements in recent times. However, many of these models are focused solely on popular spoken languages. We present a high quality dataset of more than 70k prompt-response pairs in 74 languages which consist of human generated prompts and synthetic responses. We use this dataset to train a state-of-the-art open source English LLM to chat multilingually. We evaluate our model on MT-Bench chat benchmarks in 6 languages, finding that our multilingual model outperforms previous state-of-the-art open source LLMs across each language. We further find that training on more multilingual data is beneficial to the performance in a chosen target language (Japanese) compared to simply training on only data in that language. These results indicate the necessity of training on large amounts of high quality multilingual data to make a more accessible LLM.
Read more5/22/2024
0
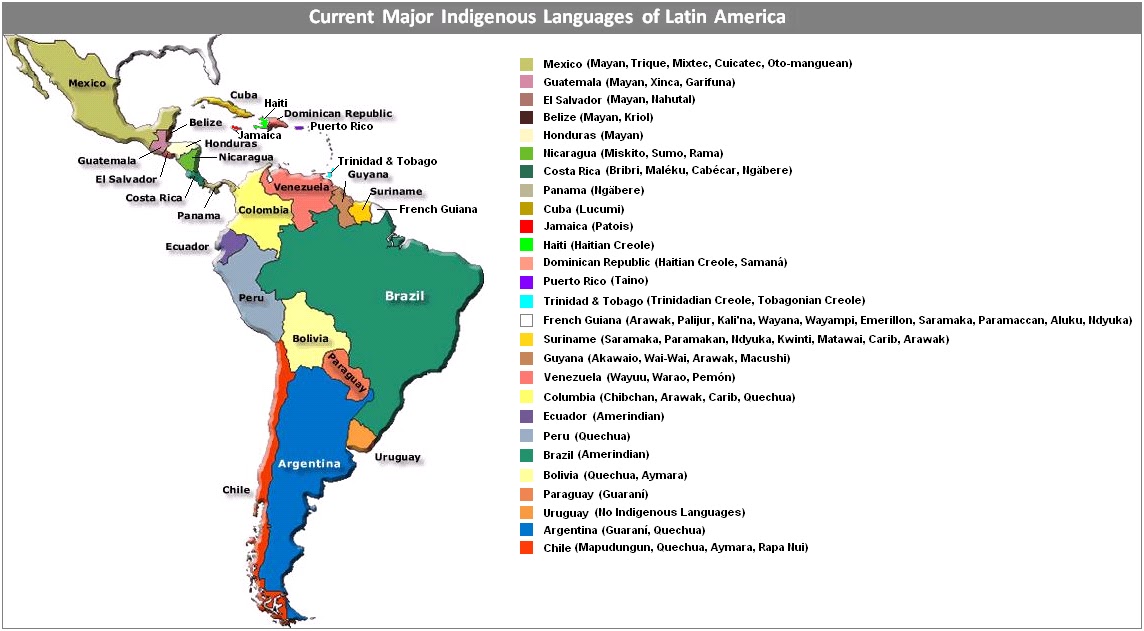
NLP Progress in Indigenous Latin American Languages
Atnafu Lambebo Tonja, Fazlourrahman Balouchzahi, Sabur Butt, Olga Kolesnikova, Hector Ceballos, Alexander Gelbukh, Thamar Solorio
The paper focuses on the marginalization of indigenous language communities in the face of rapid technological advancements. We highlight the cultural richness of these languages and the risk they face of being overlooked in the realm of Natural Language Processing (NLP). We aim to bridge the gap between these communities and researchers, emphasizing the need for inclusive technological advancements that respect indigenous community perspectives. We show the NLP progress of indigenous Latin American languages and the survey that covers the status of indigenous languages in Latin America, their representation in NLP, and the challenges and innovations required for their preservation and development. The paper contributes to the current literature in understanding the need and progress of NLP for indigenous communities of Latin America, specifically low-resource and indigenous communities in general.
Read more5/14/2024