Tagengo: A Multilingual Chat Dataset
2405.12612
0
0
🖼️
Abstract
Open source large language models (LLMs) have shown great improvements in recent times. However, many of these models are focused solely on popular spoken languages. We present a high quality dataset of more than 70k prompt-response pairs in 74 languages which consist of human generated prompts and synthetic responses. We use this dataset to train a state-of-the-art open source English LLM to chat multilingually. We evaluate our model on MT-Bench chat benchmarks in 6 languages, finding that our multilingual model outperforms previous state-of-the-art open source LLMs across each language. We further find that training on more multilingual data is beneficial to the performance in a chosen target language (Japanese) compared to simply training on only data in that language. These results indicate the necessity of training on large amounts of high quality multilingual data to make a more accessible LLM.
Create account to get full access
Overview
- Researchers have developed a large dataset of over 70,000 multilingual prompt-response pairs across 74 languages.
- They used this dataset to train an open-source English language model to chat in multiple languages.
- Evaluations showed their multilingual model outperformed existing open-source models in 6 languages.
- Training on more diverse multilingual data was more beneficial than training on a single target language.
- These results highlight the importance of building high-quality multilingual datasets to create more accessible large language models (LLMs).
Plain English Explanation
Large language models (LLMs) are AI systems that can understand and generate human-like text. In recent years, open-source LLMs have made great progress, but many are still focused only on popular languages like English.
The researchers in this paper wanted to change that. They created a large dataset of over 70,000 prompts (questions or requests) and responses in 74 different languages. This included many less common languages that are often overlooked.
Using this diverse dataset, the researchers trained an open-source English LLM to be able to converse in multiple languages. When they tested this multilingual model, they found it outperformed previous open-source models in 6 different languages.
Interestingly, the model did better when it was trained on the full multilingual dataset, compared to being trained only on data for a single target language like Japanese. This suggests that exposing LLMs to a wider range of languages can make them more capable, even in a specific target language.
The key takeaway is that building high-quality, multilingual datasets is crucial for developing LLMs that can communicate effectively across many languages. This could make these powerful AI tools more accessible to people around the world.
Technical Explanation
The researchers presented a large dataset of over 70,000 prompt-response pairs in 74 languages that they used to train a multilingual open-source English LLM.
They evaluated this model on chat benchmarks in 6 languages and found it outperformed previous state-of-the-art open-source LLMs across each language. Importantly, they also discovered that training the model on more diverse multilingual data was more beneficial for performance in a target language (Japanese) than training it solely on Japanese data.
These results indicate the necessity of training LLMs on large, high-quality multilingual datasets to improve their accessibility and capabilities across a wide range of languages. The researchers' dataset, called SambaLingo, was built using a novel dynamic data sampling approach to ensure coverage of less common languages.
Additionally, the researchers explored techniques like GentranslaTe and low-resource machine translation to further improve the multilingual capabilities of their LLM.
Critical Analysis
The researchers provide compelling evidence for the value of training LLMs on diverse multilingual datasets. However, there are a few potential limitations and areas for further research:
- The dataset, while large, may still lack representation of many of the world's 7,000+ languages. Expanding the dataset's coverage could further improve the model's abilities.
- The researchers only evaluated the model on relatively common languages like Spanish, French, and Japanese. Testing on a wider range of less-resourced languages would be valuable.
- It's unclear how the model's multilingual capabilities scale as the number of target languages increases. There may be practical limits to how many languages can be effectively supported.
- The impact of this research on real-world accessibility and inclusivity of LLMs is not directly measured. Further user studies would be needed to assess the true benefits.
Overall, this work highlights the importance of prioritizing multilingual development in the LLM research community. Continued progress in this area could make transformative AI technologies more available to diverse global populations.
Conclusion
This research demonstrates the potential of training open-source LLMs on large, high-quality multilingual datasets. By doing so, the researchers were able to create a model that outperformed previous state-of-the-art open-source LLMs across multiple languages.
Significantly, the model performed better when trained on diverse multilingual data compared to being trained solely on a single target language. This suggests that exposing LLMs to a wider range of linguistic diversity can improve their capabilities, even in specific languages.
These findings highlight the importance of prioritizing multilingual development in LLM research. Building more accessible LLMs that can communicate effectively across many languages could have far-reaching benefits for global communities. Further work is needed to expand language coverage and assess real-world impact, but this paper represents an important step forward.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
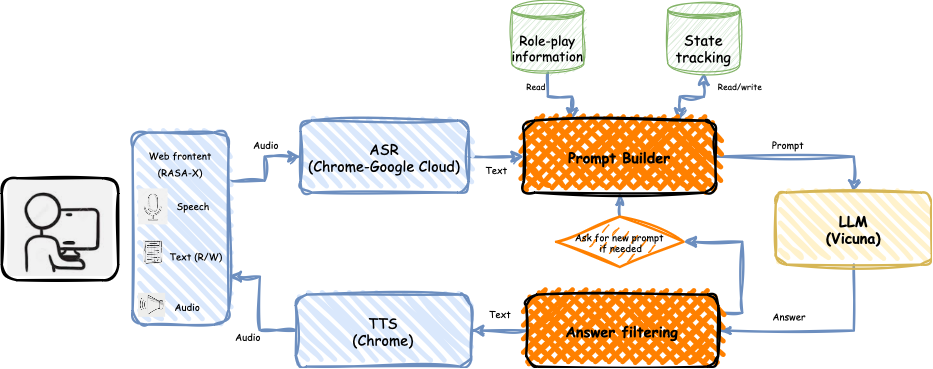
Role-Play Zero-Shot Prompting with Large Language Models for Open-Domain Human-Machine Conversation
Ahmed Njifenjou, Virgile Sucal, Bassam Jabaian, Fabrice Lef`evre
0
0
Recently, various methods have been proposed to create open-domain conversational agents with Large Language Models (LLMs). These models are able to answer user queries, but in a one-way Q&A format rather than a true conversation. Fine-tuning on particular datasets is the usual way to modify their style to increase conversational ability, but this is expensive and usually only available in a few languages. In this study, we explore role-play zero-shot prompting as an efficient and cost-effective solution for open-domain conversation, using capable multilingual LLMs (Beeching et al., 2023) trained to obey instructions. We design a prompting system that, when combined with an instruction-following model - here Vicuna (Chiang et al., 2023) - produces conversational agents that match and even surpass fine-tuned models in human evaluation in French in two different tasks.
6/27/2024

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024
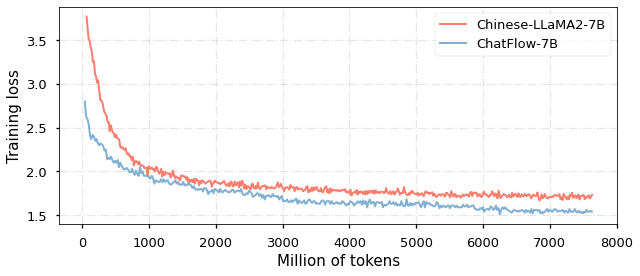
Dynamic data sampler for cross-language transfer learning in large language models
Yudong Li, Yuhao Feng, Wen Zhou, Zhe Zhao, Linlin Shen, Cheng Hou, Xianxu Hou
0
0
Large Language Models (LLMs) have gained significant attention in the field of natural language processing (NLP) due to their wide range of applications. However, training LLMs for languages other than English poses significant challenges, due to the difficulty in acquiring large-scale corpus and the requisite computing resources. In this paper, we propose ChatFlow, a cross-language transfer-based LLM, to address these challenges and train large Chinese language models in a cost-effective manner. We employ a mix of Chinese, English, and parallel corpus to continuously train the LLaMA2 model, aiming to align cross-language representations and facilitate the knowledge transfer specifically to the Chinese language model. In addition, we use a dynamic data sampler to progressively transition the model from unsupervised pre-training to supervised fine-tuning. Experimental results demonstrate that our approach accelerates model convergence and achieves superior performance. We evaluate ChatFlow on popular Chinese and English benchmarks, the results indicate that it outperforms other Chinese models post-trained on LLaMA-2-7B.
5/20/2024

StatBot.Swiss: Bilingual Open Data Exploration in Natural Language
Farhad Nooralahzadeh, Yi Zhang, Ellery Smith, Sabine Maennel, Cyril Matthey-Doret, Raphael de Fondville, Kurt Stockinger
0
0
The potential for improvements brought by Large Language Models (LLMs) in Text-to-SQL systems is mostly assessed on monolingual English datasets. However, LLMs' performance for other languages remains vastly unexplored. In this work, we release the StatBot.Swiss dataset, the first bilingual benchmark for evaluating Text-to-SQL systems based on real-world applications. The StatBot.Swiss dataset contains 455 natural language/SQL-pairs over 35 big databases with varying level of complexity for both English and German. We evaluate the performance of state-of-the-art LLMs such as GPT-3.5-Turbo and mixtral-8x7b-instruct for the Text-to-SQL translation task using an in-context learning approach. Our experimental analysis illustrates that current LLMs struggle to generalize well in generating SQL queries on our novel bilingual dataset.
6/7/2024