SOTOPIA-$pi$: Interactive Learning of Socially Intelligent Language Agents

0
Sign in to get full access
Overview
- Introduces a new interactive learning environment called \trjnfamilySOTOPIA-π for training socially intelligent language agents
- Explores how these agents can learn social skills through interactive learning in a simulated environment
- Presents a novel approach for enabling language agents to learn to be more socially aware and responsive
Plain English Explanation
This paper describes a new interactive learning environment called \trjnfamilySOTOPIA-π that is designed to help train language agents to be more socially intelligent. The key idea is that by placing these agents in a simulated social environment and having them interact with virtual characters, they can learn important social skills like empathy, emotional awareness, and appropriate communication.
The researchers argue that developing socially intelligent language models is crucial for building AI systems that can engage in natural, meaningful interactions with humans. How can large language models enable better interactions and is this real life, is this just are two related papers that explore similar themes.
The \trjnfamilySOTOPIA-π environment aims to provide a rich, dynamic setting where language agents can practice social skills, receive feedback, and iteratively improve their abilities. This interactive, learning-focused approach contrasts with traditional approaches to building socially intelligent AI, which have often relied more on pre-programmed social skills or static datasets.
By grounding the development of social intelligence in interactive learning, the researchers hope to create language agents that are not only knowledgeable, but also socially aware, empathetic, and able to engage in truly natural conversations. This could have important implications for fields like personality-aware student simulation conversational intelligent tutoring, scaling instructable agents across many simulated worlds, and towards objectively benchmarking social intelligence language agents.
Technical Explanation
The \trjnfamilySOTOPIA-π environment is a novel interactive learning platform that aims to enable language agents to develop social intelligence through simulated interactions. The environment includes a diverse cast of virtual characters with distinct personalities, emotions, and communication styles. Language agents are tasked with engaging in conversations and completing social tasks within this simulated world.
The key innovation of \trjnfamilySOTOPIA-π is its focus on interactive learning. Rather than relying on pre-programmed social skills or static datasets, the agents must learn social intelligence through a process of trial-and-error, receiving feedback from the virtual characters they interact with. This feedback is used to iteratively update the agents' language models and social reasoning capabilities.
The researchers describe several technical advancements that enable this interactive learning approach, including novel neural network architectures that allow the agents to model the mental states and communicative intents of their conversational partners. The agents also leverage large language models pre-trained on broad corpora, which provide a strong foundation for social and emotional understanding.
Importantly, the \trjnfamilySOTOPIA-π environment is designed to be a testbed for benchmarking and evaluating the social intelligence of language agents. The researchers have developed a suite of metrics and tasks to objectively measure factors like empathy, emotional awareness, and appropriateness of responses.
Critical Analysis
The \trjnfamilySOTOPIA-π framework represents an innovative approach to developing socially intelligent language agents, but it is not without its limitations and challenges. One key concern is the extent to which the skills learned in the simulated environment will transfer to real-world human interactions, which are far more complex and unpredictable.
Additionally, the reliance on interactive learning raises questions about the scalability and efficiency of the training process. Iteratively updating language models through trial-and-error interactions may be computationally intensive and time-consuming, potentially limiting the practical applicability of this approach.
The researchers acknowledge these limitations and suggest several directions for future work, such as exploring hybrid approaches that combine interactive learning with more traditional training techniques. Scaling instructable agents across many simulated worlds is another relevant paper that delves into the challenges of scaling agent-based simulation approaches.
Overall, the \trjnfamilySOTOPIA-π framework represents a promising step towards more socially aware and responsive language agents. However, further research and development will be needed to fully realize the potential of this approach and address the practical challenges that arise.
Conclusion
This paper introduces \trjnfamilySOTOPIA-π, a novel interactive learning environment designed to enable language agents to develop social intelligence through simulated interactions. By grounding the training of these agents in a rich, dynamic social setting, the researchers hope to create AI systems that can engage in more natural, meaningful, and empathetic conversations with humans.
The key innovation of \trjnfamilySOTOPIA-π is its focus on interactive learning, where agents must learn social skills through a process of trial-and-error and feedback from virtual characters. This contrasts with traditional approaches that have often relied on pre-programmed social skills or static datasets.
While the \trjnfamilySOTOPIA-π framework shows promise, it also faces several challenges and limitations that will need to be addressed through further research. Nonetheless, this work represents an important step towards the development of socially intelligent language agents that can engage in more natural, empathetic, and meaningful interactions with humans.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SOTOPIA-$pi$: Interactive Learning of Socially Intelligent Language Agents
Ruiyi Wang, Haofei Yu, Wenxin Zhang, Zhengyang Qi, Maarten Sap, Graham Neubig, Yonatan Bisk, Hao Zhu
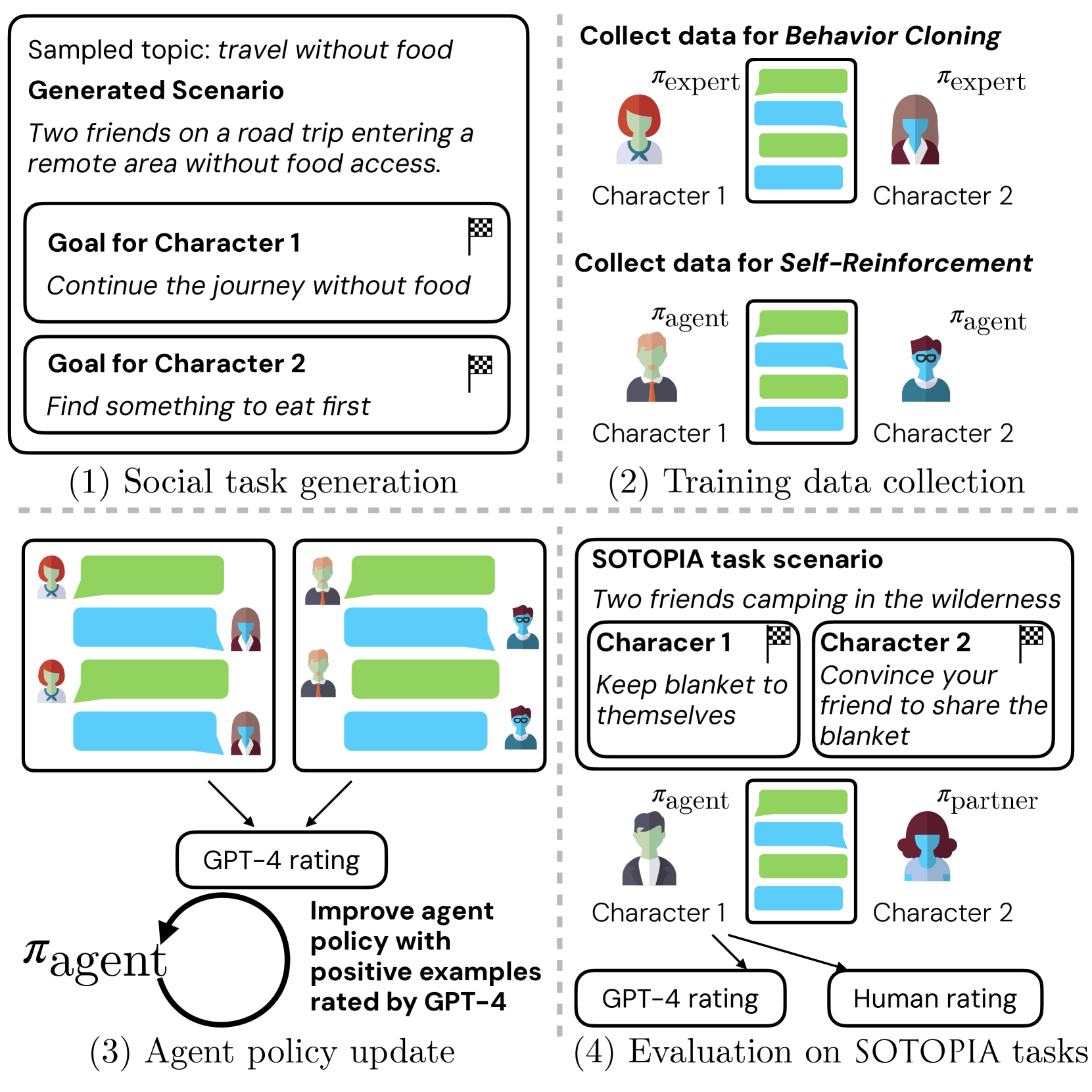
Humans learn social skills through both imitation and social interaction. This social learning process is largely understudied by existing research on building language agents. Motivated by this gap, we propose an interactive learning method, SOTOPIA-$pi$, improving the social intelligence of language agents. This method leverages behavior cloning and self-reinforcement training on filtered social interaction data according to large language model (LLM) ratings. We show that our training method allows a 7B LLM to reach the social goal completion ability of an expert model (GPT-4-based agent), while improving the safety of language agents and maintaining general QA ability on the MMLU benchmark. We also find that this training paradigm uncovers some difficulties in LLM-based evaluation of social intelligence: LLM-based evaluators overestimate the abilities of the language agents trained specifically for social interaction.
Read more4/29/2024

0
Social Learning through Interactions with Other Agents: A Survey
Dylan hillier, Cheston Tan, Jing Jiang
Social learning plays an important role in the development of human intelligence. As children, we imitate our parents' speech patterns until we are able to produce sounds; we learn from them praising us and scolding us; and as adults, we learn by working with others. In this work, we survey the degree to which this paradigm -- social learning -- has been mirrored in machine learning. In particular, since learning socially requires interacting with others, we are interested in how embodied agents can and have utilised these techniques. This is especially in light of the degree to which recent advances in natural language processing (NLP) enable us to perform new forms of social learning. We look at how behavioural cloning and next-token prediction mirror human imitation, how learning from human feedback mirrors human education, and how we can go further to enable fully communicative agents that learn from each other. We find that while individual social learning techniques have been used successfully, there has been little unifying work showing how to bring them together into socially embodied agents.
Read more8/1/2024

0
SPL: A Socratic Playground for Learning Powered by Large Language Mode
Liang Zhang, Jionghao Lin, Ziyi Kuang, Sheng Xu, Mohammed Yeasin, Xiangen Hu
Dialogue-based Intelligent Tutoring Systems (ITSs) have significantly advanced adaptive and personalized learning by automating sophisticated human tutoring strategies within interactive dialogues. However, replicating the nuanced patterns of expert human communication remains a challenge in Natural Language Processing (NLP). Recent advancements in NLP, particularly Large Language Models (LLMs) such as OpenAI's GPT-4, offer promising solutions by providing human-like and context-aware responses based on extensive pre-trained knowledge. Motivated by the effectiveness of LLMs in various educational tasks (e.g., content creation and summarization, problem-solving, and automated feedback provision), our study introduces the Socratic Playground for Learning (SPL), a dialogue-based ITS powered by the GPT-4 model, which employs the Socratic teaching method to foster critical thinking among learners. Through extensive prompt engineering, SPL can generate specific learning scenarios and facilitates efficient multi-turn tutoring dialogues. The SPL system aims to enhance personalized and adaptive learning experiences tailored to individual needs, specifically focusing on improving critical thinking skills. Our pilot experimental results from essay writing tasks demonstrate SPL has the potential to improve tutoring interactions and further enhance dialogue-based ITS functionalities. Our study, exemplified by SPL, demonstrates how LLMs enhance dialogue-based ITSs and expand the accessibility and efficacy of educational technologies.
Read more6/24/2024

0
Contrastive Imitation Learning for Language-guided Multi-Task Robotic Manipulation
Teli Ma, Jiaming Zhou, Zifan Wang, Ronghe Qiu, Junwei Liang
Developing robots capable of executing various manipulation tasks, guided by natural language instructions and visual observations of intricate real-world environments, remains a significant challenge in robotics. Such robot agents need to understand linguistic commands and distinguish between the requirements of different tasks. In this work, we present Sigma-Agent, an end-to-end imitation learning agent for multi-task robotic manipulation. Sigma-Agent incorporates contrastive Imitation Learning (contrastive IL) modules to strengthen vision-language and current-future representations. An effective and efficient multi-view querying Transformer (MVQ-Former) for aggregating representative semantic information is introduced. Sigma-Agent shows substantial improvement over state-of-the-art methods under diverse settings in 18 RLBench tasks, surpassing RVT by an average of 5.2% and 5.9% in 10 and 100 demonstration training, respectively. Sigma-Agent also achieves 62% success rate with a single policy in 5 real-world manipulation tasks. The code will be released upon acceptance.
Read more6/17/2024