Source -Free Domain Adaptation for Speaker Verification in Data-Scarce Languages and Noisy Channels

0
🤿
Sign in to get full access
Overview
- Domain adaptation is a challenge in speech verification due to small target datasets and limited access to source data
- This paper explores techniques for source-free domain adaptation with limited target speech data for speaker verification in data-scarce languages
- Investigates language and channel mismatch between source and target data
- Evaluates fine-tuning methods and a novel iterative cluster-learning algorithm for unlabeled target datasets
Plain English Explanation
Domain adaptation is the process of taking a machine learning model trained on one dataset (the "source" dataset) and adapting it to perform well on a different dataset (the "target" dataset). This can be a particularly tricky challenge in the field of speech verification, where the availability of speech data is often limited.
In this paper, the researchers explored techniques for source-free domain adaptation - that is, adapting a model to a new target dataset without access to the original source data. This is a common scenario in speech verification, where privacy policies or the scarcity of speech resources in certain languages can make the source data inaccessible.
The researchers investigated two main issues: language mismatch and channel mismatch between the source and target datasets. Language mismatch refers to the model being trained on one language and then needing to be adapted to a different language. Channel mismatch refers to differences in the recording equipment or environment between the source and target data.
The paper evaluated various fine-tuning methods, which involve taking a pre-trained model and further training it on the target dataset. They also studied a novel "iterative cluster-learn" algorithm for adapting the model when the target dataset is completely unlabeled (i.e., without any information about who the speakers are).
Technical Explanation
The researchers explored source-free domain adaptation techniques for speaker verification in data-scarce languages, where both language and channel mismatch between source and target data posed challenges.
They evaluated fine-tuning methods, which involve taking a pre-trained model and further training it on the limited target dataset. This was done across different sizes of labeled target data to understand the impact of data quantity.
Additionally, the researchers studied a novel iterative cluster-learn algorithm for adapting the model when the target dataset is completely unlabeled (i.e., without any information about who the speakers are). This unsupervised approach iteratively clusters the target data and updates the model accordingly, without requiring labeled examples.
The experiments investigated the performance of these techniques in overcoming the language and channel mismatch between source and target data for speaker verification.
Critical Analysis
The paper acknowledges the limitations of the study, noting that the target datasets used were still relatively small, and that further research is needed to evaluate the techniques on even more data-scarce scenarios.
Additionally, while the iterative cluster-learn algorithm showed promise for unlabeled target data, the paper does not provide a comprehensive comparison to other unsupervised domain adaptation methods that could also be applicable. Further research could explore the relative strengths and weaknesses of this novel approach compared to other unsupervised techniques.
Overall, this work makes a valuable contribution by exploring practical solutions to the challenge of source-free domain adaptation in speech verification, which has important real-world applications where data privacy and scarcity are major constraints. However, as with any research, there are opportunities for continued refinement and expansion of the techniques presented.
Conclusion
This paper addresses a significant challenge in speech verification by exploring source-free domain adaptation techniques for adapting models to limited target datasets, even when faced with language and channel mismatch between the source and target data.
The findings demonstrate the effectiveness of fine-tuning methods and a novel iterative cluster-learn algorithm for overcoming these domain adaptation hurdles. This research has important implications for building robust speech verification systems, especially in data-scarce languages and scenarios where privacy concerns limit access to source data.
By advancing the state of the art in source-free domain adaptation for speech, this work paves the way for more accessible and inclusive speaker verification technologies that can be deployed in a wider range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Source -Free Domain Adaptation for Speaker Verification in Data-Scarce Languages and Noisy Channels
Shlomo Salo Elia, Aviad Malachi, Vered Aharonson, Gadi Pinkas
Domain adaptation is often hampered by exceedingly small target datasets and inaccessible source data. These conditions are prevalent in speech verification, where privacy policies and/or languages with scarce speech resources limit the availability of sufficient data. This paper explored techniques of sourcefree domain adaptation unto a limited target speech dataset for speaker verificationin data-scarce languages. Both language and channel mis-match between source and target were investigated. Fine-tuning methods were evaluated and compared across different sizes of labeled target data. A novel iterative cluster-learn algorithm was studied for unlabeled target datasets.
Read more6/11/2024

0
The Database and Benchmark for Source Speaker Verification Against Voice Conversion
Ze Li, Yuke Lin, Tian Yao, Hongbin Suo, Ming Li
Voice conversion systems can transform audio to mimic another speaker's voice, thereby attacking speaker verification systems. However, ongoing studies on source speaker verification are hindered by limited data availability and methodological constraints. In this paper, we generate a large-scale converted speech database and train a batch of baseline systems based on the MFA-Conformer architecture to promote the source speaker verification task. In addition, we introduce a related task called conversion method recognition. An adapter-based multi-task learning approach is employed to achieve effective conversion method recognition without compromising source speaker verification performance. Additionally, we investigate and effectively address the open-set conversion method recognition problem through the implementation of an open-set nearest neighbor approach.
Read more6/10/2024
👀
0
Source-Free Domain Adaptation Guided by Vision and Vision-Language Pre-Training
Wenyu Zhang, Li Shen, Chuan-Sheng Foo
Source-free domain adaptation (SFDA) aims to adapt a source model trained on a fully-labeled source domain to a related but unlabeled target domain. While the source model is a key avenue for acquiring target pseudolabels, the generated pseudolabels may exhibit source bias. In the conventional SFDA pipeline, a large data (e.g. ImageNet) pre-trained feature extractor is used to initialize the source model at the start of source training, and subsequently discarded. Despite having diverse features important for generalization, the pre-trained feature extractor can overfit to the source data distribution during source training and forget relevant target domain knowledge. Rather than discarding this valuable knowledge, we introduce an integrated framework to incorporate pre-trained networks into the target adaptation process. The proposed framework is flexible and allows us to plug modern pre-trained networks into the adaptation process to leverage their stronger representation learning capabilities. For adaptation, we propose the Co-learn algorithm to improve target pseudolabel quality collaboratively through the source model and a pre-trained feature extractor. Building on the recent success of the vision-language model CLIP in zero-shot image recognition, we present an extension Co-learn++ to further incorporate CLIP's zero-shot classification decisions. We evaluate on 4 benchmark datasets and include more challenging scenarios such as open-set, partial-set and open-partial SFDA. Experimental results demonstrate that our proposed strategy improves adaptation performance and can be successfully integrated with existing SFDA methods.
Read more8/22/2024
0
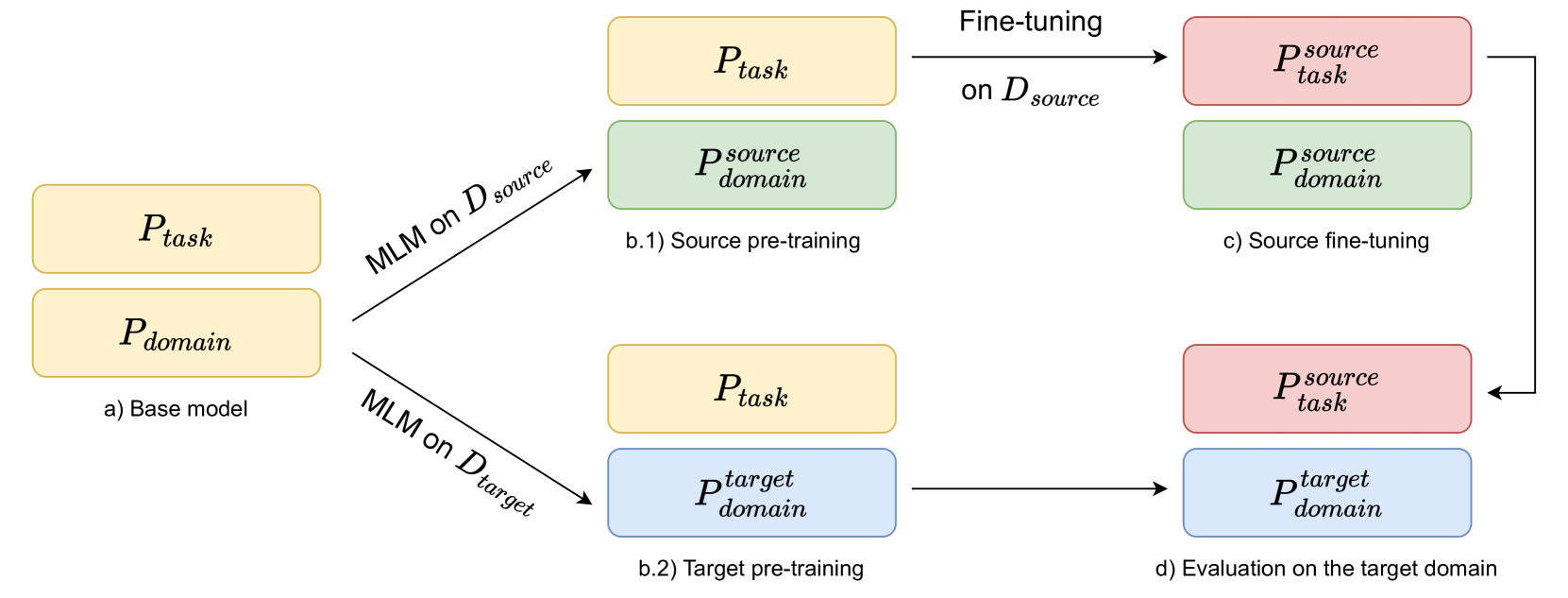
Simple Domain Adaptation for Sparse Retrievers
Mathias Vast, Yuxuan Zong, Basile Van Cooten, Benjamin Piwowarski, Laure Soulier
In Information Retrieval, and more generally in Natural Language Processing, adapting models to specific domains is conducted through fine-tuning. Despite the successes achieved by this method and its versatility, the need for human-curated and labeled data makes it impractical to transfer to new tasks, domains, and/or languages when training data doesn't exist. Using the model without training (zero-shot) is another option that however suffers an effectiveness cost, especially in the case of first-stage retrievers. Numerous research directions have emerged to tackle these issues, most of them in the context of adapting to a task or a language. However, the literature is scarcer for domain (or topic) adaptation. In this paper, we address this issue of cross-topic discrepancy for a sparse first-stage retriever by transposing a method initially designed for language adaptation. By leveraging pre-training on the target data to learn domain-specific knowledge, this technique alleviates the need for annotated data and expands the scope of domain adaptation. Despite their relatively good generalization ability, we show that even sparse retrievers can benefit from our simple domain adaptation method.
Read more7/8/2024