Simple Domain Adaptation for Sparse Retrievers

0
Sign in to get full access
Overview
- Presents a simple domain adaptation technique for improving the performance of sparse retrievers on new domains
- Focuses on transferring knowledge from a source domain (e.g., web pages) to a target domain (e.g., scientific papers)
- Demonstrates effectiveness on multiple information retrieval tasks across different domains
Plain English Explanation
Domain adaptation is the process of adapting a machine learning model trained on one type of data (the source domain) to perform well on a different type of data (the target domain). This is important because models don't always generalize well from one domain to another.
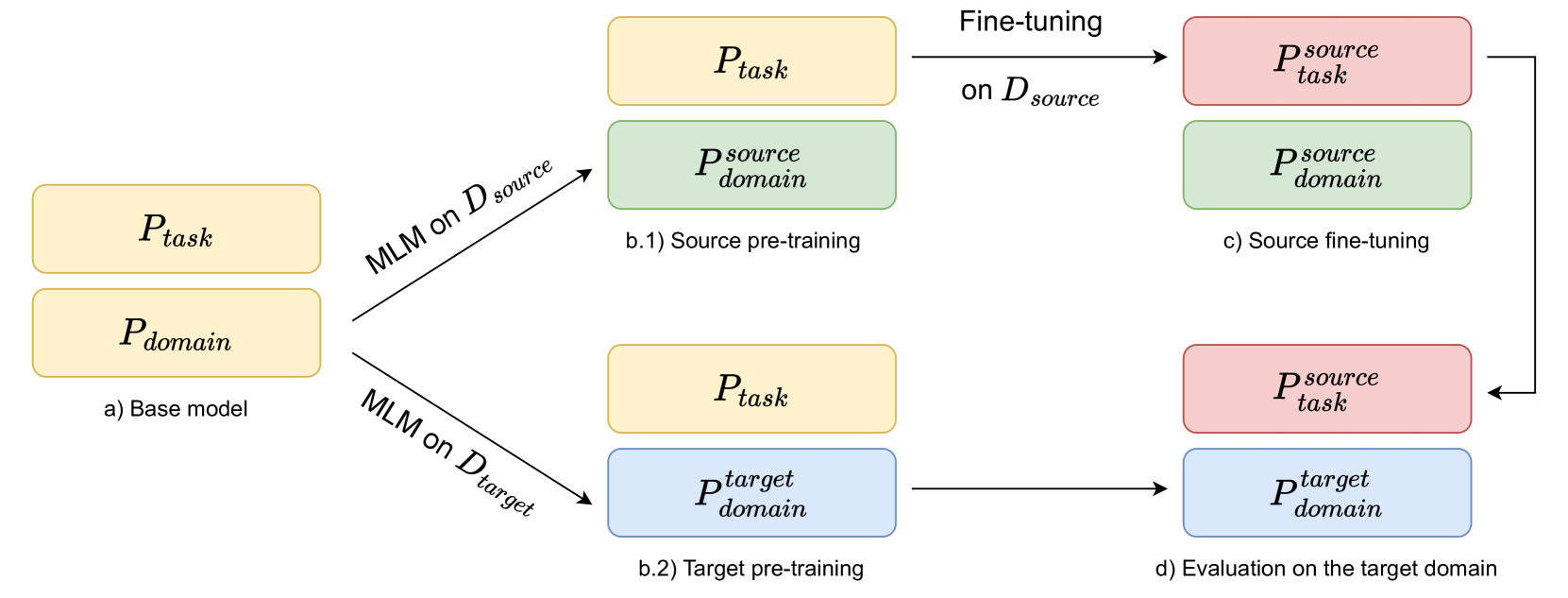
In this paper, the researchers propose a simple domain adaptation technique for improving the performance of sparse retrievers, which are models used to search through large collections of text to find relevant information. The key idea is to fine-tune the retriever model on a small amount of target domain data, which helps it better understand the characteristics of the new domain.
The researchers demonstrate the effectiveness of their approach on multiple information retrieval tasks, transferring knowledge from source domains like web pages to target domains like scientific papers. By improving the retriever's performance on new domains, this technique can make search systems more useful in a variety of real-world applications.
Technical Explanation
The paper proposes a simple domain adaptation technique for sparse retrievers, which are models used to search through large text collections and retrieve relevant information. The key idea is to fine-tune the retriever model on a small amount of target domain data, which helps it better understand the characteristics of the new domain and improve its performance.
The researchers evaluate their approach on multiple information retrieval tasks, transferring knowledge from source domains like web pages to target domains like scientific papers. They show that fine-tuning the retriever on just a few hundred target domain examples can significantly boost its performance compared to using the original model.
The experiments demonstrate the effectiveness of this simple domain adaptation technique across different retrieval tasks and datasets, highlighting its potential for practical applications where models need to work well on new types of text.
Critical Analysis
The paper presents a straightforward and effective domain adaptation approach for sparse retrievers, but there are a few potential limitations and areas for further research:
-
The experiments focus on relatively small-scale datasets, so it's unclear how the technique would scale to much larger collections of text. Evaluating on more diverse and challenging datasets could provide a more comprehensive understanding of the method's strengths and weaknesses.
-
The paper does not explore the trade-offs between the amount of target domain data used for fine-tuning and the resulting performance gains. Investigating this relationship could help practitioners determine the optimal amount of fine-tuning data for their specific use cases.
-
The proposed technique is fairly simplistic, relying solely on fine-tuning the retriever model. Exploring more advanced domain adaptation methods, such as adversarial training or meta-learning, could potentially lead to even greater performance improvements.
Overall, the paper presents a promising and practical domain adaptation approach for sparse retrievers, but further research is needed to fully understand its capabilities and limitations in real-world applications.
Conclusion
This paper introduces a simple yet effective domain adaptation technique for improving the performance of sparse retrievers on new domains. By fine-tuning the retriever model on a small amount of target domain data, the researchers demonstrate significant performance gains across multiple information retrieval tasks.
The key strength of this approach is its simplicity and ease of implementation, making it a potentially valuable tool for practitioners who need to deploy search systems in diverse environments. While the experiments are limited in scale, the results suggest that this domain adaptation technique could have broad applicability in real-world information retrieval scenarios.
As natural language processing and information retrieval continue to advance, techniques like the one presented in this paper will be crucial for ensuring that search systems can adapt and perform well in a wide range of domains and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Simple Domain Adaptation for Sparse Retrievers
Mathias Vast, Yuxuan Zong, Basile Van Cooten, Benjamin Piwowarski, Laure Soulier
In Information Retrieval, and more generally in Natural Language Processing, adapting models to specific domains is conducted through fine-tuning. Despite the successes achieved by this method and its versatility, the need for human-curated and labeled data makes it impractical to transfer to new tasks, domains, and/or languages when training data doesn't exist. Using the model without training (zero-shot) is another option that however suffers an effectiveness cost, especially in the case of first-stage retrievers. Numerous research directions have emerged to tackle these issues, most of them in the context of adapting to a task or a language. However, the literature is scarcer for domain (or topic) adaptation. In this paper, we address this issue of cross-topic discrepancy for a sparse first-stage retriever by transposing a method initially designed for language adaptation. By leveraging pre-training on the target data to learn domain-specific knowledge, this technique alleviates the need for annotated data and expands the scope of domain adaptation. Despite their relatively good generalization ability, we show that even sparse retrievers can benefit from our simple domain adaptation method.
Read more7/8/2024
🔍
0
Domain adaptation in small-scale and heterogeneous biological datasets
Seyedmehdi Orouji, Martin C. Liu, Tal Korem, Megan A. K. Peters
Machine learning techniques are steadily becoming more important in modern biology, and are used to build predictive models, discover patterns, and investigate biological problems. However, models trained on one dataset are often not generalizable to other datasets from different cohorts or laboratories, due to differences in the statistical properties of these datasets. These could stem from technical differences, such as the measurement technique used, or from relevant biological differences between the populations studied. Domain adaptation, a type of transfer learning, can alleviate this problem by aligning the statistical distributions of features and samples among different datasets so that similar models can be applied across them. However, a majority of state-of-the-art domain adaptation methods are designed to work with large-scale data, mostly text and images, while biological datasets often suffer from small sample sizes, and possess complexities such as heterogeneity of the feature space. This Review aims to synthetically discuss domain adaptation methods in the context of small-scale and highly heterogeneous biological data. We describe the benefits and challenges of domain adaptation in biological research and critically discuss some of its objectives, strengths, and weaknesses through key representative methodologies. We argue for the incorporation of domain adaptation techniques to the computational biologist's toolkit, with further development of customized approaches.
Read more5/30/2024
🤿
0
Source -Free Domain Adaptation for Speaker Verification in Data-Scarce Languages and Noisy Channels
Shlomo Salo Elia, Aviad Malachi, Vered Aharonson, Gadi Pinkas
Domain adaptation is often hampered by exceedingly small target datasets and inaccessible source data. These conditions are prevalent in speech verification, where privacy policies and/or languages with scarce speech resources limit the availability of sufficient data. This paper explored techniques of sourcefree domain adaptation unto a limited target speech dataset for speaker verificationin data-scarce languages. Both language and channel mis-match between source and target were investigated. Fine-tuning methods were evaluated and compared across different sizes of labeled target data. A novel iterative cluster-learn algorithm was studied for unlabeled target datasets.
Read more6/11/2024

0
Deep Domain Specialisation for single-model multi-domain learning to rank
Paul Missault, Abdelmaseeh Felfel
Information Retrieval (IR) practitioners often train separate ranking models for different domains (geographic regions, languages, stores, websites,...) as it is believed that exclusively training on in-domain data yields the best performance when sufficient data is available. Despite their performance gains, training multiple models comes at a higher cost to train, maintain and update compared to having only a single model responsible for all domains. Our work explores consolidated ranking models that serve multiple domains. Specifically, we propose a novel architecture of Deep Domain Specialisation (DDS) to consolidate multiple domains into a single model. We compare our proposal against Deep Domain Adaptation (DDA) and a set of baseline for multi-domain models. In our experiments, DDS performed the best overall while requiring fewer parameters per domain as other baselines. We show the efficacy of our method both with offline experimentation and on a large-scale online experiment on Amazon customer traffic.
Read more7/2/2024