Sparse Concept Bottleneck Models: Gumbel Tricks in Contrastive Learning
2404.03323
0
0
Abstract
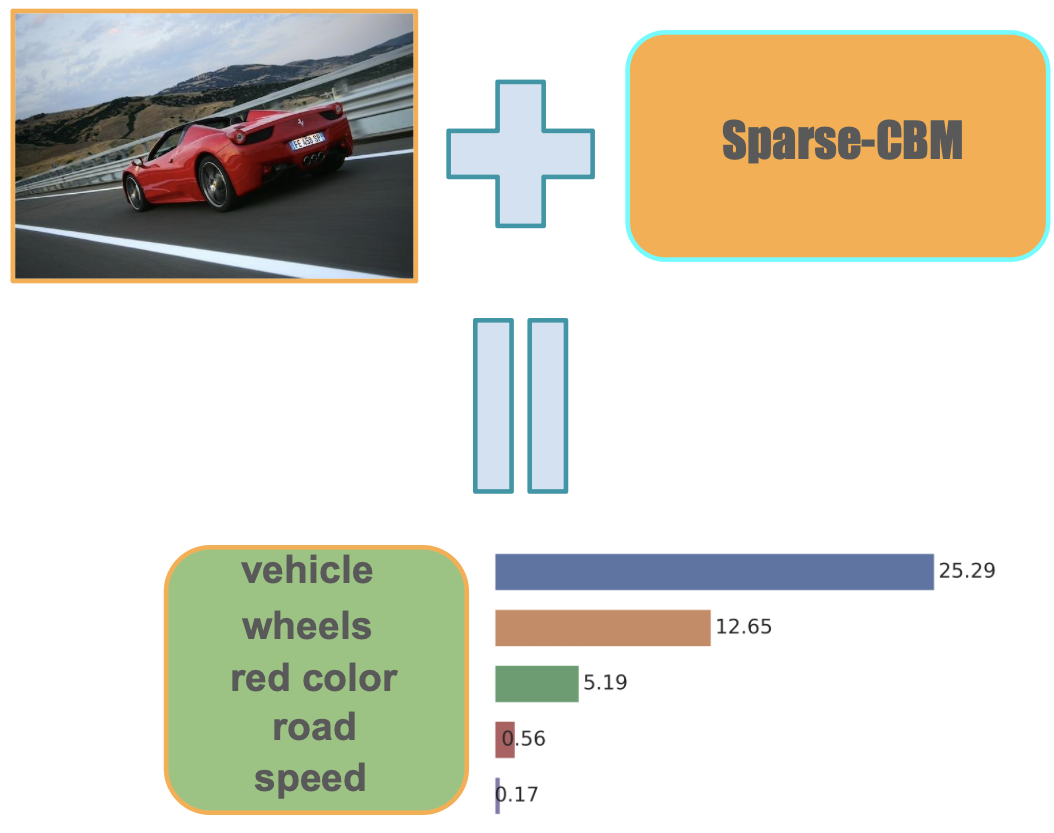
We propose a novel architecture and method of explainable classification with Concept Bottleneck Models (CBMs). While SOTA approaches to Image Classification task work as a black box, there is a growing demand for models that would provide interpreted results. Such a models often learn to predict the distribution over class labels using additional description of this target instances, called concepts. However, existing Bottleneck methods have a number of limitations: their accuracy is lower than that of a standard model and CBMs require an additional set of concepts to leverage. We provide a framework for creating Concept Bottleneck Model from pre-trained multi-modal encoder and new CLIP-like architectures. By introducing a new type of layers known as Concept Bottleneck Layers, we outline three methods for training them: with $ell_1$-loss, contrastive loss and loss function based on Gumbel-Softmax distribution (Sparse-CBM), while final FC layer is still trained with Cross-Entropy. We show a significant increase in accuracy using sparse hidden layers in CLIP-based bottleneck models. Which means that sparse representation of concepts activation vector is meaningful in Concept Bottleneck Models. Moreover, with our Concept Matrix Search algorithm we can improve CLIP predictions on complex datasets without any additional training or fine-tuning. The code is available at: https://github.com/Andron00e/SparseCBM.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores a new machine learning model called Sparse Concept Bottleneck Models that aims to learn compact, interpretable representations of data
- Leverages contrastive learning techniques and "Gumbel tricks" to encourage the model to learn sparse, meaningful features
- Demonstrates the model's effectiveness on various image classification tasks
Plain English Explanation
Sparse Concept Bottleneck Models seek to learn concise, understandable representations of data that capture the key concepts or features. Rather than learning a complex, opaque model, this approach tries to identify the most important factors driving the data.
The core idea is to create a "bottleneck" in the model architecture that forces it to distill the data down to a compact set of relevant concepts. This is achieved through contrastive learning, where the model tries to pull together examples that share the same key concepts while pushing apart examples that don't. The "Gumbel tricks" refer to a set of techniques that help the model converge to these sparse, discrete representations.
By learning these interpretable features, the model can not only perform well on classification tasks, but also provide insights into what aspects of the data are most important. This can be valuable for applications where transparency and explainability are crucial, such as medical diagnosis or financial modeling.
Technical Explanation
The paper introduces Sparse Concept Bottleneck Models, a new approach to learning compact, meaningful representations of data. The model consists of an encoder that maps inputs to a bottleneck layer, followed by a classifier. The key innovation is the design of the bottleneck layer, which encourages the model to learn a sparse set of discrete "concepts" that capture the most salient features of the data.
This is achieved through a contrastive learning objective, where the model tries to pull together examples that share the same concepts while pushing apart examples that don't. The authors leverage "Gumbel tricks" - a set of techniques inspired by the Gumbel-Softmax distribution - to facilitate the learning of these sparse, discrete representations in the bottleneck layer.
The authors evaluate their approach on various image classification tasks, demonstrating that Sparse Concept Bottleneck Models can achieve competitive performance while also providing interpretable insights into the learned concepts. By identifying the most important features driving the data, these models offer a promising direction for developing transparent and explainable AI systems.
Critical Analysis
The Sparse Concept Bottleneck Model approach represents an interesting step towards building more interpretable machine learning models. By encouraging the model to learn a sparse set of discrete concepts, the authors have shown that it is possible to achieve strong performance on classification tasks while also providing insights into the key factors driving the data.
However, the paper does not extensively explore the limitations or potential downsides of this approach. For example, it is unclear how the model would perform on more complex datasets with a large number of interacting concepts, or how sensitive the approach is to hyperparameter tuning and architectural choices.
Additionally, the authors do not delve into the cognitive plausibility or real-world applicability of the learned concepts. While the interpretability of the model is a key strength, more research is needed to understand how these concepts align with human understanding and how they could be leveraged in practical applications.
Overall, the Sparse Concept Bottleneck Model is a promising step forward in the quest for more transparent and explainable AI systems. Further research exploring the model's robustness, scalability, and alignment with human cognition would help strengthen the case for its adoption in real-world applications.
Conclusion
The Sparse Concept Bottleneck Model represents an innovative approach to learning compact, interpretable representations of data. By leveraging contrastive learning and Gumbel tricks, the model is able to identify a sparse set of discrete concepts that capture the key features driving the data. This offers the potential for building more transparent and explainable AI systems, which could be valuable in domains where understanding the underlying factors is crucial.
While the paper demonstrates the model's effectiveness on various image classification tasks, further research is needed to fully understand its limitations and real-world applicability. Exploring how the learned concepts align with human cognition and evaluating the model's performance on more complex datasets would help strengthen the case for this approach. Overall, the Sparse Concept Bottleneck Model represents an exciting step forward in the quest for interpretable machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Incremental Residual Concept Bottleneck Models
Chenming Shang, Shiji Zhou, Yujiu Yang, Hengyuan Zhang, Xinzhe Ni, Yuwang Wang
0
0
Concept Bottleneck Models (CBMs) map the black-box visual representations extracted by deep neural networks onto a set of interpretable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. Multimodal pre-trained models can match visual representations with textual concept embeddings, allowing for obtaining the interpretable concept bottleneck without the expertise concept annotations. Recent research has focused on the concept bank establishment and the high-quality concept selection. However, it is challenging to construct a comprehensive concept bank through humans or large language models, which severely limits the performance of CBMs. In this work, we propose the Incremental Residual Concept Bottleneck Model (Res-CBM) to address the challenge of concept completeness. Specifically, the residual concept bottleneck model employs a set of optimizable vectors to complete missing concepts, then the incremental concept discovery module converts the complemented vectors with unclear meanings into potential concepts in the candidate concept bank. Our approach can be applied to any user-defined concept bank, as a post-hoc processing method to enhance the performance of any CBMs. Furthermore, to measure the descriptive efficiency of CBMs, the Concept Utilization Efficiency (CUE) metric is proposed. Experiments show that the Res-CBM outperforms the current state-of-the-art methods in terms of both accuracy and efficiency and achieves comparable performance to black-box models across multiple datasets.
4/16/2024
🤔
Interpretable-by-Design Text Understanding with Iteratively Generated Concept Bottleneck
Josh Magnus Ludan, Qing Lyu, Yue Yang, Liam Dugan, Mark Yatskar, Chris Callison-Burch
0
0
Black-box deep neural networks excel in text classification, yet their application in high-stakes domains is hindered by their lack of interpretability. To address this, we propose Text Bottleneck Models (TBM), an intrinsically interpretable text classification framework that offers both global and local explanations. Rather than directly predicting the output label, TBM predicts categorical values for a sparse set of salient concepts and uses a linear layer over those concept values to produce the final prediction. These concepts can be automatically discovered and measured by a Large Language Model (LLM) without the need for human curation. Experiments on 12 diverse text understanding datasets demonstrate that TBM can rival the performance of black-box baselines such as few-shot GPT-4 and finetuned DeBERTa while falling short against finetuned GPT-3.5. Comprehensive human evaluation validates that TBM can generate high-quality concepts relevant to the task, and the concept measurement aligns well with human judgments, suggesting that the predictions made by TBMs are interpretable. Overall, our findings suggest that TBM is a promising new framework that enhances interpretability with minimal performance tradeoffs.
4/4/2024
CLIP-QDA: An Explainable Concept Bottleneck Model
R'emi Kazmierczak, Eloise Berthier, Goran Frehse, Gianni Franchi
0
0
In this paper, we introduce an explainable algorithm designed from a multi-modal foundation model, that performs fast and explainable image classification. Drawing inspiration from CLIP-based Concept Bottleneck Models (CBMs), our method creates a latent space where each neuron is linked to a specific word. Observing that this latent space can be modeled with simple distributions, we use a Mixture of Gaussians (MoG) formalism to enhance the interpretability of this latent space. Then, we introduce CLIP-QDA, a classifier that only uses statistical values to infer labels from the concepts. In addition, this formalism allows for both local and global explanations. These explanations come from the inner design of our architecture, our work is part of a new family of greybox models, combining performances of opaque foundation models and the interpretability of transparent models. Our empirical findings show that in instances where the MoG assumption holds, CLIP-QDA achieves similar accuracy with state-of-the-art methods CBMs. Our explanations compete with existing XAI methods while being faster to compute.
4/24/2024
🔄
Learning to Intervene on Concept Bottlenecks
David Steinmann, Wolfgang Stammer, Felix Friedrich, Kristian Kersting
0
0
While traditional deep learning models often lack interpretability, concept bottleneck models (CBMs) provide inherent explanations via their concept representations. Specifically, they allow users to perform interventional interactions on these concepts by updating the concept values and thus correcting the predictive output of the model. Traditionally, however, these interventions are applied to the model only once and discarded afterward. To rectify this, we present concept bottleneck memory models (CB2M), an extension to CBMs. Specifically, a CB2M learns to generalize interventions to appropriate novel situations via a two-fold memory with which it can learn to detect mistakes and to reapply previous interventions. In this way, a CB2M learns to automatically improve model performance from a few initially obtained interventions. If no prior human interventions are available, a CB2M can detect potential mistakes of the CBM bottleneck and request targeted interventions. In our experimental evaluations on challenging scenarios like handling distribution shifts and confounded training data, we illustrate that CB2M are able to successfully generalize interventions to unseen data and can indeed identify wrongly inferred concepts. Overall, our results show that CB2M is a great tool for users to provide interactive feedback on CBMs, e.g., by guiding a user's interaction and requiring fewer interventions.
4/10/2024