Incremental Residual Concept Bottleneck Models

0
Sign in to get full access
Overview
- This paper introduces a new model architecture called Incremental Residual Concept Bottleneck Models (IRCBM) for combining concept-level and end-to-end learning approaches.
- The IRCBM approach aims to leverage the strengths of both concept-level and end-to-end learning to improve model interpretability and performance.
- The paper presents experiments on several benchmark datasets to evaluate the IRCBM model and compare it to other concept bottleneck approaches.
Plain English Explanation
The paper describes a new type of machine learning model called Incremental Residual Concept Bottleneck Models (IRCBM). This model is designed to combine the benefits of two different approaches to machine learning: concept-level learning and end-to-end learning.
In concept-level learning, the model is trained to learn and understand specific concepts or features in the data, which can make the model more interpretable. In end-to-end learning, the model is trained to directly predict the desired output from the raw input data, which can lead to higher performance.
The IRCBM approach tries to take advantage of both of these approaches. The model is trained to learn and understand specific concepts, but it also uses an "incremental residual" technique to improve its overall performance on the task. This means that the model can leverage the interpretability of concept-level learning while still achieving high performance.
The paper presents experiments on several standard machine learning datasets to evaluate the IRCBM model and compare it to other concept bottleneck approaches. The results suggest that the IRCBM model can outperform other methods in terms of both interpretability and performance.
Technical Explanation
The key innovation of the IRCBM approach is the integration of concept-level learning and end-to-end learning through the use of an "incremental residual" technique. The model consists of a concept bottleneck module that learns to predict a set of intermediate concept representations, and a residual module that learns to refine the predictions from the concept bottleneck using an incremental approach.
Specifically, the concept bottleneck module is trained to predict a set of binary concept labels from the input data. These concept labels are then used as an intermediate representation that is passed to the residual module. The residual module takes the concept representations and the original input data, and learns to refine the predictions using an incremental approach, where each layer of the residual module adds an incremental improvement to the predictions.
The authors argue that this approach can leverage the strengths of both concept-level and end-to-end learning. The concept bottleneck module provides interpretability by learning meaningful intermediate representations, while the residual module can improve the overall performance of the model by refining the concept-level predictions.
The paper presents experiments on several benchmark datasets, including CIFAR-10, CUB-200-2011, and SNLI. The results show that the IRCBM model outperforms other concept bottleneck approaches, such as Sparse Concept Bottleneck Models and Concept Bottleneck Models, in terms of both interpretability and performance.
Critical Analysis
The IRCBM approach presented in the paper is a promising step towards combining the benefits of concept-level and end-to-end learning. The authors provide a well-designed and thorough evaluation of their model on several benchmark datasets, which helps to validate their claims.
However, the paper does not discuss some potential limitations or areas for further research. For example, the IRCBM model relies on the ability to learn meaningful intermediate concept representations, which may be challenging in some domains or tasks. Additionally, the incremental residual approach may be sensitive to the choice of hyperparameters or the specific architecture of the residual module.
It would also be interesting to see how the IRCBM model performs on more complex or real-world datasets, where the trade-offs between interpretability and performance may be more pronounced. Dynamic Graph Information Bottleneck models, for example, have shown promising results in modeling complex graph-structured data, and it could be valuable to explore how the IRCBM approach could be extended to such domains.
Overall, the IRCBM model represents an interesting and potentially valuable contribution to the field of interpretable machine learning. However, further research and evaluation will be needed to fully understand the strengths, limitations, and broader implications of this approach.
Conclusion
The Incremental Residual Concept Bottleneck Models (IRCBM) presented in this paper offer a novel approach to combining concept-level and end-to-end learning in machine learning models. By leveraging the interpretability of concept-level representations and the performance of end-to-end learning, the IRCBM model aims to achieve both high interpretability and high performance.
The experimental results suggest that the IRCBM model can outperform other concept bottleneck approaches on several benchmark datasets. This indicates that the incremental residual technique used in the model can effectively harness the strengths of both concept-level and end-to-end learning.
While the paper presents a promising step forward, there are still several areas for further research and exploration. Investigating the model's performance on more complex or real-world datasets, as well as addressing potential limitations related to the learning of meaningful intermediate representations, could help to further validate and refine the IRCBM approach.
Overall, the IRCBM model represents an important contribution to the field of interpretable machine learning, and its ability to combine interpretability and performance makes it a potentially valuable tool for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Incremental Residual Concept Bottleneck Models
Chenming Shang, Shiji Zhou, Yujiu Yang, Hengyuan Zhang, Xinzhe Ni, Yuwang Wang
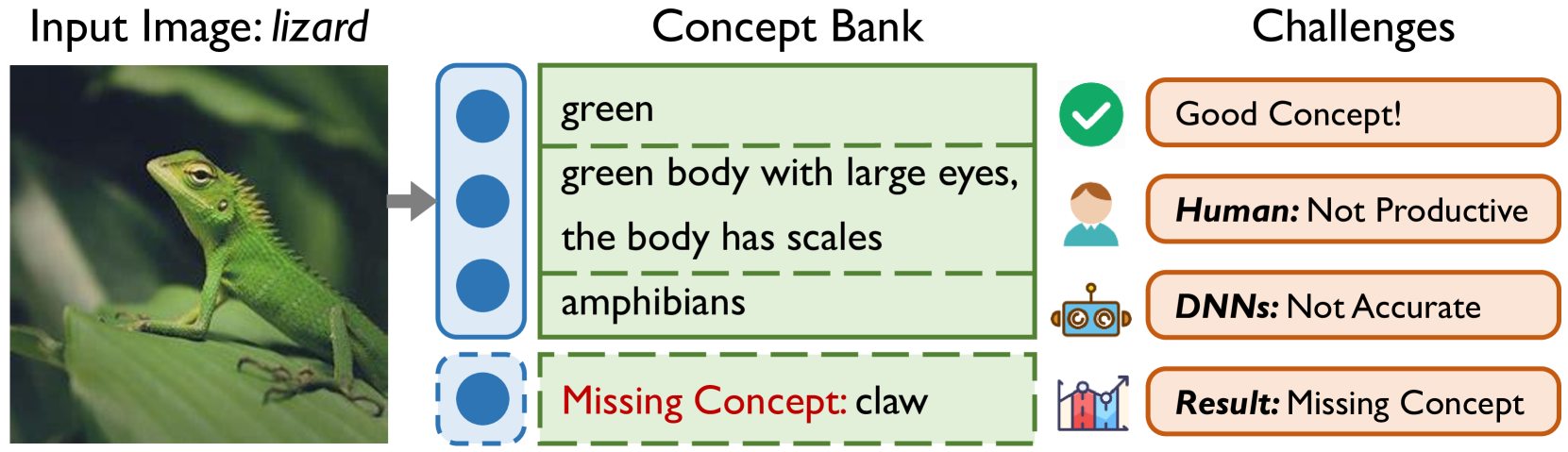
Concept Bottleneck Models (CBMs) map the black-box visual representations extracted by deep neural networks onto a set of interpretable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. Multimodal pre-trained models can match visual representations with textual concept embeddings, allowing for obtaining the interpretable concept bottleneck without the expertise concept annotations. Recent research has focused on the concept bank establishment and the high-quality concept selection. However, it is challenging to construct a comprehensive concept bank through humans or large language models, which severely limits the performance of CBMs. In this work, we propose the Incremental Residual Concept Bottleneck Model (Res-CBM) to address the challenge of concept completeness. Specifically, the residual concept bottleneck model employs a set of optimizable vectors to complete missing concepts, then the incremental concept discovery module converts the complemented vectors with unclear meanings into potential concepts in the candidate concept bank. Our approach can be applied to any user-defined concept bank, as a post-hoc processing method to enhance the performance of any CBMs. Furthermore, to measure the descriptive efficiency of CBMs, the Concept Utilization Efficiency (CUE) metric is proposed. Experiments show that the Res-CBM outperforms the current state-of-the-art methods in terms of both accuracy and efficiency and achieves comparable performance to black-box models across multiple datasets.
Read more4/16/2024
0
Stochastic Concept Bottleneck Models
Moritz Vandenhirtz, Sonia Laguna, Riv{c}ards Marcinkeviv{c}s, Julia E. Vogt
Concept Bottleneck Models (CBMs) have emerged as a promising interpretable method whose final prediction is based on intermediate, human-understandable concepts rather than the raw input. Through time-consuming manual interventions, a user can correct wrongly predicted concept values to enhance the model's downstream performance. We propose Stochastic Concept Bottleneck Models (SCBMs), a novel approach that models concept dependencies. In SCBMs, a single-concept intervention affects all correlated concepts, thereby improving intervention effectiveness. Unlike previous approaches that model the concept relations via an autoregressive structure, we introduce an explicit, distributional parameterization that allows SCBMs to retain the CBMs' efficient training and inference procedure. Additionally, we leverage the parameterization to derive an effective intervention strategy based on the confidence region. We show empirically on synthetic tabular and natural image datasets that our approach improves intervention effectiveness significantly. Notably, we showcase the versatility and usability of SCBMs by examining a setting with CLIP-inferred concepts, alleviating the need for manual concept annotations.
Read more6/28/2024
🔄
0
Learning to Intervene on Concept Bottlenecks
David Steinmann, Wolfgang Stammer, Felix Friedrich, Kristian Kersting
While deep learning models often lack interpretability, concept bottleneck models (CBMs) provide inherent explanations via their concept representations. Moreover, they allow users to perform interventional interactions on these concepts by updating the concept values and thus correcting the predictive output of the model. Up to this point, these interventions were typically applied to the model just once and then discarded. To rectify this, we present concept bottleneck memory models (CB2Ms), which keep a memory of past interventions. Specifically, CB2Ms leverage a two-fold memory to generalize interventions to appropriate novel situations, enabling the model to identify errors and reapply previous interventions. This way, a CB2M learns to automatically improve model performance from a few initially obtained interventions. If no prior human interventions are available, a CB2M can detect potential mistakes of the CBM bottleneck and request targeted interventions. Our experimental evaluations on challenging scenarios like handling distribution shifts and confounded data demonstrate that CB2Ms are able to successfully generalize interventions to unseen data and can indeed identify wrongly inferred concepts. Hence, CB2Ms are a valuable tool for users to provide interactive feedback on CBMs, by guiding a user's interaction and requiring fewer interventions.
Read more6/5/2024

0
Concept Bottleneck Models Without Predefined Concepts
Simon Schrodi, Julian Schur, Max Argus, Thomas Brox
There has been considerable recent interest in interpretable concept-based models such as Concept Bottleneck Models (CBMs), which first predict human-interpretable concepts and then map them to output classes. To reduce reliance on human-annotated concepts, recent works have converted pretrained black-box models into interpretable CBMs post-hoc. However, these approaches predefine a set of concepts, assuming which concepts a black-box model encodes in its representations. In this work, we eliminate this assumption by leveraging unsupervised concept discovery to automatically extract concepts without human annotations or a predefined set of concepts. We further introduce an input-dependent concept selection mechanism that ensures only a small subset of concepts is used across all classes. We show that our approach improves downstream performance and narrows the performance gap to black-box models, while using significantly fewer concepts in the classification. Finally, we demonstrate how large vision-language models can intervene on the final model weights to correct model errors.
Read more7/8/2024