Sparse is Enough in Fine-tuning Pre-trained Large Language Models
2312.11875
0
0

Abstract
With the prevalence of pre-training-fine-tuning paradigm, how to efficiently adapt the pre-trained model to the downstream tasks has been an intriguing issue. Parameter-Efficient Fine-Tuning (PEFT) methods have been proposed for low-cost adaptation. Although PEFT has demonstrated effectiveness and been widely applied, the underlying principles are still unclear. In this paper, we adopt the PAC-Bayesian generalization error bound, viewing pre-training as a shift of prior distribution which leads to a tighter bound for generalization error. We validate this shift from the perspectives of oscillations in the loss landscape and the quasi-sparsity in gradient distribution. Based on this, we propose a gradient-based sparse fine-tuning algorithm, named Sparse Increment Fine-Tuning (SIFT), and validate its effectiveness on a range of tasks including the GLUE Benchmark and Instruction-tuning. The code is accessible at https://github.com/song-wx/SIFT/.
Create account to get full access
Overview
- The paper explores the effectiveness of sparse fine-tuning, where only a small subset of the model parameters are updated during the fine-tuning process, for pre-trained large language models.
- The authors provide a gradient-based perspective to understand the pre-training and fine-tuning dynamics, and show that sparse fine-tuning can achieve comparable performance to dense fine-tuning while significantly reducing the number of parameters that need to be updated.
- The paper also introduces a novel method called Stratified Progressive Adaptation (SPA), which further improves the performance of sparse fine-tuning by progressively adapting different layers of the model.
Plain English Explanation
Large language models, such as GPT-3 and BERT, are powerful AI systems that can understand and generate human-like text. These models are first trained on a vast amount of data in a process called pre-training, which gives them a general understanding of language. Then, they can be fine-tuned on a specific task, such as answering questions or summarizing text, by updating only a small portion of their parameters.
The researchers behind this paper wanted to explore whether it's necessary to update all the model parameters during fine-tuning or if updating only a sparse subset of the parameters could be just as effective. They found that sparse fine-tuning, where only a fraction of the model's parameters are updated, can perform just as well as fine-tuning all the parameters. This is significant because it means you can fine-tune these large models more efficiently, using fewer computational resources and less time.
The researchers also developed a new technique called Stratified Progressive Adaptation (SPA), which further improves the performance of sparse fine-tuning. SPA gradually updates different layers of the model, starting with the higher-level layers and progressively adapting the lower-level layers. This step-by-step approach helps the model learn more effectively with a smaller number of parameters.
Overall, this research shows that you don't need to update all the parameters of a pre-trained language model to achieve good performance on a specific task. By using sparse fine-tuning and techniques like SPA, you can fine-tune these powerful models more efficiently, which could have important implications for real-world applications of large language models.
Technical Explanation
The paper presents a gradient-based perspective to understand the dynamics of pre-training and fine-tuning large language models. The authors show that the gradients during fine-tuning are typically sparse, meaning that only a small subset of the model parameters need to be updated to achieve good performance.
Based on this observation, the researchers propose a sparse fine-tuning approach, where only a fraction of the model parameters are updated during the fine-tuning process. They demonstrate that this sparse fine-tuning can achieve comparable performance to dense fine-tuning (where all parameters are updated) while significantly reducing the number of parameters that need to be updated.
To further improve the performance of sparse fine-tuning, the authors introduce a novel method called Stratified Progressive Adaptation (SPA). SPA gradually adapts different layers of the model, starting with the higher-level layers and progressively fine-tuning the lower-level layers. This step-by-step approach helps the model learn more effectively with a smaller number of parameters.
The paper presents extensive experiments on various natural language processing tasks, including text classification, question answering, and natural language inference. The results show that sparse fine-tuning with SPA can match the performance of dense fine-tuning while reducing the number of updated parameters by up to 90%.
Critical Analysis
The paper provides a strong theoretical and empirical foundation for the effectiveness of sparse fine-tuning of pre-trained large language models. The authors' gradient-based perspective offers a compelling explanation for why sparse fine-tuning can be successful, and the SPA method adds an additional layer of optimization that further boosts the performance of sparse fine-tuning.
One potential limitation of the research is that it focuses primarily on natural language processing tasks and may not generalize as well to other domains, such as computer vision or speech recognition, where the patterns of gradients and parameter importance might differ. Additionally, the paper does not explore the potential impact of the sparse fine-tuning approach on the interpretability or robustness of the fine-tuned models, which could be important considerations for real-world applications.
Another area for further research could be investigating the relationship between the degree of sparsity (i.e., the number of parameters updated) and the task performance, as well as exploring potential ways to dynamically adjust the sparsity level during the fine-tuning process based on the task or dataset characteristics.
Despite these potential limitations, the paper's findings have significant implications for the field of large language model fine-tuning, as they demonstrate that substantial computational and storage savings can be achieved without sacrificing performance. This could lead to more efficient and accessible deployment of these powerful models in various applications.
Conclusion
The paper "Sparse is Enough in Fine-tuning Pre-trained Large Language Model" presents a compelling approach to fine-tuning large language models more efficiently. By leveraging the inherent sparsity of the gradients during fine-tuning and introducing the Stratified Progressive Adaptation method, the researchers show that it is possible to achieve comparable performance to dense fine-tuning while significantly reducing the number of parameters that need to be updated.
This work highlights the potential for parameter-efficient fine-tuning techniques, such as SparFit, PEFT, and Q-PEFT, to unlock the full potential of large language models in real-world applications, where computational resources and deployment time are often critical factors.
By demonstrating the feasibility of sparse fine-tuning, this research opens up new avenues for further optimization and exploration of parameter-efficient techniques for fine-tuning pre-trained models, potentially leading to more accessible and impactful applications of large language models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
SPAFIT: Stratified Progressive Adaptation Fine-tuning for Pre-trained Large Language Models
Samir Arora, Liangliang Wang
0
0
Full fine-tuning is a popular approach to adapt Transformer-based pre-trained large language models to a specific downstream task. However, the substantial requirements for computational power and storage have discouraged its widespread use. Moreover, increasing evidence of catastrophic forgetting and overparameterization in the Transformer architecture has motivated researchers to seek more efficient fine-tuning (PEFT) methods. Commonly known parameter-efficient fine-tuning methods like LoRA and BitFit are typically applied across all layers of the model. We propose a PEFT method, called Stratified Progressive Adaptation Fine-tuning (SPAFIT), based on the localization of different types of linguistic knowledge to specific layers of the model. Our experiments, conducted on nine tasks from the GLUE benchmark, show that our proposed SPAFIT method outperforms other PEFT methods while fine-tuning only a fraction of the parameters adjusted by other methods.
5/2/2024

Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
0
0
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
4/30/2024
👀
Sparse-Tuning: Adapting Vision Transformers with Efficient Fine-tuning and Inference
Ting Liu, Xuyang Liu, Liangtao Shi, Zunnan Xu, Siteng Huang, Yi Xin, Quanjun Yin
0
0
Parameter-efficient fine-tuning (PEFT) has emerged as a popular approach for adapting pre-trained Vision Transformer (ViT) models to downstream applications. While current PEFT methods achieve parameter efficiency, they overlook GPU memory and time efficiency during both fine-tuning and inference, due to the repeated computation of redundant tokens in the ViT architecture. This falls short of practical requirements for downstream task adaptation. In this paper, we propose textbf{Sparse-Tuning}, a novel tuning paradigm that substantially enhances both fine-tuning and inference efficiency for pre-trained ViT models. Sparse-Tuning efficiently fine-tunes the pre-trained ViT by sparsely preserving the informative tokens and merging redundant ones, enabling the ViT to focus on the foreground while reducing computational costs on background regions in the images. To accurately distinguish informative tokens from uninformative ones, we introduce a tailored Dense Adapter, which establishes dense connections across different encoder layers in the ViT, thereby enhancing the representational capacity and quality of token sparsification. Empirical results on VTAB-1K, three complete image datasets, and two complete video datasets demonstrate that Sparse-Tuning reduces the GFLOPs to textbf{62%-70%} of the original ViT-B while achieving state-of-the-art performance. Source code is available at url{https://github.com/liuting20/Sparse-Tuning}.
5/24/2024
An Empirical Study of Parameter Efficient Fine-tuning on Vision-Language Pre-train Model
Yuxin Tian, Mouxing Yang, Yunfan Li, Dayiheng Liu, Xingzhang Ren, Xi Peng, Jiancheng Lv
0
0
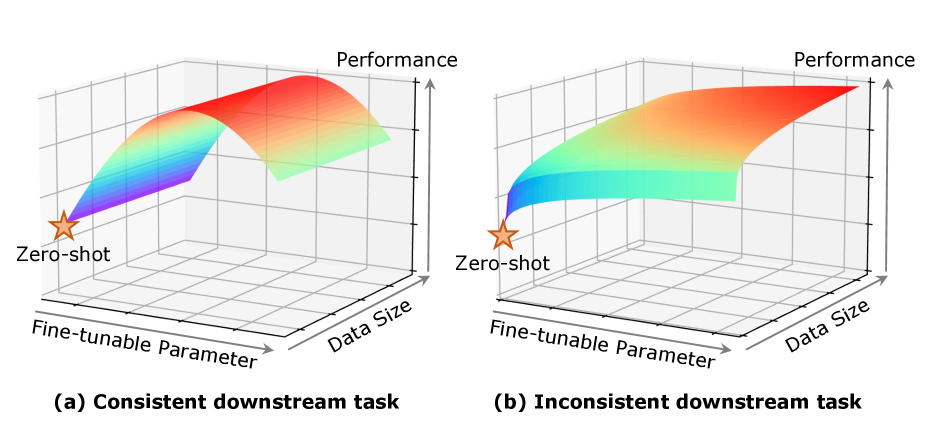
Recent studies applied Parameter Efficient Fine-Tuning techniques (PEFTs) to efficiently narrow the performance gap between pre-training and downstream. There are two important factors for various PEFTs, namely, the accessible data size and fine-tunable parameter size. A natural expectation for PEFTs is that the performance of various PEFTs is positively related to the data size and fine-tunable parameter size. However, according to the evaluation of five PEFTs on two downstream vision-language (VL) tasks, we find that such an intuition holds only if the downstream data and task are not consistent with pre-training. For downstream fine-tuning consistent with pre-training, data size no longer affects the performance, while the influence of fine-tunable parameter size is not monotonous. We believe such an observation could guide the choice of training strategy for various PEFTs.
5/21/2024