Sparsifying dimensionality reduction of PDE solution data with Bregman learning

0

Sign in to get full access
Overview
- This paper proposes a method for sparsifying dimensionality reduction of partial differential equation (PDE) solution data using Bregman learning.
- The goal is to efficiently represent high-dimensional PDE solutions in a low-dimensional space while maintaining important features.
- The method combines dimensionality reduction techniques with sparse optimization to obtain a compact, interpretable representation of the data.
Plain English Explanation
Partial differential equations (PDEs) are mathematical models that describe complex physical phenomena, like fluid flow or heat transfer. When solving these equations numerically, the solutions can become very high-dimensional, making them difficult to work with.
This research looks at ways to reduce the dimensionality of these PDE solutions, while still capturing the important features. The key idea is to find a sparse representation of the data - that is, a version that uses as few variables as possible to describe the essential information.
The researchers use a technique called Bregman learning, which is a type of optimization that encourages sparsity. By combining dimensionality reduction with this sparse optimization, they are able to find a low-dimensional version of the PDE solution data that retains the important characteristics, but uses far fewer variables.
This type of compressed representation can be very useful in a variety of applications, such as physics-informed deep learning or interpretable latent spaces. It allows complex physical models to be more efficiently stored, analyzed, and incorporated into other machine learning tasks.
Technical Explanation
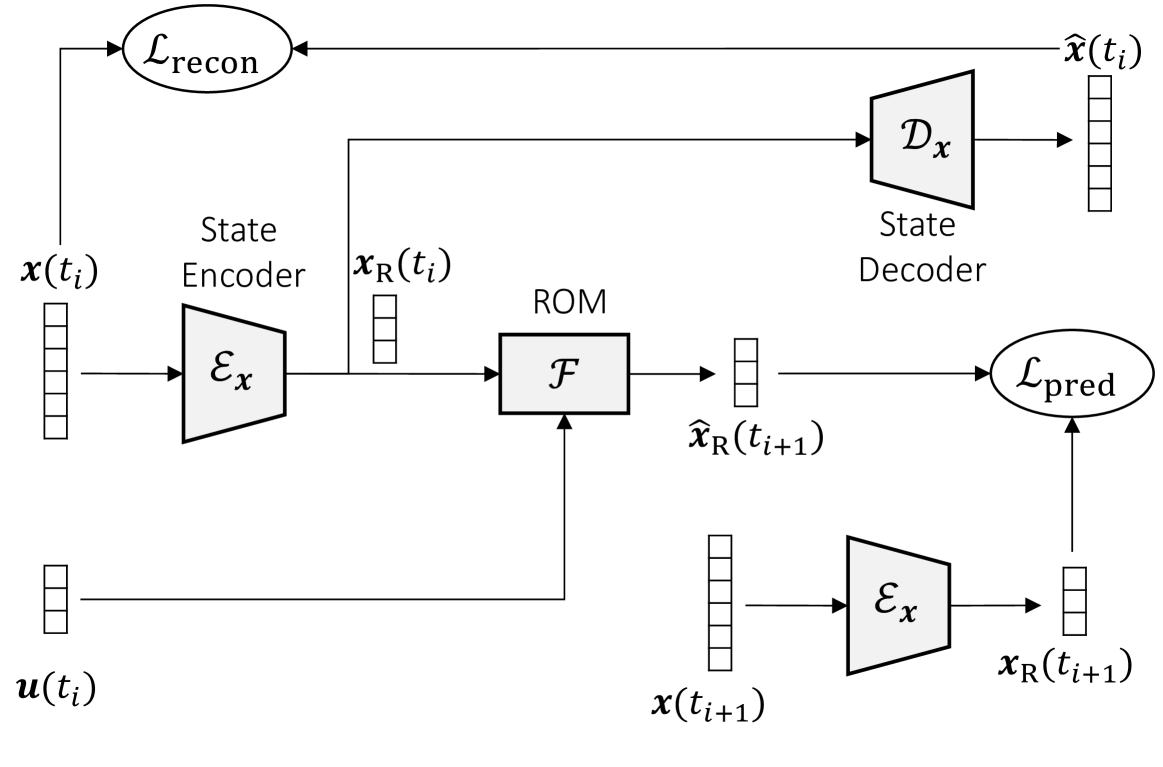
The paper proposes a method for sparsifying the dimensionality reduction of partial differential equation (PDE) solution data using Bregman learning. The goal is to find a low-dimensional representation of high-dimensional PDE solutions that captures the essential features while remaining sparse and interpretable.
The approach combines dimensionality reduction techniques, such as principal component analysis (PCA) or deep neural networks, with sparse optimization using the Bregman iteration.
The Bregman iteration is a general optimization framework that can promote sparsity in the solution. By incorporating this into the dimensionality reduction process, the method is able to find a compact, interpretable representation of the PDE data.
The authors demonstrate the effectiveness of their approach on several benchmark PDE problems, showing that it can achieve significant dimensionality reduction while preserving key features of the solutions. The sparse, low-dimensional representations obtained can be useful for tasks like state estimation or interpretable latent spaces.
Critical Analysis
The paper presents a promising approach for efficiently representing high-dimensional PDE solution data, but there are a few potential limitations and areas for further research:
-
The method relies on the choice of dimensionality reduction technique, which can impact the quality of the sparse representation. Investigating the tradeoffs between different dimensionality reduction approaches could be valuable.
-
The Bregman iteration used for sparse optimization may be sensitive to hyperparameter tuning, and the authors do not provide extensive details on how to choose these parameters effectively.
-
While the experiments demonstrate the method on several benchmark PDE problems, testing it on larger, more complex PDEs would help establish its scalability and real-world applicability.
-
Exploring ways to make the sparse representations more interpretable, beyond just being low-dimensional, could further enhance the method's usefulness in applications like physics-informed deep learning.
Overall, this research represents an interesting step towards efficient and interpretable dimensionality reduction of PDE solution data, but continued work is needed to fully realize the potential of this approach.
Conclusion
This paper presents a method for sparsifying the dimensionality reduction of partial differential equation (PDE) solution data using Bregman learning. By combining dimensionality reduction techniques with sparse optimization, the approach is able to find low-dimensional representations of high-dimensional PDE solutions that capture the essential features while remaining compact and interpretable.
The sparse, low-dimensional representations obtained can be valuable in a variety of applications, such as state estimation, physics-informed deep learning, and interpretable latent spaces. This type of efficient data representation can help make complex physical models more manageable and incorporate them into other machine learning tasks more effectively.
While the paper presents promising results, there are still opportunities for further research to address potential limitations and explore ways to enhance the interpretability and scalability of the method. Continued advancements in this area could lead to significant improvements in how we model and understand complex physical phenomena.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sparsifying dimensionality reduction of PDE solution data with Bregman learning
Tjeerd Jan Heeringa, Christoph Brune, Mengwu Guo
Classical model reduction techniques project the governing equations onto a linear subspace of the original state space. More recent data-driven techniques use neural networks to enable nonlinear projections. Whilst those often enable stronger compression, they may have redundant parameters and lead to suboptimal latent dimensionality. To overcome these, we propose a multistep algorithm that induces sparsity in the encoder-decoder networks for effective reduction in the number of parameters and additional compression of the latent space. This algorithm starts with sparsely initialized a network and training it using linearized Bregman iterations. These iterations have been very successful in computer vision and compressed sensing tasks, but have not yet been used for reduced-order modelling. After the training, we further compress the latent space dimensionality by using a form of proper orthogonal decomposition. Last, we use a bias propagation technique to change the induced sparsity into an effective reduction of parameters. We apply this algorithm to three representative PDE models: 1D diffusion, 1D advection, and 2D reaction-diffusion. Compared to conventional training methods like Adam, the proposed method achieves similar accuracy with 30% less parameters and a significantly smaller latent space.
Read more6/19/2024
0
Bridging Autoencoders and Dynamic Mode Decomposition for Reduced-order Modeling and Control of PDEs
Priyabrata Saha, Saibal Mukhopadhyay
Modeling and controlling complex spatiotemporal dynamical systems driven by partial differential equations (PDEs) often necessitate dimensionality reduction techniques to construct lower-order models for computational efficiency. This paper explores a deep autoencoding learning method for reduced-order modeling and control of dynamical systems governed by spatiotemporal PDEs. We first analytically show that an optimization objective for learning a linear autoencoding reduced-order model can be formulated to yield a solution closely resembling the result obtained through the dynamic mode decomposition with control algorithm. We then extend this linear autoencoding architecture to a deep autoencoding framework, enabling the development of a nonlinear reduced-order model. Furthermore, we leverage the learned reduced-order model to design controllers using stability-constrained deep neural networks. Numerical experiments are presented to validate the efficacy of our approach in both modeling and control using the example of a reaction-diffusion system.
Read more9/12/2024

0
Physics-informed deep learning and compressive collocation for high-dimensional diffusion-reaction equations: practical existence theory and numerics
Simone Brugiapaglia, Nick Dexter, Samir Karam, Weiqi Wang
On the forefront of scientific computing, Deep Learning (DL), i.e., machine learning with Deep Neural Networks (DNNs), has emerged a powerful new tool for solving Partial Differential Equations (PDEs). It has been observed that DNNs are particularly well suited to weakening the effect of the curse of dimensionality, a term coined by Richard E. Bellman in the late `50s to describe challenges such as the exponential dependence of the sample complexity, i.e., the number of samples required to solve an approximation problem, on the dimension of the ambient space. However, although DNNs have been used to solve PDEs since the `90s, the literature underpinning their mathematical efficiency in terms of numerical analysis (i.e., stability, accuracy, and sample complexity), is only recently beginning to emerge. In this paper, we leverage recent advancements in function approximation using sparsity-based techniques and random sampling to develop and analyze an efficient high-dimensional PDE solver based on DL. We show, both theoretically and numerically, that it can compete with a novel stable and accurate compressive spectral collocation method. In particular, we demonstrate a new practical existence theorem, which establishes the existence of a class of trainable DNNs with suitable bounds on the network architecture and a sufficient condition on the sample complexity, with logarithmic or, at worst, linear scaling in dimension, such that the resulting networks stably and accurately approximate a diffusion-reaction PDE with high probability.
Read more6/11/2024
📈
0
Dictionary-based model reduction for state estimation
Anthony Nouy, Alexandre Pasco
We consider the problem of state estimation from a few linear measurements, where the state to recover is an element of the manifold $mathcal{M}$ of solutions of a parameter-dependent equation. The state is estimated using prior knowledge on $mathcal{M}$ coming from model order reduction. Variational approaches based on linear approximation of $mathcal{M}$, such as PBDW, yields a recovery error limited by the Kolmogorov width of $mathcal{M}$. To overcome this issue, piecewise-affine approximations of $mathcal{M}$ have also been considered, that consist in using a library of linear spaces among which one is selected by minimizing some distance to $mathcal{M}$. In this paper, we propose a state estimation method relying on dictionary-based model reduction, where a space is selected from a library generated by a dictionary of snapshots, using a distance to the manifold. The selection is performed among a set of candidate spaces obtained from a set of $ell_1$-regularized least-squares problems. Then, in the framework of parameter-dependent operator equations (or PDEs) with affine parametrizations, we provide an efficient offline-online decomposition based on randomized linear algebra, that ensures efficient and stable computations while preserving theoretical guarantees.
Read more4/4/2024