Sparsity-based Safety Conservatism for Constrained Offline Reinforcement Learning

0

Sign in to get full access
Overview
- This paper presents a novel approach to offline reinforcement learning (RL) that aims to ensure safety and conservatism in the learned policy.
- The method, called Sparsity-based Safety Conservatism (SSC), leverages sparsity in the state-action value function to identify and avoid regions of the state space where the agent's behavior could be unsafe or suboptimal.
- The authors demonstrate the effectiveness of SSC on a range of benchmark tasks, showing that it can outperform alternative safe and conservative RL methods in terms of both safety and performance.
Plain English Explanation
In the world of artificial intelligence, reinforcement learning (RL) is a powerful technique that allows agents to learn how to navigate complex environments and achieve desired goals. However, when RL agents are trained using offline data (i.e., data collected from previous interactions with the environment), there is a risk that the learned policies could be unsafe or overly conservative, potentially leading to suboptimal performance.
The researchers who authored this paper have developed a new approach called Sparsity-based Safety Conservatism (SSC) to address these challenges. The key insight behind SSC is that by identifying and avoiding regions of the state space where the agent's behavior could be unsafe or suboptimal, the learned policy can be made more robust and conservative, ensuring that the agent avoids taking risky actions.
The way SSC works is by leveraging the sparsity in the state-action value function, which is a measure of the expected long-term return for each possible action in a given state. By identifying the "sparse" regions of this function, the researchers are able to pinpoint areas of the state space where the agent's behavior is less certain or reliable. The agent can then be trained to avoid these regions, resulting in a more conservative and safe policy.
The researchers demonstrate the effectiveness of SSC on a range of benchmark tasks, showing that it can outperform alternative safe and conservative RL methods in terms of both safety and performance. This is an important advance in the field of offline RL, as it allows agents to learn policies that are not only effective but also reliable and trustworthy, which is crucial for real-world applications where safety is a paramount concern.
Technical Explanation
The paper presents a novel approach called Sparsity-based Safety Conservatism (SSC) for offline reinforcement learning (RL) that aims to ensure safety and conservatism in the learned policy. The key idea behind SSC is to leverage the sparsity in the state-action value function to identify and avoid regions of the state space where the agent's behavior could be unsafe or suboptimal.
Specifically, the authors formulate the offline RL problem as a constrained optimization problem, where the objective is to maximize the expected return while satisfying safety constraints. To solve this problem, they propose a two-step approach:
-
Sparse Value Estimation: The first step is to estimate the state-action value function using a sparse representation, which allows the identification of regions in the state space where the value function is sparsely populated. These sparse regions correspond to areas of high uncertainty or potential unsafe behavior.
-
Constrained Optimization: In the second step, the authors solve a constrained optimization problem to find the optimal policy, where the constraints are designed to avoid the sparse regions identified in the previous step. This ensures that the learned policy is both safe and conservative, avoiding potentially unsafe actions.
The authors evaluate the performance of SSC on a range of benchmark tasks, including classic control problems and continuous control tasks. They compare SSC to alternative safe and conservative RL methods, such as FOSP, StratCQL, PSRL, and SRLNMS. The results show that SSC can outperform these methods in terms of both safety and performance, demonstrating the effectiveness of the proposed approach.
Critical Analysis
The paper presents a promising approach to addressing the challenges of safety and conservatism in offline RL. The authors' key insight of leveraging sparsity in the state-action value function to identify and avoid potentially unsafe regions of the state space is a novel and interesting idea.
One potential limitation of the SSC method is that it relies on the accuracy of the sparse value estimation step. If the sparse regions identified by the algorithm do not accurately reflect the true areas of uncertainty or unsafe behavior, the resulting policy may still be overly conservative or suboptimal. The authors acknowledge this limitation and suggest that further research into more robust value estimation techniques could help address this issue.
Another potential concern is the computational complexity of the constrained optimization problem that needs to be solved in the second step of the SSC method. For larger and more complex environments, the optimization problem may become intractable, limiting the scalability of the approach. The authors do not provide a detailed analysis of the computational complexity of their method, which would be useful for understanding its practical applicability.
Despite these potential limitations, the paper represents an important contribution to the field of safe and conservative offline RL. The authors' work builds on and complements existing approaches, such as FOSP, StratCQL, PSRL, and SRLNMS, by providing a novel and potentially more effective way to ensure the safety and conservatism of learned policies.
Conclusion
This paper presents a novel approach called Sparsity-based Safety Conservatism (SSC) for offline reinforcement learning that aims to ensure the safety and conservatism of the learned policy. By leveraging the sparsity in the state-action value function, SSC is able to identify and avoid regions of the state space where the agent's behavior could be unsafe or suboptimal, resulting in a more robust and reliable policy.
The authors demonstrate the effectiveness of SSC on a range of benchmark tasks, showing that it can outperform alternative safe and conservative RL methods in terms of both safety and performance. This work represents an important contribution to the field of offline RL, as it addresses a critical challenge in ensuring the reliability and trustworthiness of learned policies, which is essential for real-world applications where safety is a paramount concern.
While the SSC method has some potential limitations, such as its reliance on accurate value estimation and the computational complexity of the constrained optimization problem, the paper provides a solid foundation for further research and development in the area of safe and conservative offline RL. As the field continues to evolve, approaches like SSC will play a crucial role in enabling the widespread adoption of RL technologies in safety-critical domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sparsity-based Safety Conservatism for Constrained Offline Reinforcement Learning
Minjae Cho, Chuangchuang Sun
Reinforcement Learning (RL) has made notable success in decision-making fields like autonomous driving and robotic manipulation. Yet, its reliance on real-time feedback poses challenges in costly or hazardous settings. Furthermore, RL's training approach, centered on on-policy sampling, doesn't fully capitalize on data. Hence, Offline RL has emerged as a compelling alternative, particularly in conducting additional experiments is impractical, and abundant datasets are available. However, the challenge of distributional shift (extrapolation), indicating the disparity between data distributions and learning policies, also poses a risk in offline RL, potentially leading to significant safety breaches due to estimation errors (interpolation). This concern is particularly pronounced in safety-critical domains, where real-world problems are prevalent. To address both extrapolation and interpolation errors, numerous studies have introduced additional constraints to confine policy behavior, steering it towards more cautious decision-making. While many studies have addressed extrapolation errors, fewer have focused on providing effective solutions for tackling interpolation errors. For example, some works tackle this issue by incorporating potential cost-maximizing optimization by perturbing the original dataset. However, this, involving a bi-level optimization structure, may introduce significant instability or complicate problem-solving in high-dimensional tasks. This motivates us to pinpoint areas where hazards may be more prevalent than initially estimated based on the sparsity of available data by providing significant insight into constrained offline RL. In this paper, we present conservative metrics based on data sparsity that demonstrate the high generalizability to any methods and efficacy compared to using bi-level cost-ub-maximization.
Read more7/19/2024
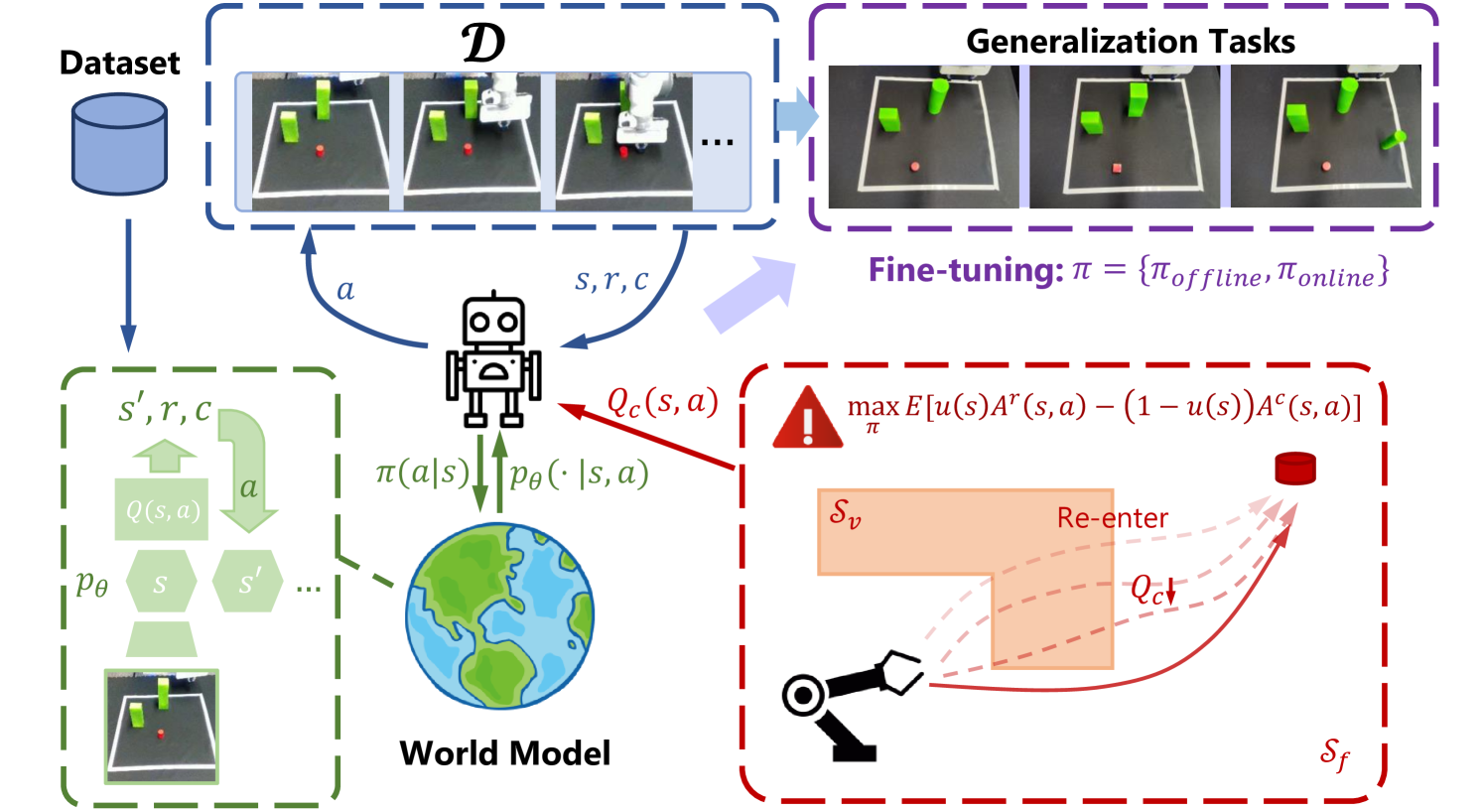
0
FOSP: Fine-tuning Offline Safe Policy through World Models
Chenyang Cao, Yucheng Xin, Silang Wu, Longxiang He, Zichen Yan, Junbo Tan, Xueqian Wang
Model-based Reinforcement Learning (RL) has shown its high training efficiency and capability of handling high-dimensional tasks. Regarding safety issues, safe model-based RL can achieve nearly zero-cost performance and effectively manage the trade-off between performance and safety. Nevertheless, prior works still pose safety challenges due to the online exploration in real-world deployment. To address this, some offline RL methods have emerged as solutions, which learn from a static dataset in a safe way by avoiding interactions with the environment. In this paper, we aim to further enhance safety during the deployment stage for vision-based robotic tasks by fine-tuning an offline-trained policy. We incorporate in-sample optimization, model-based policy expansion, and reachability guidance to construct a safe offline-to-online framework. Moreover, our method proves to improve the generalization of offline policy in unseen safety-constrained scenarios. Finally, the efficiency of our method is validated on simulation benchmarks with five vision-only tasks and a real robot by solving some deployment problems using limited data.
Read more7/9/2024

0
Strategically Conservative Q-Learning
Yutaka Shimizu, Joey Hong, Sergey Levine, Masayoshi Tomizuka
Offline reinforcement learning (RL) is a compelling paradigm to extend RL's practical utility by leveraging pre-collected, static datasets, thereby avoiding the limitations associated with collecting online interactions. The major difficulty in offline RL is mitigating the impact of approximation errors when encountering out-of-distribution (OOD) actions; doing so ineffectively will lead to policies that prefer OOD actions, which can lead to unexpected and potentially catastrophic results. Despite the variety of works proposed to address this issue, they tend to excessively suppress the value function in and around OOD regions, resulting in overly pessimistic value estimates. In this paper, we propose a novel framework called Strategically Conservative Q-Learning (SCQ) that distinguishes between OOD data that is easy and hard to estimate, ultimately resulting in less conservative value estimates. Our approach exploits the inherent strengths of neural networks to interpolate, while carefully navigating their limitations in extrapolation, to obtain pessimistic yet still property calibrated value estimates. Theoretical analysis also shows that the value function learned by SCQ is still conservative, but potentially much less so than that of Conservative Q-learning (CQL). Finally, extensive evaluation on the D4RL benchmark tasks shows our proposed method outperforms state-of-the-art methods. Our code is available through url{https://github.com/purewater0901/SCQ}.
Read more6/10/2024

0
Pessimism Meets Risk: Risk-Sensitive Offline Reinforcement Learning
Dake Zhang, Boxiang Lyu, Shuang Qiu, Mladen Kolar, Tong Zhang
We study risk-sensitive reinforcement learning (RL), a crucial field due to its ability to enhance decision-making in scenarios where it is essential to manage uncertainty and minimize potential adverse outcomes. Particularly, our work focuses on applying the entropic risk measure to RL problems. While existing literature primarily investigates the online setting, there remains a large gap in understanding how to efficiently derive a near-optimal policy based on this risk measure using only a pre-collected dataset. We center on the linear Markov Decision Process (MDP) setting, a well-regarded theoretical framework that has yet to be examined from a risk-sensitive standpoint. In response, we introduce two provably sample-efficient algorithms. We begin by presenting a risk-sensitive pessimistic value iteration algorithm, offering a tight analysis by leveraging the structure of the risk-sensitive performance measure. To further improve the obtained bounds, we propose another pessimistic algorithm that utilizes variance information and reference-advantage decomposition, effectively improving both the dependence on the space dimension $d$ and the risk-sensitivity factor. To the best of our knowledge, we obtain the first provably efficient risk-sensitive offline RL algorithms.
Read more7/11/2024