FOSP: Fine-tuning Offline Safe Policy through World Models

0
Sign in to get full access
Overview
- This paper presents a novel technique called FOSP (Fine-tuning Offline Safe Policy through World Models) for improving the safety of reinforcement learning policies.
- The key idea is to use a "world model" - a model that can predict the future state of the environment - to identify and avoid unsafe actions during policy training.
- The authors show that FOSP can help learn safer policies compared to standard offline reinforcement learning methods, particularly in complex environments with high-dimensional state spaces.
Plain English Explanation
The researchers describe a new approach called FOSP that can help make reinforcement learning systems safer and more reliable. Reinforcement learning is a type of machine learning where an agent learns to make good decisions by interacting with an environment and receiving rewards or penalties.
One challenge with reinforcement learning is that the agent may learn policies that are unsafe or risky, especially in complex environments. FOSP addresses this by using a "world model" - a neural network that can predict what will happen in the environment based on the agent's actions. The world model is used to identify potentially unsafe actions during training, and the agent is then encouraged to avoid those actions.
This allows the agent to learn a policy that is both effective at completing its task and safe, avoiding dangerous or undesirable outcomes. The authors show that FOSP outperforms standard offline reinforcement learning techniques, particularly in complex environments with high-dimensional state spaces where it can be harder to learn safe policies.
The key innovation of FOSP is this use of the world model to guide the agent towards safer actions during training. This helps the agent learn a policy that is both capable and reliable, without the risks associated with naive reinforcement learning approaches. The model-based reinforcement learning and zero-shot safety prediction techniques developed in related work laid the groundwork for this approach.
Technical Explanation
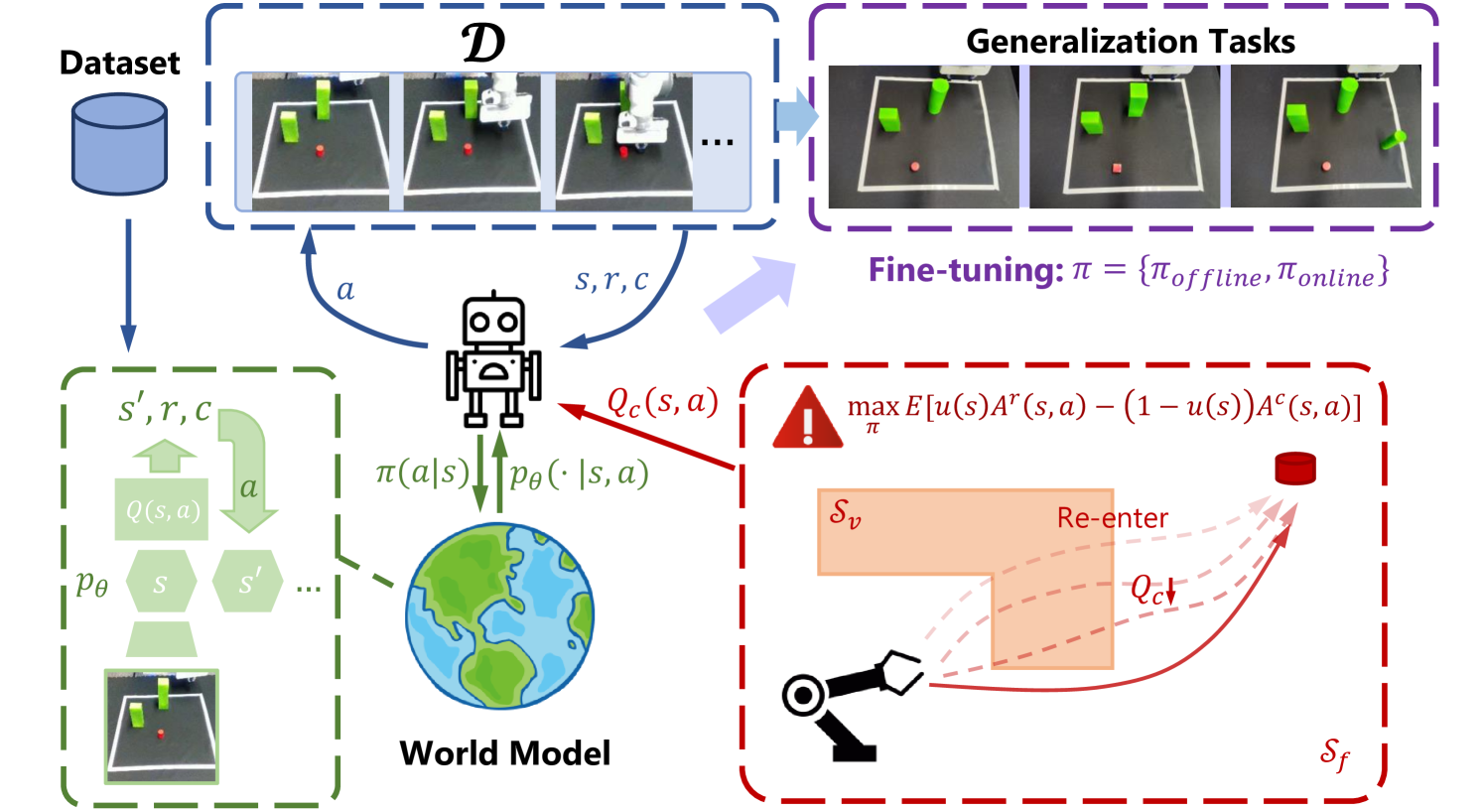
The core idea behind FOSP is to use a learned "world model" - a neural network that can predict the future state of the environment given the current state and an action - to identify and avoid unsafe actions during the policy training process.
The FOSP algorithm works as follows:
- Train a world model to predict future environment states from the current state and a proposed action.
- Use the world model to evaluate the safety of each possible action the agent could take in the current state.
- During policy training, encourage the agent to select actions that the world model deems safe, while still optimizing for task performance.
This allows the agent to learn a policy that is both effective at completing its task and safe, avoiding dangerous or undesirable outcomes. The authors show that FOSP outperforms standard offline reinforcement learning techniques, particularly in complex high-dimensional environments where learning safe policies is challenging.
The towards robust policy and gameplay filters approaches from related work use similar ideas of incorporating safety considerations into the policy learning process. The equivariant offline reinforcement learning technique also leverages learned dynamics models to improve offline RL.
Critical Analysis
The FOSP approach represents an interesting and potentially important advance in making reinforcement learning systems more reliable and safe. By incorporating a learned world model to guide the agent towards safer actions, the authors show that they can learn policies that are both capable and robust.
However, there are a few limitations and areas for future work:
- The world model used in FOSP may not be perfectly accurate, especially in complex, high-dimensional environments. This could lead to the agent learning to avoid actions that are actually safe, or vice versa.
- The authors only evaluate FOSP on a limited set of simulated environments. More testing is needed to understand how well it generalizes to real-world problems with greater complexity and uncertainty.
- The specific safety criteria used to evaluate actions in the world model are fairly simple. More sophisticated safety metrics or constraints could potentially lead to even safer policies.
Overall, FOSP is a promising approach that merits further research and development. Continued progress in safe reinforcement learning is crucial for deploying these powerful techniques in real-world applications where safety is paramount.
Conclusion
The FOSP technique presented in this paper offers a novel way to improve the safety of reinforcement learning policies by leveraging a learned world model to identify and avoid unsafe actions during training. By guiding the agent towards safer decisions, FOSP can learn policies that are both effective at completing their task and reliable in complex environments.
This work builds on prior advances in model-based reinforcement learning, zero-shot safety prediction, and equivariant offline reinforcement learning, demonstrating how learned dynamics models can be leveraged to enhance the safety and robustness of reinforcement learning agents. As these techniques continue to mature, they hold great promise for enabling the safe and reliable deployment of powerful AI systems in high-stakes real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FOSP: Fine-tuning Offline Safe Policy through World Models
Chenyang Cao, Yucheng Xin, Silang Wu, Longxiang He, Zichen Yan, Junbo Tan, Xueqian Wang
Model-based Reinforcement Learning (RL) has shown its high training efficiency and capability of handling high-dimensional tasks. Regarding safety issues, safe model-based RL can achieve nearly zero-cost performance and effectively manage the trade-off between performance and safety. Nevertheless, prior works still pose safety challenges due to the online exploration in real-world deployment. To address this, some offline RL methods have emerged as solutions, which learn from a static dataset in a safe way by avoiding interactions with the environment. In this paper, we aim to further enhance safety during the deployment stage for vision-based robotic tasks by fine-tuning an offline-trained policy. We incorporate in-sample optimization, model-based policy expansion, and reachability guidance to construct a safe offline-to-online framework. Moreover, our method proves to improve the generalization of offline policy in unseen safety-constrained scenarios. Finally, the efficiency of our method is validated on simulation benchmarks with five vision-only tasks and a real robot by solving some deployment problems using limited data.
Read more7/9/2024

0
Sparsity-based Safety Conservatism for Constrained Offline Reinforcement Learning
Minjae Cho, Chuangchuang Sun
Reinforcement Learning (RL) has made notable success in decision-making fields like autonomous driving and robotic manipulation. Yet, its reliance on real-time feedback poses challenges in costly or hazardous settings. Furthermore, RL's training approach, centered on on-policy sampling, doesn't fully capitalize on data. Hence, Offline RL has emerged as a compelling alternative, particularly in conducting additional experiments is impractical, and abundant datasets are available. However, the challenge of distributional shift (extrapolation), indicating the disparity between data distributions and learning policies, also poses a risk in offline RL, potentially leading to significant safety breaches due to estimation errors (interpolation). This concern is particularly pronounced in safety-critical domains, where real-world problems are prevalent. To address both extrapolation and interpolation errors, numerous studies have introduced additional constraints to confine policy behavior, steering it towards more cautious decision-making. While many studies have addressed extrapolation errors, fewer have focused on providing effective solutions for tackling interpolation errors. For example, some works tackle this issue by incorporating potential cost-maximizing optimization by perturbing the original dataset. However, this, involving a bi-level optimization structure, may introduce significant instability or complicate problem-solving in high-dimensional tasks. This motivates us to pinpoint areas where hazards may be more prevalent than initially estimated based on the sparsity of available data by providing significant insight into constrained offline RL. In this paper, we present conservative metrics based on data sparsity that demonstrate the high generalizability to any methods and efficacy compared to using bi-level cost-ub-maximization.
Read more7/19/2024
🏅
0
Model-Based Reinforcement Learning with Multi-Task Offline Pretraining
Minting Pan, Yitao Zheng, Yunbo Wang, Xiaokang Yang
Pretraining reinforcement learning (RL) models on offline datasets is a promising way to improve their training efficiency in online tasks, but challenging due to the inherent mismatch in dynamics and behaviors across various tasks. We present a model-based RL method that learns to transfer potentially useful dynamics and action demonstrations from offline data to a novel task. The main idea is to use the world models not only as simulators for behavior learning but also as tools to measure the task relevance for both dynamics representation transfer and policy transfer. We build a time-varying, domain-selective distillation loss to generate a set of offline-to-online similarity weights. These weights serve two purposes: (i) adaptively transferring the task-agnostic knowledge of physical dynamics to facilitate world model training, and (ii) learning to replay relevant source actions to guide the target policy. We demonstrate the advantages of our approach compared with the state-of-the-art methods in Meta-World and DeepMind Control Suite.
Read more6/6/2024
🏅
0
Handling Long-Term Safety and Uncertainty in Safe Reinforcement Learning
Jonas Gunster, Puze Liu, Jan Peters, Davide Tateo
Safety is one of the key issues preventing the deployment of reinforcement learning techniques in real-world robots. While most approaches in the Safe Reinforcement Learning area do not require prior knowledge of constraints and robot kinematics and rely solely on data, it is often difficult to deploy them in complex real-world settings. Instead, model-based approaches that incorporate prior knowledge of the constraints and dynamics into the learning framework have proven capable of deploying the learning algorithm directly on the real robot. Unfortunately, while an approximated model of the robot dynamics is often available, the safety constraints are task-specific and hard to obtain: they may be too complicated to encode analytically, too expensive to compute, or it may be difficult to envision a priori the long-term safety requirements. In this paper, we bridge this gap by extending the safe exploration method, ATACOM, with learnable constraints, with a particular focus on ensuring long-term safety and handling of uncertainty. Our approach is competitive or superior to state-of-the-art methods in final performance while maintaining safer behavior during training.
Read more9/24/2024