Speaker-Smoothed kNN Speaker Adaptation for End-to-End ASR

0

Sign in to get full access
Overview
- The paper presents a novel speaker adaptation technique called "Speaker-Smoothed kNN Speaker Adaptation" for end-to-end automatic speech recognition (ASR) systems.
- The method aims to improve the performance of ASR models on unseen speakers by leveraging a small amount of adaptation data.
- The technique involves using a k-nearest neighbors (kNN) approach to smooth the speaker embeddings of the adaptation data, which are then used to update the ASR model's parameters.
Plain English Explanation
The paper describes a way to help speech recognition systems work better for people the system hasn't heard from before. Speech recognition models are often trained on a lot of speech data, but they can struggle when they encounter a new speaker they haven't been exposed to before.
The researchers' approach involves taking a small amount of speech data from the new speaker and using a special technique to "smooth out" the characteristics of that speaker's voice. This smoothed speaker data is then used to update the speech recognition model, allowing it to better recognize the new speaker's voice.
The key idea is to find other speakers in the model's training data who sound similar to the new speaker, and then use that similar speaker data to gently adjust the model's parameters. This helps the model learn the new speaker's voice patterns without completely forgetting what it has learned from all the other speakers.
By leveraging this speaker-smoothed kNN adaptation, the researchers were able to significantly improve the speech recognition accuracy for new speakers, making the system more robust and useful in real-world scenarios.
Technical Explanation
The paper introduces a novel speaker adaptation technique called "Speaker-Smoothed kNN Speaker Adaptation" for end-to-end automatic speech recognition (ASR) systems. The key idea is to leverage a small amount of adaptation data from a new speaker to fine-tune the ASR model, while preserving its knowledge from the original training data.
The approach works as follows:
- The model first extracts speaker embeddings from the adaptation data using a pre-trained speaker encoder.
- It then finds the k nearest neighbors of these speaker embeddings in the original training data.
- The model uses a weighted average of the corresponding hidden representations of these nearest neighbors to update its own parameters, smoothing the adaptation to the new speaker.
This "speaker-smoothed" adaptation technique allows the model to effectively capture the characteristics of the new speaker, while maintaining its overall speech recognition capabilities learned from the diverse training data. The authors demonstrate the effectiveness of this approach through experiments on LibriSpeech and CommonVoice datasets, showing significant improvements in word error rate over traditional adaptation methods.
The authors also analyze the impact of the number of nearest neighbors (k) and the weight distribution used for the smoothing, providing insights into the optimal settings for different adaptation scenarios. This speaker-smoothed kNN adaptation technique can be seen as a promising approach to improve the robustness of ASR systems to new speakers.
Critical Analysis
The paper presents a compelling approach to speaker adaptation for end-to-end ASR systems, and the experimental results demonstrate its effectiveness. However, a few potential limitations and areas for further research are worth considering:
-
The method relies on the availability of a pre-trained speaker encoder, which may not always be accessible or easy to obtain. Exploring ways to integrate the speaker embedding extraction directly into the end-to-end ASR model could make the approach more self-contained and widely applicable.
-
The paper focuses on clean speech data, but in real-world scenarios, speech signals are often corrupted by various types of noise and distortions. Investigating the performance of the speaker-smoothed kNN adaptation under noisy conditions would be an important next step.
-
The authors mention that the optimal number of nearest neighbors (k) and the weight distribution used for smoothing may vary depending on the adaptation scenario. Developing adaptive mechanisms to automatically determine these hyperparameters could further improve the method's robustness and ease of deployment.
-
While the paper demonstrates improvements in word error rate, it would be valuable to also consider other metrics, such as speaker identification accuracy or perceptual speech quality, to gain a more comprehensive understanding of the adaptation technique's impact.
Overall, the speaker-smoothed kNN adaptation approach presented in this paper is a promising step towards more robust and adaptable end-to-end ASR systems, and the authors have identified several interesting directions for future research.
Conclusion
This paper introduces a novel speaker adaptation technique called "Speaker-Smoothed kNN Speaker Adaptation" for end-to-end automatic speech recognition (ASR) systems. The key idea is to leverage a small amount of adaptation data from a new speaker to fine-tune the ASR model, while preserving its knowledge from the original training data.
The method works by using a k-nearest neighbors (kNN) approach to smooth the speaker embeddings of the adaptation data, which are then used to update the ASR model's parameters. This "speaker-smoothed" adaptation technique allows the model to effectively capture the characteristics of the new speaker, while maintaining its overall speech recognition capabilities.
The researchers demonstrate the effectiveness of this approach through experiments on popular speech recognition datasets, showing significant improvements in word error rate over traditional adaptation methods. The paper also provides insights into the optimal settings for the number of nearest neighbors and the weight distribution used for the smoothing process.
Overall, the speaker-smoothed kNN adaptation technique presented in this paper is a promising step towards more robust and adaptable end-to-end ASR systems, with the potential to improve speech recognition performance for a wide range of speakers in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Speaker-Smoothed kNN Speaker Adaptation for End-to-End ASR
Shaojun Li, Daimeng Wei, Jiaxin Guo, ZongYao Li, Zhanglin Wu, Zhiqiang Rao, Yuanchang Luo, Xianghui He, Hao Yang
Despite recent improvements in End-to-End Automatic Speech Recognition (E2E ASR) systems, the performance can degrade due to vocal characteristic mismatches between training and testing data, particularly with limited target speaker adaptation data. We propose a novel speaker adaptation approach Speaker-Smoothed kNN that leverages k-Nearest Neighbors (kNN) retrieval techniques to improve model output by finding correctly pronounced tokens from its pre-built datastore during the decoding phase. Moreover, we utilize x-vector to dynamically adjust kNN interpolation parameters for data sparsity issue. This approach was validated using KeSpeech and MagicData corpora under in-domain and all-domain settings. Our method consistently performs comparably to fine-tuning without the associated performance degradation during speaker changes. Furthermore, in the all-domain setting, our method achieves state-of-the-art results, reducing the CER in both single speaker and multi-speaker test scenarios.
Read more6/12/2024

0
Homogeneous Speaker Features for On-the-Fly Dysarthric and Elderly Speaker Adaptation
Mengzhe Geng, Xurong Xie, Jiajun Deng, Zengrui Jin, Guinan Li, Tianzi Wang, Shujie Hu, Zhaoqing Li, Helen Meng, Xunying Liu
The application of data-intensive automatic speech recognition (ASR) technologies to dysarthric and elderly adult speech is confronted by their mismatch against healthy and nonaged voices, data scarcity and large speaker-level variability. To this end, this paper proposes two novel data-efficient methods to learn homogeneous dysarthric and elderly speaker-level features for rapid, on-the-fly test-time adaptation of DNN/TDNN and Conformer ASR models. These include: 1) speaker-level variance-regularized spectral basis embedding (VR-SBE) features that exploit a special regularization term to enforce homogeneity of speaker features in adaptation; and 2) feature-based learning hidden unit contributions (f-LHUC) transforms that are conditioned on VR-SBE features. Experiments are conducted on four tasks across two languages: the English UASpeech and TORGO dysarthric speech datasets, the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech corpora. The proposed on-the-fly speaker adaptation techniques consistently outperform baseline iVector and xVector adaptation by statistically significant word or character error rate reductions up to 5.32% absolute (18.57% relative) and batch-mode LHUC speaker adaptation by 2.24% absolute (9.20% relative), while operating with real-time factors speeding up to 33.6 times against xVectors during adaptation. The efficacy of the proposed adaptation techniques is demonstrated in a comparison against current ASR technologies including SSL pre-trained systems on UASpeech, where our best system produces a state-of-the-art WER of 23.33%. Analyses show VR-SBE features and f-LHUC transforms are insensitive to speaker-level data quantity in testtime adaptation. T-SNE visualization reveals they have stronger speaker-level homogeneity than baseline iVectors, xVectors and batch-mode LHUC transforms.
Read more7/10/2024

0
Improving Speaker Assignment in Speaker-Attributed ASR for Real Meeting Applications
Can Cui (MULTISPEECH), Imran Ahamad Sheikh (MULTISPEECH), Mostafa Sadeghi (MULTISPEECH), Emmanuel Vincent (MULTISPEECH)
Past studies on end-to-end meeting transcription have focused on model architecture and have mostly been evaluated on simulated meeting data. We present a novel study aiming to optimize the use of a Speaker-Attributed ASR (SA-ASR) system in real-life scenarios, such as the AMI meeting corpus, for improved speaker assignment of speech segments. First, we propose a pipeline tailored to real-life applications involving Voice Activity Detection (VAD), Speaker Diarization (SD), and SA-ASR. Second, we advocate using VAD output segments to fine-tune the SA-ASR model, considering that it is also applied to VAD segments during test, and show that this results in a relative reduction of Speaker Error Rate (SER) up to 28%. Finally, we explore strategies to enhance the extraction of the speaker embedding templates used as inputs by the SA-ASR system. We show that extracting them from SD output rather than annotated speaker segments results in a relative SER reduction up to 20%.
Read more9/6/2024
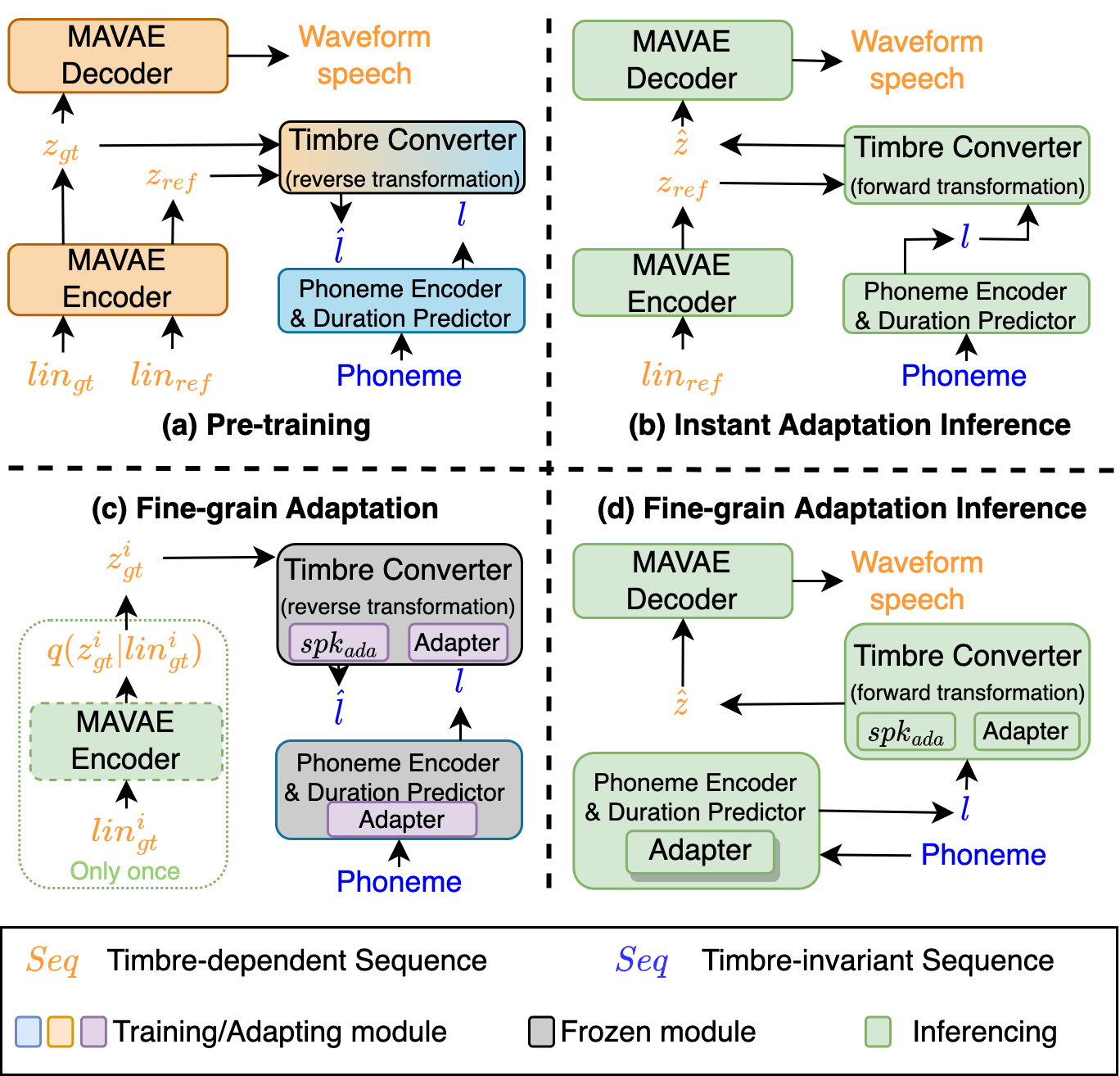
0
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Wenbin Wang, Yang Song, Sanjay Jha
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as instant and fine-grained adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
Read more4/30/2024