HyperTTS: Parameter Efficient Adaptation in Text to Speech using Hypernetworks
2404.04645
0
0
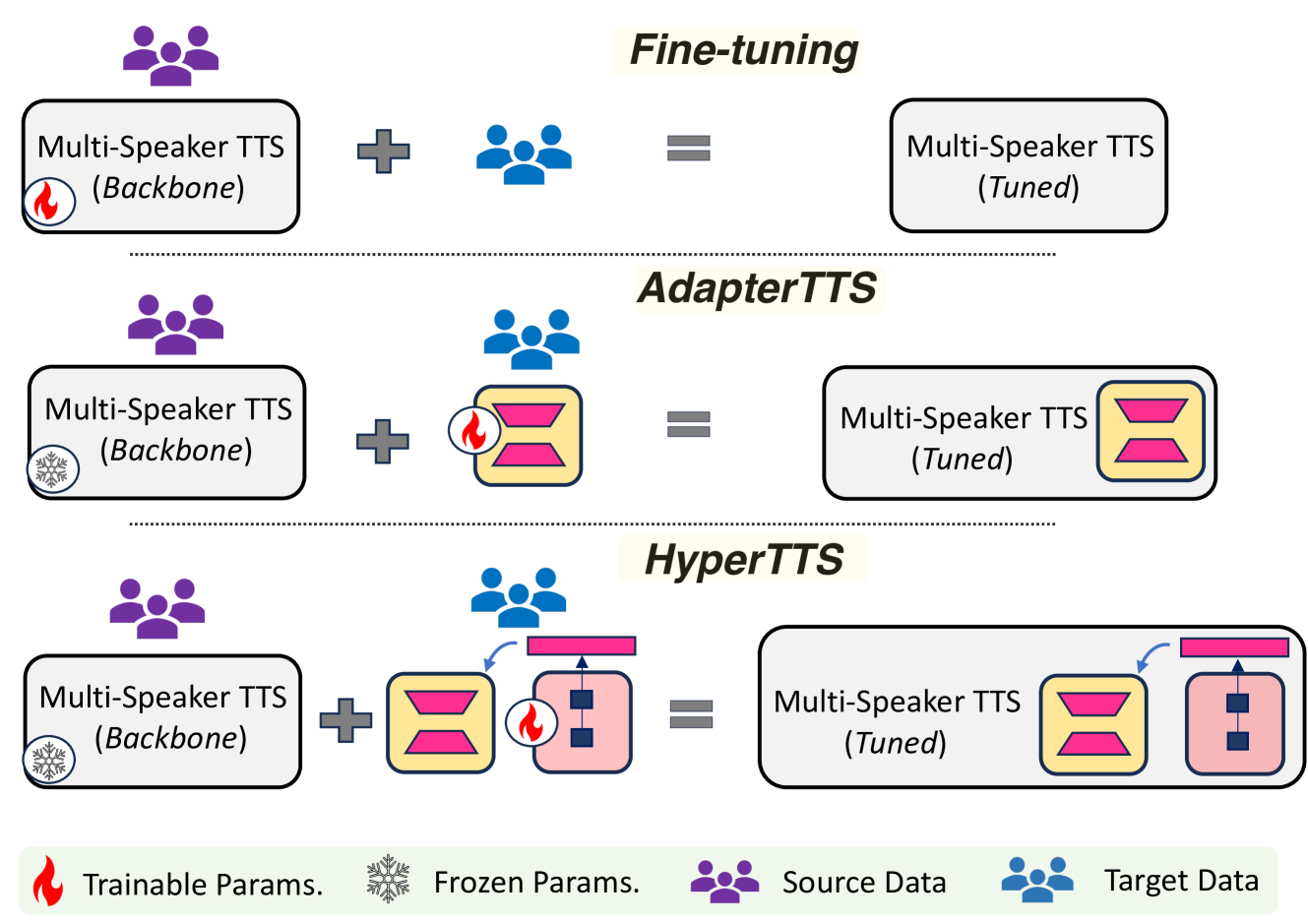
Abstract
Neural speech synthesis, or text-to-speech (TTS), aims to transform a signal from the text domain to the speech domain. While developing TTS architectures that train and test on the same set of speakers has seen significant improvements, out-of-domain speaker performance still faces enormous limitations. Domain adaptation on a new set of speakers can be achieved by fine-tuning the whole model for each new domain, thus making it parameter-inefficient. This problem can be solved by Adapters that provide a parameter-efficient alternative to domain adaptation. Although famous in NLP, speech synthesis has not seen much improvement from Adapters. In this work, we present HyperTTS, which comprises a small learnable network, hypernetwork, that generates parameters of the Adapter blocks, allowing us to condition Adapters on speaker representations and making them dynamic. Extensive evaluations of two domain adaptation settings demonstrate its effectiveness in achieving state-of-the-art performance in the parameter-efficient regime. We also compare different variants of HyperTTS, comparing them with baselines in different studies. Promising results on the dynamic adaptation of adapter parameters using hypernetworks open up new avenues for domain-generic multi-speaker TTS systems. The audio samples and code are available at https://github.com/declare-lab/HyperTTS.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This research paper presents a novel approach called HyperTTS that uses hypernetworks to enable parameter-efficient adaptation in text-to-speech (TTS) models.
• HyperTTS allows for rapid adaptation of TTS models to new voices or speaking styles with a small number of additional trainable parameters, in contrast to traditional fine-tuning approaches that require retraining the entire model.
• The key innovation in HyperTTS is the use of hypernetworks, which are neural networks that generate the weights of another neural network. This allows the TTS model to be quickly adapted by only updating the hypernetwork weights.
Plain English Explanation
• The goal of this research is to make it easier and faster to customize text-to-speech (TTS) models to new voices or speaking styles.
• Traditionally, if you wanted to adapt a TTS model to a new voice, you would need to retrain the entire model on data for that voice, which can be time-consuming and require a lot of computational resources.
• The HyperTTS approach uses a clever trick called hypernetworks to enable parameter-efficient adaptation. Instead of retraining the whole model, the researchers only need to update a small set of hypernetwork weights to adapt the model to a new voice.
• This makes it much faster and more efficient to customize TTS models for different use cases, which could be useful for applications like voice cloning or multilingual TTS.
Technical Explanation
• The HyperTTS model consists of a base TTS model along with a hypernetwork that generates the weights of certain layers in the base model.
• To adapt HyperTTS to a new voice, the researchers only need to fine-tune the hypernetwork weights, leaving the base TTS model largely unchanged. This is in contrast to standard TTS fine-tuning, which would require retraining the entire model.
• The researchers evaluate HyperTTS on several benchmarks, including adaptation to new voices and zero-shot transfer to unseen speakers. They show that HyperTTS can match the performance of fully fine-tuned models while using orders of magnitude fewer trainable parameters.
• The key technical innovation in HyperTTS is the use of hypernetworks, which enable efficient model adaptation by only updating a small subset of the network weights.
Critical Analysis
• The paper provides a thorough evaluation of HyperTTS and demonstrates its advantages over standard fine-tuning approaches. However, it does not deeply explore the limitations of the hypernetwork approach.
• For example, the authors do not investigate how the hypernetwork architecture or training procedure might impact the quality of the adapted TTS models. There could be edge cases or instabilities that the paper does not uncover.
• Additionally, the paper focuses on adapting to new voices, but does not explore how HyperTTS might perform for other types of adaptation, such as changes in speaking style, emotion, or language. Further research would be needed to understand the broader applicability of the method.
• Overall, the HyperTTS approach is a promising innovation in parameter-efficient model adaptation, but more work is needed to fully understand its strengths, weaknesses, and edge cases.
Conclusion
• The HyperTTS paper presents a novel hypernetwork-based approach for efficiently adapting text-to-speech models to new voices and speaking styles.
• By only updating a small set of hypernetwork weights, HyperTTS can match the performance of fully fine-tuned TTS models while using orders of magnitude fewer trainable parameters.
• This parameter-efficient adaptation capability could enable more flexible and cost-effective deployment of TTS systems in a variety of real-world applications, from voice cloning to multilingual TTS.
• While the paper provides a strong technical foundation, further research is needed to fully understand the limitations and broader applicability of the HyperTTS approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
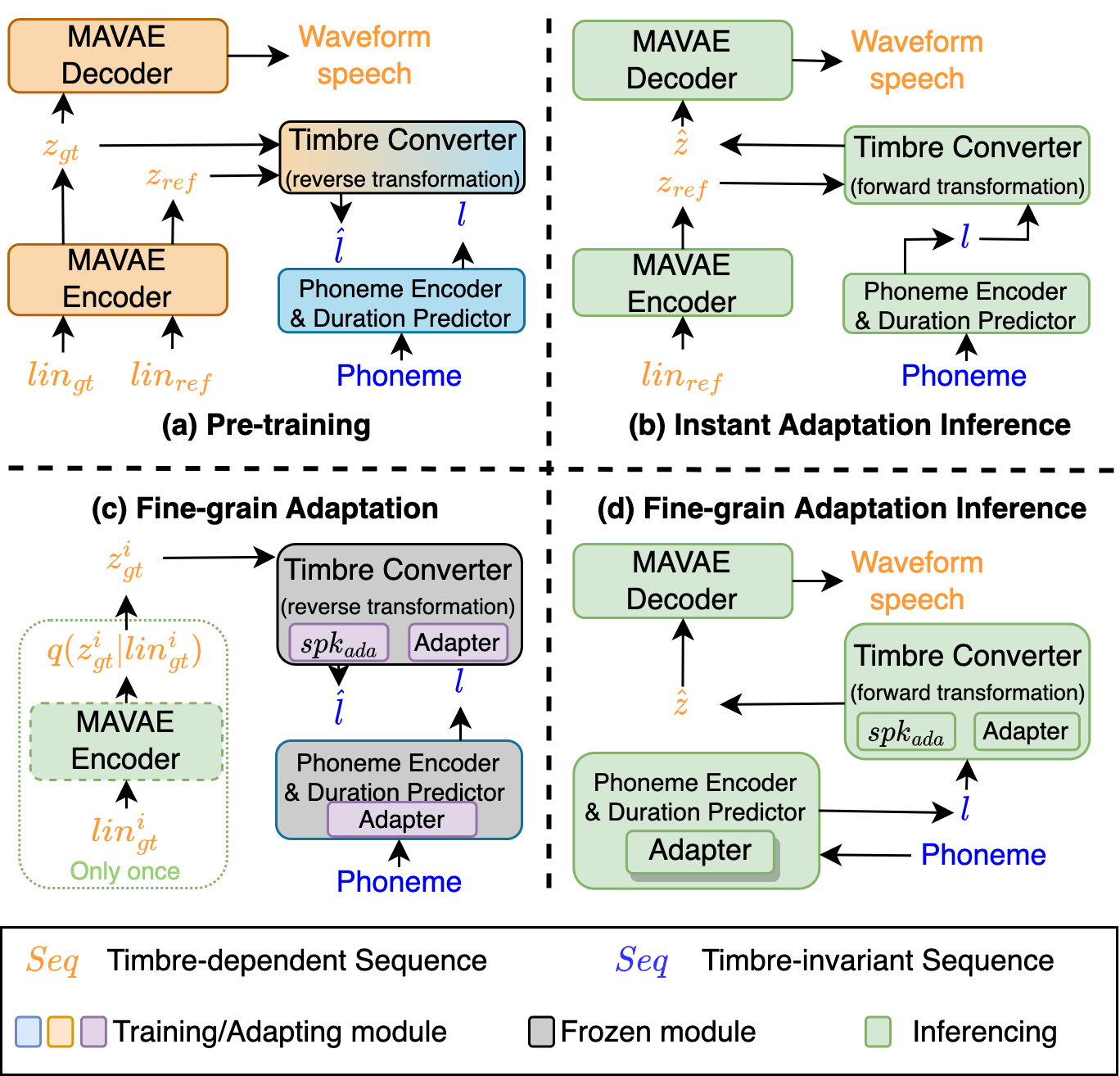
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Wenbin Wang, Yang Song, Sanjay Jha
0
0
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as instant and fine-grained adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
4/30/2024
🌿
Parameter-Efficient Fine-Tuning With Adapters
Keyu Chen, Yuan Pang, Zi Yang
0
0
In the arena of language model fine-tuning, the traditional approaches, such as Domain-Adaptive Pretraining (DAPT) and Task-Adaptive Pretraining (TAPT), although effective, but computational intensive. This research introduces a novel adaptation method utilizing the UniPELT framework as a base and added a PromptTuning Layer, which significantly reduces the number of trainable parameters while maintaining competitive performance across various benchmarks. Our method employs adapters, which enable efficient transfer of pretrained models to new tasks with minimal retraining of the base model parameters. We evaluate our approach using three diverse datasets: the GLUE benchmark, a domain-specific dataset comprising four distinct areas, and the Stanford Question Answering Dataset 1.1 (SQuAD). Our results demonstrate that our customized adapter-based method achieves performance comparable to full model fine-tuning, DAPT+TAPT and UniPELT strategies while requiring fewer or equivalent amount of parameters. This parameter efficiency not only alleviates the computational burden but also expedites the adaptation process. The study underlines the potential of adapters in achieving high performance with significantly reduced resource consumption, suggesting a promising direction for future research in parameter-efficient fine-tuning.
5/10/2024
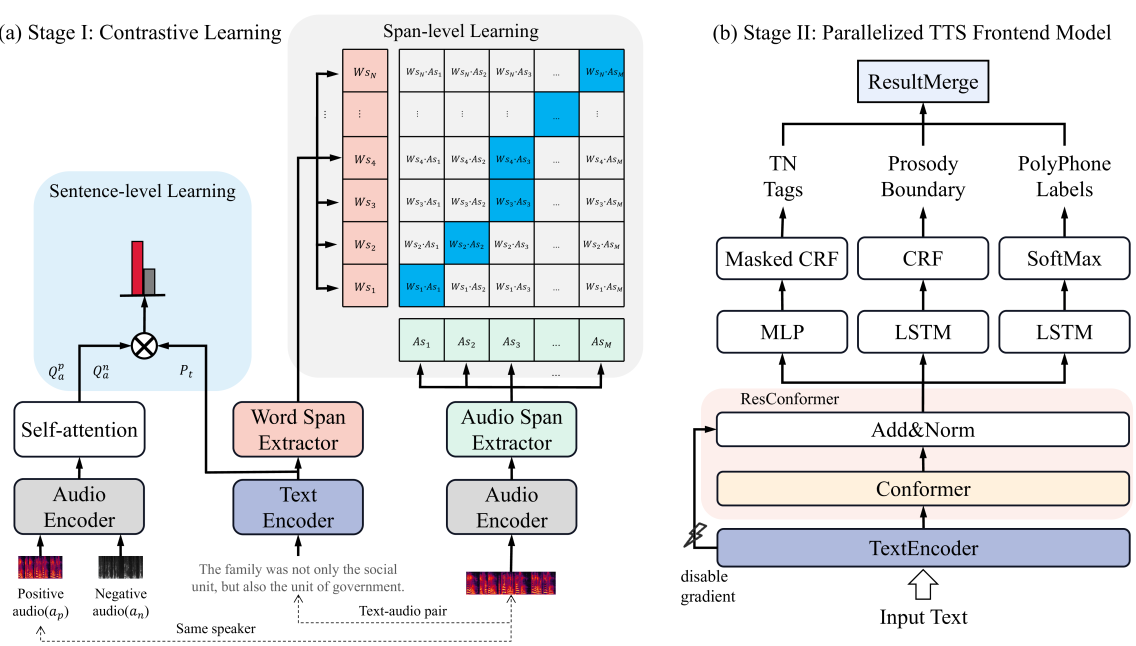
Prior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
Quanxiu Wang, Hui Huang, Mingjie Wang, Yong Dai, Jinzuomu Zhong, Benlai Tang
0
0
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.
4/16/2024

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024