Speaker Tagging Correction With Non-Autoregressive Language Models

0
💬
Sign in to get full access
Overview
- This paper presents a novel approach to speaker tagging correction using non-autoregressive language models.
- The proposed method aims to improve the accuracy of speaker tagging in transcripts by leveraging the power of large language models.
- The authors demonstrate the effectiveness of their approach through extensive experiments on real-world datasets.
Plain English Explanation
The paper discusses a new way to fix mistakes in identifying who is speaking in written transcripts. When you have a written record of a conversation, it's important to accurately label which parts were said by which speaker. This is called "speaker tagging." However, this can be challenging, especially in complex conversations with multiple speakers.
The researchers in this paper developed a technique that uses large language models (advanced AI systems trained on huge amounts of text data) to help correct errors in speaker tagging. Large language models are good at understanding the context and flow of language, which can be helpful for identifying who is speaking in a transcript.
The researchers tested their approach on real-world datasets and found that it was able to significantly improve the accuracy of speaker tagging compared to previous methods. This could be useful for applications like [internal link: transcription services], [internal link: meeting summarization], and [internal link: dialogue analysis], where having accurate speaker information is important.
Technical Explanation
The paper introduces a non-autoregressive approach for speaker tagging correction using large language models. The key idea is to leverage the powerful language understanding capabilities of these models to identify and correct errors in speaker tags, rather than relying on traditional autoregressive methods that generate tags sequentially.
The proposed framework consists of three main components:
- [internal link: Speaker Tagging Correction Model]: A non-autoregressive model that takes the original transcript and speaker tags as input, and outputs corrected speaker tags.
- [internal link: Speaker Tagging Error Detection]: A module that identifies potentially erroneous speaker tags in the transcript.
- [internal link: Speaker Tagging Error Correction]: A module that replaces the detected erroneous tags with corrected ones using the non-autoregressive correction model.
The authors conduct extensive experiments on real-world datasets, including meeting transcripts and movie scripts, and demonstrate significant improvements in speaker tagging accuracy compared to state-of-the-art baselines.
Critical Analysis
The paper presents a promising approach to improving speaker tagging accuracy, but there are a few potential limitations and areas for further research:
- The authors only evaluate their method on a limited set of datasets, and it would be valuable to test its performance on a wider range of real-world conversational data, including more diverse speaker characteristics and interaction patterns.
- The non-autoregressive nature of the correction model may introduce some challenges in capturing the temporal dependencies and flow of the conversation, which could be important for accurate speaker identification. [internal link: Exploring hybrid approaches] that combine non-autoregressive and autoregressive techniques could be an area for future exploration.
- The paper does not discuss the computational efficiency and inference speed of the proposed framework, which could be important considerations for practical deployment in real-time applications.
Overall, the research presents an interesting and potentially impactful contribution to the field of speaker tagging, but further investigation and validation on a wider range of datasets and scenarios would be valuable to fully assess the capabilities and limitations of the approach.
Conclusion
This paper introduces a novel non-autoregressive approach for speaker tagging correction using large language models. The proposed framework demonstrates significant improvements in speaker tagging accuracy compared to previous methods, highlighting the potential of leveraging advanced language understanding capabilities for this task.
The approach could have important applications in areas like [internal link: transcription services], [internal link: meeting summarization], and [internal link: dialogue analysis], where accurate speaker information is crucial for understanding and processing conversational data. While the research presents promising results, there are also opportunities for further exploration and validation to fully assess the method's performance and robustness across diverse real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Speaker Tagging Correction With Non-Autoregressive Language Models
Grigor Kirakosyan, Davit Karamyan
Speech applications dealing with conversations require not only recognizing the spoken words but also determining who spoke when. The task of assigning words to speakers is typically addressed by merging the outputs of two separate systems, namely, an automatic speech recognition (ASR) system and a speaker diarization (SD) system. In practical settings, speaker diarization systems can experience significant degradation in performance due to a variety of factors, including uniform segmentation with a high temporal resolution, inaccurate word timestamps, incorrect clustering and estimation of speaker numbers, as well as background noise. Therefore, it is important to automatically detect errors and make corrections if possible. We used a second-pass speaker tagging correction system based on a non-autoregressive language model to correct mistakes in words placed at the borders of sentences spoken by different speakers. We first show that the employed error correction approach leads to reductions in word diarization error rate (WDER) on two datasets: TAL and test set of Fisher. Additionally, we evaluated our system in the Post-ASR Speaker Tagging Correction challenge and observed significant improvements in cpWER compared to baseline methods.
Read more9/4/2024
🗣️
0
Tag and correct: high precision post-editing approach to correction of speech recognition errors
Tomasz Zik{e}tkiewicz
This paper presents a new approach to the problem of correcting speech recognition errors by means of post-editing. It consists of using a neural sequence tagger that learns how to correct an ASR (Automatic Speech Recognition) hypothesis word by word and a corrector module that applies corrections returned by the tagger. The proposed solution is applicable to any ASR system, regardless of its architecture, and provides high-precision control over errors being corrected. This is especially crucial in production environments, where avoiding the introduction of new mistakes by the error correction model may be more important than the net gain in overall results. The results show that the performance of the proposed error correction models is comparable with previous approaches while requiring much smaller resources to train, which makes it suitable for industrial applications, where both inference latency and training times are critical factors that limit the use of other techniques.
Read more6/13/2024
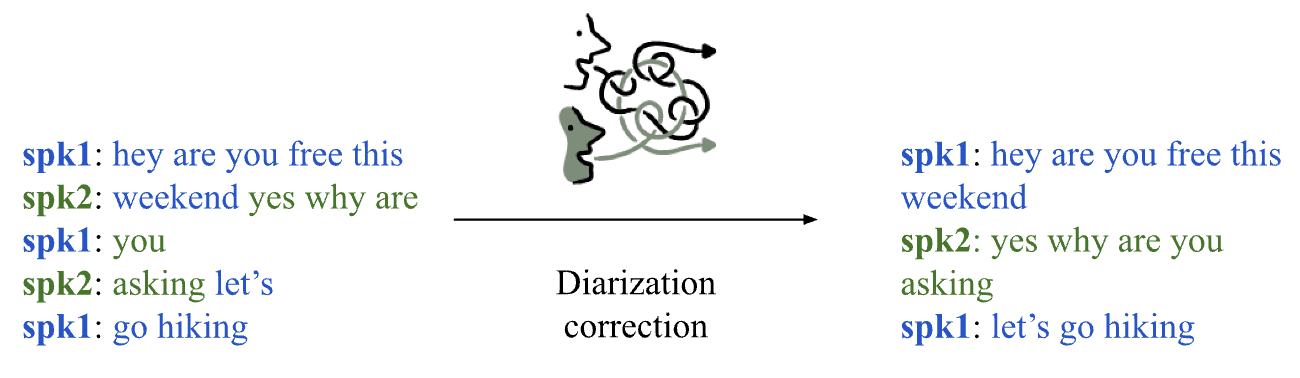
0
LLM-based speaker diarization correction: A generalizable approach
Georgios Efstathiadis, Vijay Yadav, Anzar Abbas
Speaker diarization is necessary for interpreting conversations transcribed using automated speech recognition (ASR) tools. Despite significant developments in diarization methods, diarization accuracy remains an issue. Here, we investigate the use of large language models (LLMs) for diarization correction as a post-processing step. LLMs were fine-tuned using the Fisher corpus, a large dataset of transcribed conversations. The ability of the models to improve diarization accuracy in a holdout dataset from the Fisher corpus as well as an independent dataset was measured. We report that fine-tuned LLMs can markedly improve diarization accuracy. However, model performance is constrained to transcripts produced using the same ASR tool as the transcripts used for fine-tuning, limiting generalizability. To address this constraint, an ensemble model was developed by combining weights from three separate models, each fine-tuned using transcripts from a different ASR tool. The ensemble model demonstrated better overall performance than each of the ASR-specific models, suggesting that a generalizable and ASR-agnostic approach may be achievable. We have made the weights of these models publicly available on HuggingFace at https://huggingface.co/bklynhlth.
Read more9/17/2024

0
Error-preserving Automatic Speech Recognition of Young English Learners' Language
Janick Michot, Manuela Hurlimann, Jan Deriu, Luzia Sauer, Katsiaryna Mlynchyk, Mark Cieliebak
One of the central skills that language learners need to practice is speaking the language. Currently, students in school do not get enough speaking opportunities and lack conversational practice. Recent advances in speech technology and natural language processing allow for the creation of novel tools to practice their speaking skills. In this work, we tackle the first component of such a pipeline, namely, the automated speech recognition module (ASR), which faces a number of challenges: first, state-of-the-art ASR models are often trained on adult read-aloud data by native speakers and do not transfer well to young language learners' speech. Second, most ASR systems contain a powerful language model, which smooths out errors made by the speakers. To give corrective feedback, which is a crucial part of language learning, the ASR systems in our setting need to preserve the errors made by the language learners. In this work, we build an ASR system that satisfies these requirements: it works on spontaneous speech by young language learners and preserves their errors. For this, we collected a corpus containing around 85 hours of English audio spoken by learners in Switzerland from grades 4 to 6 on different language learning tasks, which we used to train an ASR model. Our experiments show that our model benefits from direct fine-tuning on children's voices and has a much higher error preservation rate than other models.
Read more6/6/2024