Specialty-Oriented Generalist Medical AI for Chest CT Screening

0
🤖
Sign in to get full access
Overview
- Modern medical records include vast amounts of multimodal data, including free-text clinical data and medical imaging from radiology, cardiology, and digital pathology.
- Fully leveraging this "big data" requires multitasking, as important insights may be overlooked when focusing on individual tasks.
- Despite AI success in single-modal tasks, progress in developing generalist medical AI systems that can combine multimodal data for multitasks has been slow, due to challenges in data curation and model architecture.
Plain English Explanation
Medical records today contain a huge amount of different kinds of data - there are written notes from doctors and nurses, as well as all kinds of medical images like X-rays, CT scans, and pathology slides. To get the most value out of all this information, we need AI systems that can understand and analyze all these different data types together, rather than looking at them one by one.
The challenge is that building these kinds of "generalist" medical AI models is really hard. There are two main problems: First, curating and organizing all this diverse medical data for the AI to learn from is extremely complex. Second, designing the AI model architecture to effectively combine and make sense of all these different data sources is a significant technical challenge.
This paper proposes a new kind of medical AI model called "M3FM" that aims to overcome these obstacles. M3FM is trained on a huge dataset covering 49 different types of medical data, and it can tackle 17 different clinical tasks, like lung cancer screening and related medical problems. The key innovation is using a "multimodal question-answering" approach, which allows the model to flexibly integrate the diverse data sources and apply its knowledge to new tasks.
Technical Explanation
The researchers curated a comprehensive multimodal dataset covering 49 different types of clinical data, including 163,725 chest CT scans, and 17 medical tasks related to lung cancer screening. They then developed a multimodal question-answering framework as the training and inference strategy for their M3FM model.
This approach allows M3FM to synergize information from the different data modalities (e.g. text, images) and perform a wide range of clinical tasks, simply by prompting the model with free-text questions. The researchers found that M3FM consistently outperformed state-of-the-art single-modal, task-specific models. It was able to identify the most informative multimodal data elements for each task, and could also flexibly adapt to new tasks using a small amount of additional training data.
By designing M3FM as a "specialty-oriented generalist" medical AI, the researchers aim to pave the way for similar breakthroughs across different areas of medicine, helping to close the gap between highly specialized AI models and true generalist systems that can handle diverse clinical challenges.
Critical Analysis
The paper presents a promising approach to developing more versatile and capable medical AI models. The authors acknowledge that significant challenges remain, particularly around the immense complexity of curating and harmonizing large-scale multimodal medical datasets.
Additionally, while M3FM demonstrated strong performance, the paper does not provide a deep analysis of its limitations or failure cases. Further research would be needed to fully understand the model's strengths, weaknesses, and potential biases.
It's also worth considering how effectively a single, generalist model like M3FM could be deployed and integrated into real-world clinical workflows, compared to more specialized AI agents or systems designed for specific tasks. The tradeoffs between generalization and task-specific optimization would merit further exploration.
Overall, this research represents an important step towards building more comprehensive and flexible medical AI capabilities. However, significant challenges remain before such models could be reliably deployed to support clinical decision-making and population health management at scale.
Conclusion
This paper proposes a novel "medical multimodal-multitask foundation model" (M3FM) that aims to overcome the limitations of existing single-modal, task-specific medical AI systems. By curating a large-scale multimodal dataset and developing a flexible question-answering framework, the researchers have demonstrated the potential for more generalist AI models to tackle diverse clinical challenges.
While significant technical hurdles remain, this work represents an important milestone in the quest to develop AI systems that can truly harness the wealth of data contained in modern medical records. If successful, such generalist medical AI models could have far-reaching impacts on clinical practice, population health, and the future of healthcare.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Specialty-Oriented Generalist Medical AI for Chest CT Screening
Chuang Niu, Qing Lyu, Christopher D. Carothers, Parisa Kaviani, Josh Tan, Pingkun Yan, Mannudeep K. Kalra, Christopher T. Whitlow, Ge Wang
Modern medical records include a vast amount of multimodal free text clinical data and imaging data from radiology, cardiology, and digital pathology. Fully mining such big data requires multitasking; otherwise, occult but important aspects may be overlooked, adversely affecting clinical management and population healthcare. Despite remarkable successes of AI in individual tasks with single-modal data, the progress in developing generalist medical AI remains relatively slow to combine multimodal data for multitasks because of the dual challenges of data curation and model architecture. The data challenge involves querying and curating multimodal structured and unstructured text, alphanumeric, and especially 3D tomographic scans on an individual patient level for real-time decisions and on a scale to estimate population health statistics. The model challenge demands a scalable and adaptable network architecture to integrate multimodal datasets for diverse clinical tasks. Here we propose the first-of-its-kind medical multimodal-multitask foundation model (M3FM) with application in lung cancer screening and related tasks. After we curated a comprehensive multimodal multitask dataset consisting of 49 clinical data types including 163,725 chest CT series and 17 medical tasks involved in LCS, we develop a multimodal question-answering framework as a unified training and inference strategy to synergize multimodal information and perform multiple tasks via free-text prompting. M3FM consistently outperforms the state-of-the-art single-modal task-specific models, identifies multimodal data elements informative for clinical tasks and flexibly adapts to new tasks with a small out-of-distribution dataset. As a specialty-oriented generalist medical AI model, M3FM paves the way for similar breakthroughs in other areas of medicine, closing the gap between specialists and the generalist.
Read more4/16/2024
0
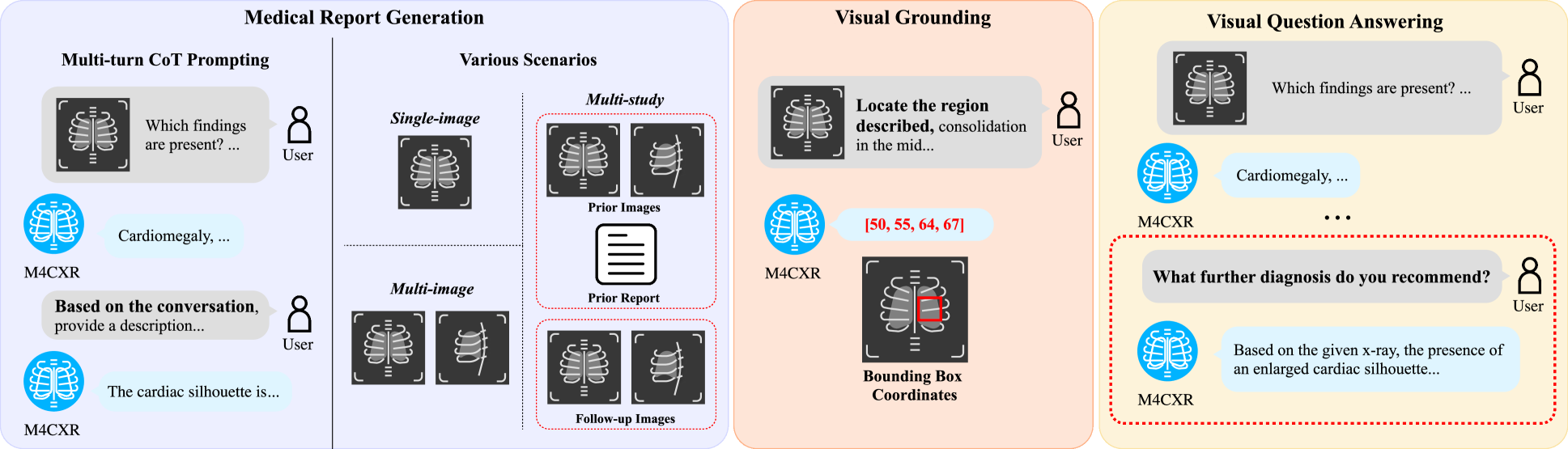
M4CXR: Exploring Multi-task Potentials of Multi-modal Large Language Models for Chest X-ray Interpretation
Jonggwon Park, Soobum Kim, Byungmu Yoon, Jihun Hyun, Kyoyun Choi
The rapid evolution of artificial intelligence, especially in large language models (LLMs), has significantly impacted various domains, including healthcare. In chest X-ray (CXR) analysis, previous studies have employed LLMs, but with limitations: either underutilizing the multi-tasking capabilities of LLMs or lacking clinical accuracy. This paper presents M4CXR, a multi-modal LLM designed to enhance CXR interpretation. The model is trained on a visual instruction-following dataset that integrates various task-specific datasets in a conversational format. As a result, the model supports multiple tasks such as medical report generation (MRG), visual grounding, and visual question answering (VQA). M4CXR achieves state-of-the-art clinical accuracy in MRG by employing a chain-of-thought prompting strategy, in which it identifies findings in CXR images and subsequently generates corresponding reports. The model is adaptable to various MRG scenarios depending on the available inputs, such as single-image, multi-image, and multi-study contexts. In addition to MRG, M4CXR performs visual grounding at a level comparable to specialized models and also demonstrates outstanding performance in VQA. Both quantitative and qualitative assessments reveal M4CXR's versatility in MRG, visual grounding, and VQA, while consistently maintaining clinical accuracy.
Read more8/30/2024

0
MultiMed: Massively Multimodal and Multitask Medical Understanding
Shentong Mo, Paul Pu Liang
Biomedical data is inherently multimodal, consisting of electronic health records, medical imaging, digital pathology, genome sequencing, wearable sensors, and more. The application of artificial intelligence tools to these multifaceted sensing technologies has the potential to revolutionize the prognosis, diagnosis, and management of human health and disease. However, current approaches to biomedical AI typically only train and evaluate with one or a small set of medical modalities and tasks. This limitation hampers the development of comprehensive tools that can leverage the rich interconnected information across many heterogeneous biomedical sensors. To address this challenge, we present MultiMed, a benchmark designed to evaluate and enable large-scale learning across a wide spectrum of medical modalities and tasks. MultiMed consists of 2.56 million samples across ten medical modalities such as medical reports, pathology, genomics, and protein data, and is structured into eleven challenging tasks, including disease prognosis, protein structure prediction, and medical question answering. Using MultiMed, we conduct comprehensive experiments benchmarking state-of-the-art unimodal, multimodal, and multitask models. Our analysis highlights the advantages of training large-scale medical models across many related modalities and tasks. Moreover, MultiMed enables studies of generalization across related medical concepts, robustness to real-world noisy data and distribution shifts, and novel modality combinations to improve prediction performance. MultiMed will be publicly available and regularly updated and welcomes inputs from the community.
Read more8/26/2024
0
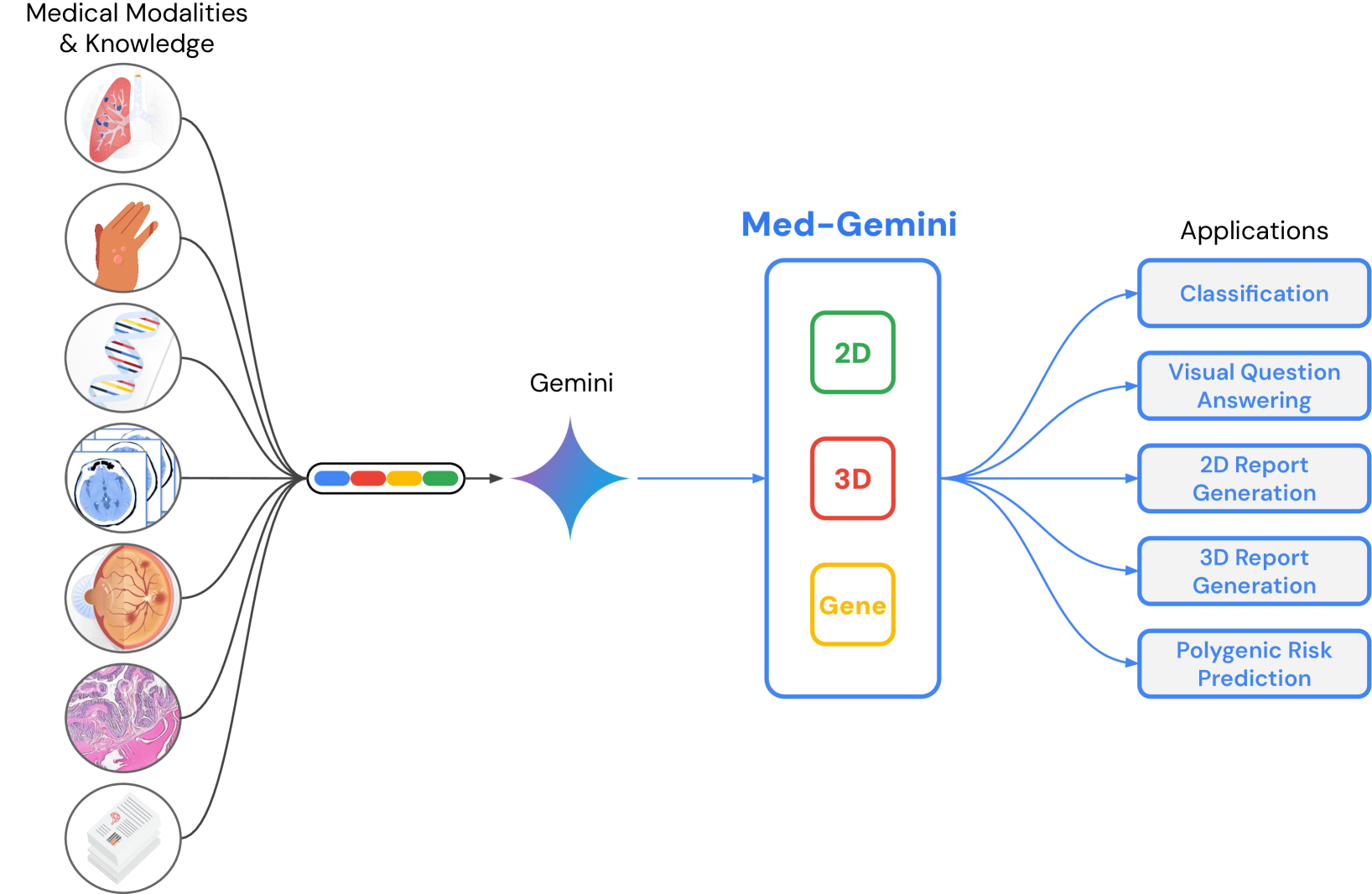
Advancing Multimodal Medical Capabilities of Gemini
Lin Yang, Shawn Xu, Andrew Sellergren, Timo Kohlberger, Yuchen Zhou, Ira Ktena, Atilla Kiraly, Faruk Ahmed, Farhad Hormozdiari, Tiam Jaroensri, Eric Wang, Ellery Wulczyn, Fayaz Jamil, Theo Guidroz, Chuck Lau, Siyuan Qiao, Yun Liu, Akshay Goel, Kendall Park, Arnav Agharwal, Nick George, Yang Wang, Ryutaro Tanno, David G. T. Barrett, Wei-Hung Weng, S. Sara Mahdavi, Khaled Saab, Tao Tu, Sreenivasa Raju Kalidindi, Mozziyar Etemadi, Jorge Cuadros, Gregory Sorensen, Yossi Matias, Katherine Chou, Greg Corrado, Joelle Barral, Shravya Shetty, David Fleet, S. M. Ali Eslami, Daniel Tse, Shruthi Prabhakara, Cory McLean, Dave Steiner, Rory Pilgrim, Christopher Kelly, Shekoofeh Azizi, Daniel Golden
Many clinical tasks require an understanding of specialized data, such as medical images and genomics, which is not typically found in general-purpose large multimodal models. Building upon Gemini's multimodal models, we develop several models within the new Med-Gemini family that inherit core capabilities of Gemini and are optimized for medical use via fine-tuning with 2D and 3D radiology, histopathology, ophthalmology, dermatology and genomic data. Med-Gemini-2D sets a new standard for AI-based chest X-ray (CXR) report generation based on expert evaluation, exceeding previous best results across two separate datasets by an absolute margin of 1% and 12%, where 57% and 96% of AI reports on normal cases, and 43% and 65% on abnormal cases, are evaluated as equivalent or better than the original radiologists' reports. We demonstrate the first ever large multimodal model-based report generation for 3D computed tomography (CT) volumes using Med-Gemini-3D, with 53% of AI reports considered clinically acceptable, although additional research is needed to meet expert radiologist reporting quality. Beyond report generation, Med-Gemini-2D surpasses the previous best performance in CXR visual question answering (VQA) and performs well in CXR classification and radiology VQA, exceeding SoTA or baselines on 17 of 20 tasks. In histopathology, ophthalmology, and dermatology image classification, Med-Gemini-2D surpasses baselines across 18 out of 20 tasks and approaches task-specific model performance. Beyond imaging, Med-Gemini-Polygenic outperforms the standard linear polygenic risk score-based approach for disease risk prediction and generalizes to genetically correlated diseases for which it has never been trained. Although further development and evaluation are necessary in the safety-critical medical domain, our results highlight the potential of Med-Gemini across a wide range of medical tasks.
Read more5/7/2024