M4CXR: Exploring Multi-task Potentials of Multi-modal Large Language Models for Chest X-ray Interpretation

0
Sign in to get full access
Overview
- The paper "M4CXR: Exploring Multi-task Potentials of Multi-modal Large Language Models for Chest X-ray Interpretation" investigates the use of multi-modal large language models (LLMs) for various tasks related to chest X-ray interpretation.
- The researchers explore the multi-task potential of these models, assessing their performance on tasks like disease classification, visual question answering, and report generation.
- The paper aims to demonstrate the versatility and effectiveness of multi-modal LLMs in the medical imaging domain, particularly for chest X-ray analysis.
Plain English Explanation
The researchers in this study wanted to see how well large language models that can handle multiple types of data (text, images, etc.) could perform on different tasks related to analyzing chest X-rays. These tasks included things like:
- Identifying diseases or conditions in the X-rays
- Answering questions about the information shown in the X-rays
- Generating reports that describe the key findings in the X-rays
The researchers were interested in exploring the potential of these multi-modal language models to be versatile and effective tools for medical imaging analysis, particularly for chest X-rays. By assessing the models' performance across several different tasks, the researchers hoped to demonstrate the power and flexibility of this approach compared to more traditional, specialized models.
Technical Explanation
The researchers in this study utilized a multi-modal large language model (LLM) called M4CXR, which was pre-trained on a diverse dataset of text and images. They fine-tuned this model on a variety of tasks related to chest X-ray interpretation, including:
- Disease Classification: Identifying the presence of specific diseases or conditions in the X-ray images.
- Visual Question Answering: Answering questions about the information shown in the X-ray images.
- Report Generation: Generating textual reports that summarize the key findings in the X-ray images.
The researchers compared the performance of M4CXR to specialized, single-task models on these different chest X-ray interpretation tasks. Their results demonstrated the strong multi-task capabilities of the multi-modal LLM, which was able to outperform the specialized models on several of the evaluated tasks.
Critical Analysis
The researchers acknowledge several caveats and limitations in their study. For example, they note that the performance of M4CXR may be influenced by the specific dataset and tasks used for fine-tuning, and that further research is needed to understand the generalizability of their findings.
Additionally, the researchers do not provide a detailed analysis of the failure modes or potential biases of the multi-modal LLM. It would be valuable to understand the types of errors the model makes and whether it exhibits any problematic biases, particularly when applied to sensitive medical data.
Another area for further research is the interpretability of the multi-modal LLM's decision-making process. As these models become more widely deployed in clinical settings, it will be important to ensure their outputs can be understood and trusted by medical professionals.
Conclusion
Overall, this study demonstrates the promising potential of multi-modal large language models for tackling a variety of tasks related to chest X-ray interpretation. By leveraging the versatility and multi-task capabilities of these models, the researchers were able to achieve strong performance across disease classification, visual question answering, and report generation.
While further research is needed to fully understand the strengths, limitations, and biases of this approach, the findings of this paper suggest that multi-modal LLMs could be valuable tools for advancing the field of medical imaging analysis and supporting clinicians in their diagnostic and decision-making processes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
M4CXR: Exploring Multi-task Potentials of Multi-modal Large Language Models for Chest X-ray Interpretation
Jonggwon Park, Soobum Kim, Byungmu Yoon, Jihun Hyun, Kyoyun Choi
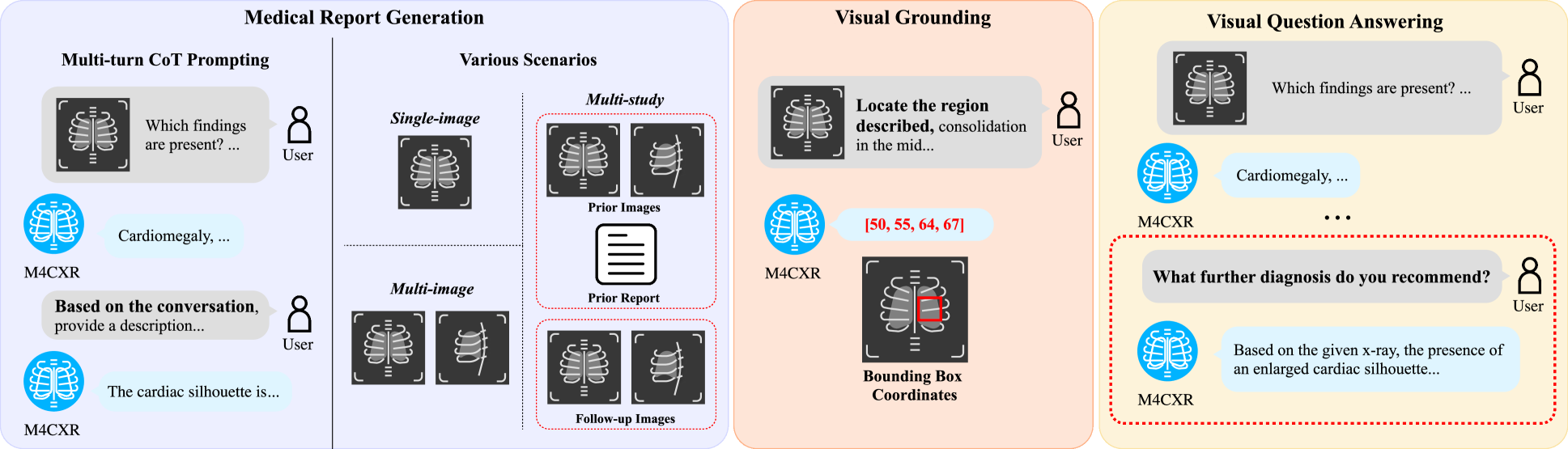
The rapid evolution of artificial intelligence, especially in large language models (LLMs), has significantly impacted various domains, including healthcare. In chest X-ray (CXR) analysis, previous studies have employed LLMs, but with limitations: either underutilizing the multi-tasking capabilities of LLMs or lacking clinical accuracy. This paper presents M4CXR, a multi-modal LLM designed to enhance CXR interpretation. The model is trained on a visual instruction-following dataset that integrates various task-specific datasets in a conversational format. As a result, the model supports multiple tasks such as medical report generation (MRG), visual grounding, and visual question answering (VQA). M4CXR achieves state-of-the-art clinical accuracy in MRG by employing a chain-of-thought prompting strategy, in which it identifies findings in CXR images and subsequently generates corresponding reports. The model is adaptable to various MRG scenarios depending on the available inputs, such as single-image, multi-image, and multi-study contexts. In addition to MRG, M4CXR performs visual grounding at a level comparable to specialized models and also demonstrates outstanding performance in VQA. Both quantitative and qualitative assessments reveal M4CXR's versatility in MRG, visual grounding, and VQA, while consistently maintaining clinical accuracy.
Read more8/30/2024
0
MedXChat: A Unified Multimodal Large Language Model Framework towards CXRs Understanding and Generation
Ling Yang, Zhanyu Wang, Zhenghao Chen, Xinyu Liang, Luping Zhou
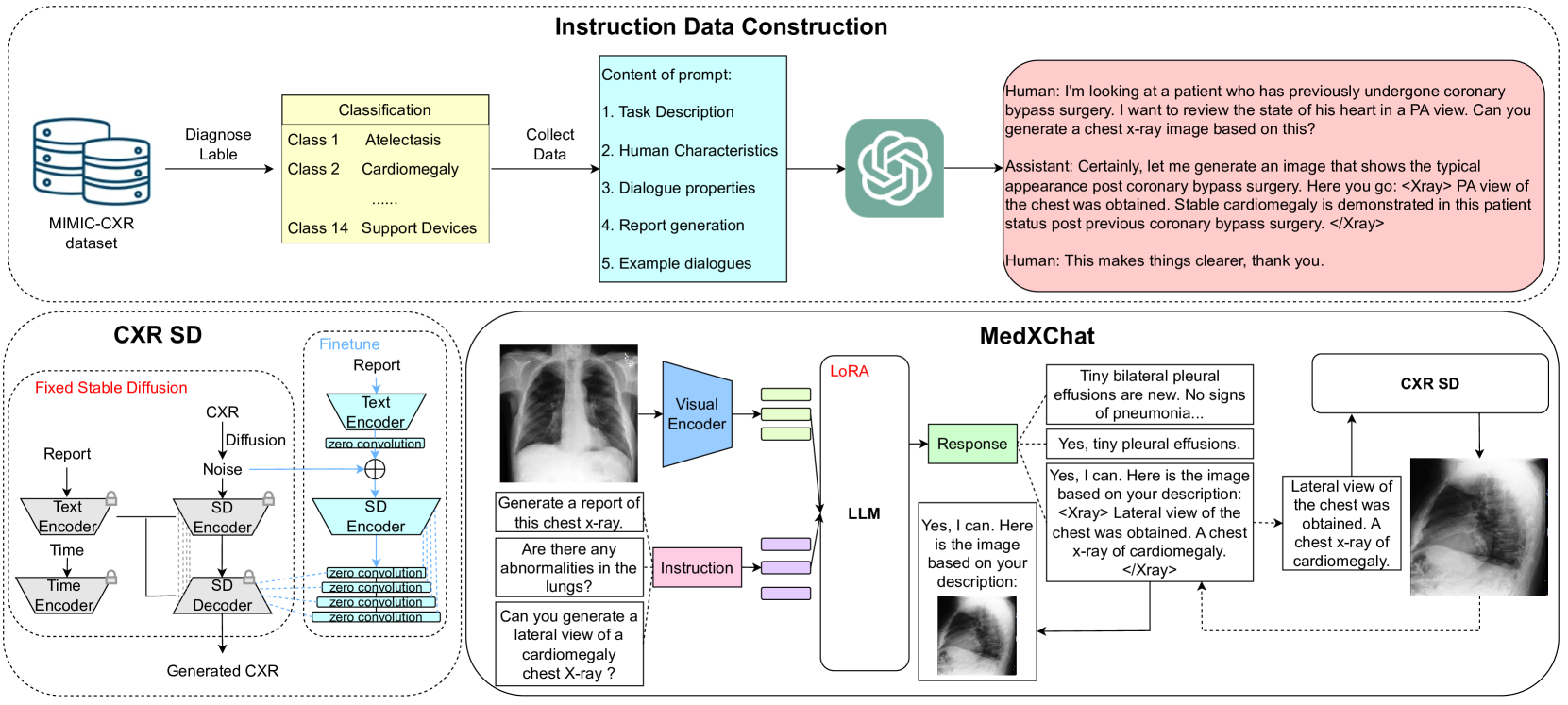
Multimodal Large Language Models (MLLMs) have shown success in various general image processing tasks, yet their application in medical imaging is nascent, lacking tailored models. This study investigates the potential of MLLMs in improving the understanding and generation of Chest X-Rays (CXRs). We introduce MedXChat, a unified framework facilitating seamless interactions between medical assistants and users for diverse CXR tasks, including text report generation, visual question-answering (VQA), and Text-to-CXR generation. Our MLLMs using natural language as the input breaks task boundaries, maximally simplifying medical professional training by allowing diverse tasks within a single environment. For CXR understanding, we leverage powerful off-the-shelf visual encoders (e.g., ViT) and LLMs (e.g., mPLUG-Owl) to convert medical imagery into language-like features, and subsequently fine-tune our large pre-trained models for medical applications using a visual adapter network and a delta-tuning approach. For CXR generation, we introduce an innovative synthesis approach that utilizes instruction-following capabilities within the Stable Diffusion (SD) architecture. This technique integrates smoothly with the existing model framework, requiring no extra parameters, thereby maintaining the SD's generative strength while also bestowing upon it the capacity to render fine-grained medical images with high fidelity. Through comprehensive experiments, our model demonstrates exceptional cross-task adaptability, displaying adeptness across all three defined tasks. Our MedXChat model and the instruction dataset utilized in this research will be made publicly available to encourage further exploration in the field.
Read more5/13/2024

0
Enhancing chest X-ray datasets with privacy-preserving large language models and multi-type annotations: a data-driven approach for improved classification
Ricardo Bigolin Lanfredi, Pritam Mukherjee, Ronald Summers
In chest X-ray (CXR) image analysis, rule-based systems are usually employed to extract labels from reports for dataset releases. However, there is still room for improvement in label quality. These labelers typically output only presence labels, sometimes with binary uncertainty indicators, which limits their usefulness. Supervised deep learning models have also been developed for report labeling but lack adaptability, similar to rule-based systems. In this work, we present MAPLEZ (Medical report Annotations with Privacy-preserving Large language model using Expeditious Zero shot answers), a novel approach leveraging a locally executable Large Language Model (LLM) to extract and enhance findings labels on CXR reports. MAPLEZ extracts not only binary labels indicating the presence or absence of a finding but also the location, severity, and radiologists' uncertainty about the finding. Over eight abnormalities from five test sets, we show that our method can extract these annotations with an increase of 3.6 percentage points (pp) in macro F1 score for categorical presence annotations and more than 20 pp increase in F1 score for the location annotations over competing labelers. Additionally, using the combination of improved annotations and multi-type annotations in classification supervision, we demonstrate substantial advancements in model quality, with an increase of 1.1 pp in AUROC over models trained with annotations from the best alternative approach. We share code and annotations.
Read more8/16/2024
0
CXR-Agent: Vision-language models for chest X-ray interpretation with uncertainty aware radiology reporting
Naman Sharma
Recently large vision-language models have shown potential when interpreting complex images and generating natural language descriptions using advanced reasoning. Medicine's inherently multimodal nature incorporating scans and text-based medical histories to write reports makes it conducive to benefit from these leaps in AI capabilities. We evaluate the publicly available, state of the art, foundational vision-language models for chest X-ray interpretation across several datasets and benchmarks. We use linear probes to evaluate the performance of various components including CheXagent's vision transformer and Q-former, which outperform the industry-standard Torch X-ray Vision models across many different datasets showing robust generalisation capabilities. Importantly, we find that vision-language models often hallucinate with confident language, which slows down clinical interpretation. Based on these findings, we develop an agent-based vision-language approach for report generation using CheXagent's linear probes and BioViL-T's phrase grounding tools to generate uncertainty-aware radiology reports with pathologies localised and described based on their likelihood. We thoroughly evaluate our vision-language agents using NLP metrics, chest X-ray benchmarks and clinical evaluations by developing an evaluation platform to perform a user study with respiratory specialists. Our results show considerable improvements in accuracy, interpretability and safety of the AI-generated reports. We stress the importance of analysing results for normal and abnormal scans separately. Finally, we emphasise the need for larger paired (scan and report) datasets alongside data augmentation to tackle overfitting seen in these large vision-language models.
Read more7/15/2024